适用于: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Synapse 管道中的 Azure Synapse 笔记本操作运行 Synapse 笔记本操作。 本文基于数据转换活动一文,它概述了数据转换和受支持的转换活动。
创建 Synapse 笔记本活动
可以直接从 Synapse 管道画布或笔记本编辑器创建 Synapse 笔记本活动。 Synapse 笔记本活动在 Synapse 笔记本中选择的 Spark 池上运行。
从管道画布添加 Synapse 笔记本活动
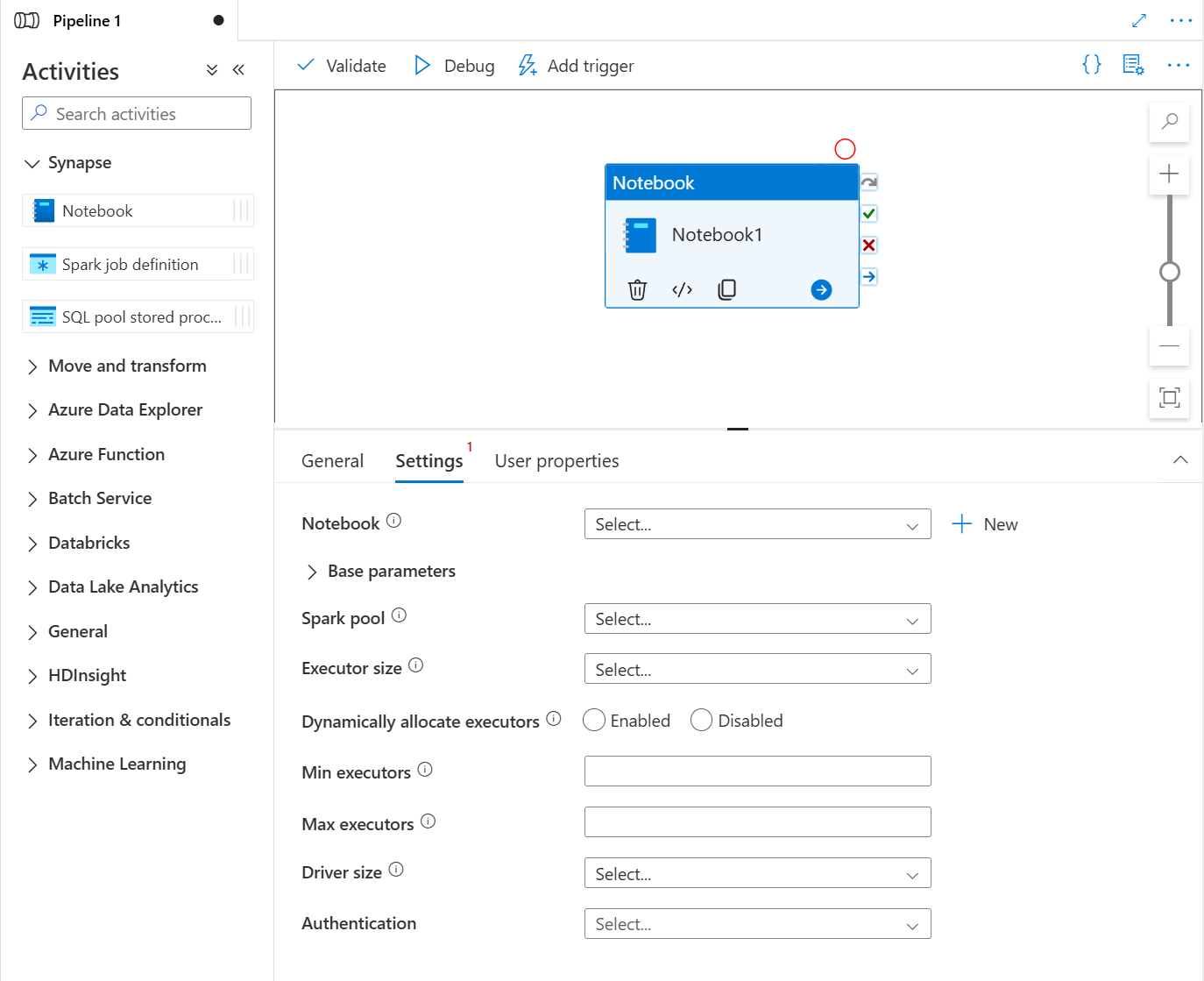
将“Synapse 笔记本”(位于“活动”下)拖放到 Synapse 管道画布上。 在 Synapse 笔记本活动框中选择,并在“设置”中为当前活动配置笔记本内容。 可以从当前工作区中选择现有笔记本或添加一个新笔记本。
如果从当前工作区中选择现有笔记本,则可以单击“打开”按钮直接打开笔记本的页面。
(可选)还可以在设置中重新配置 Spark 池\执行程序大小\动态分配执行程序\最小执行程序\Max 执行程序\驱动程序大小\身份验证。 需要注意的是,此处重新配置的设置会替换 Notebook 中配置会话的设置。 如果当前笔记本活动的设置中未配置任何内容,则会使用该笔记本中已配置的会话设置运行。
| 属性 | 描述 | 必需 |
|---|---|---|
| Spark 池 | 对 Spark 池的引用。 可以从列表中选择 Apache Spark 池。 如果此设置为空,它将在笔记本本身的 Spark 池中运行。 | 否 |
| 执行器大小 | 用于为会话在指定 Apache Spark 池中分配的执行程序的内核和内存数量。 | 否 |
| 动态分配执行程序 | 此设置映射到用于 Spark 应用程序执行工具分配的 Spark 配置中的动态分配属性。 | 否 |
| 最小执行器数 | 要在指定的 Spark 池中为作业分配的最小 executor 数。 | 否 |
| 最大执行程序数 | 要在作业的指定 Spark 池中分配的执行器的最大数量。 | 否 |
| 驱动程序大小 | 用于作业的指定 Apache Spark 池中驱动程序的核心数和内存量。 | 否 |
| 身份验证 | 可以使用系统分配的托管标识或用户分配的托管标识进行身份验证。 | 否 |
注意事项
并行的 Spark Notebook 在 Azure Synapse Pipelines 中以 FIFO 方式按顺序排队执行,队列中作业的顺序是按照时间先后排列,作业在队列中的过期时间为 3 天。请注意,笔记本的队列仅在 Synapse Pipeline 中工作。
将笔记本添加到 Synapse 管道
选择右上角的“添加到管道”按钮,将笔记本添加到现有管道或创建新管道。

传递参数
指定参数单元格
要参数化笔记本,请选择省略号(...)以访问单元格工具栏中的更多命令。 然后选择“切换参数单元格”,将该单元格指定为参数单元格。

在此单元格中定义参数。 它可以简单如下:
a = 1
b = 3
c = "Default Value"
你可以在其他单元格中引用这些参数,并在运行笔记本时使用在参数单元格中指定的默认值。
从管道运行此笔记本时,Azure Data Factory 会查找参数的单元格,并使用您提供的值作为在执行时传入的参数的默认值。 如果你从管道分配参数值,则执行引擎将使用输入参数在参数单元格下面添加新的单元格,以覆盖默认值。
从管道分配参数值
创建带有参数的笔记本后,您可以通过管道中的 Synapse 笔记本活动执行它。 将活动添加到管道画布后,将能够在“设置”选项卡的“基参数”部分设置参数值 。

提示
数据工厂不会自动填充参数。 需要手动添加它们。 请务必在笔记本中的参数单元格和管道中的基参数中使用完全相同的名称。
将参数添加到活动后,数据工厂会将你在活动中指定的值传递给笔记本,并且笔记本将使用这些新参数值运行,而不是使用你在参数单元格中指定的默认值。
读取 Synapse 笔记本单元输出值
可以按照以下步骤在接下来的操作中查看笔记本单元格的输出值:
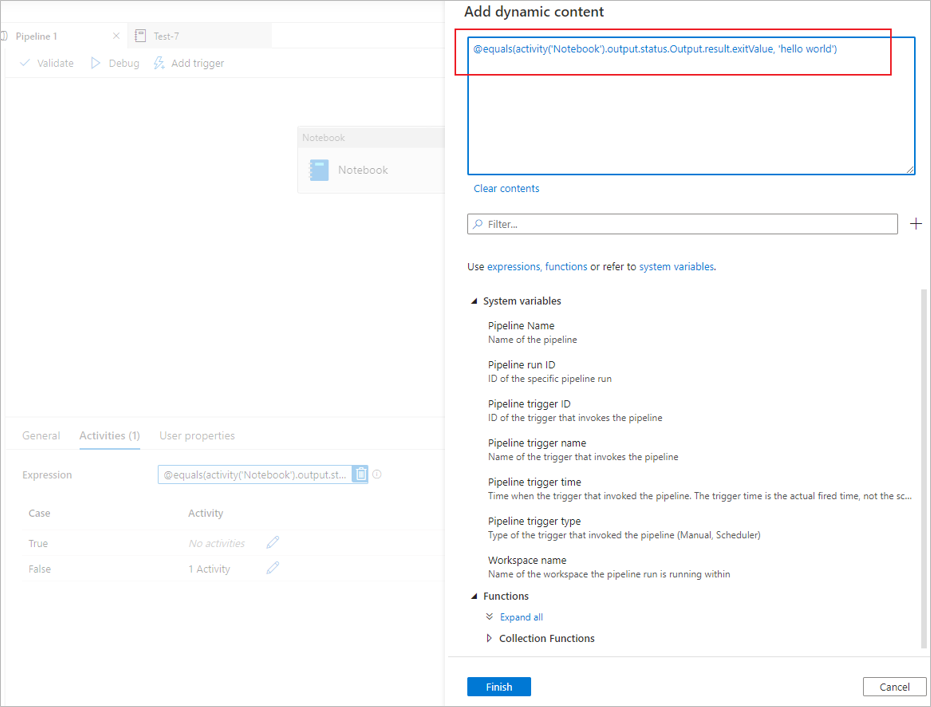
在 Synapse 笔记本活动中调用 mssparkutils.notebook.exit API,以返回要在活动输出中显示的值,例如:
mssparkutils.notebook.exit("hello world")保存笔记本内容并重新触发管道后,笔记本活动的输出将包含 exitValue,该值可供第 2 步中的以下活动使用。
从笔记本活动输出中读取 exitValue 属性。 下面是一个示例表达式,用于检查从笔记本活动输出中提取的 exitValue 是否等于“hello world”:

运行另一个 Synapse 笔记本
可以通过调用 %run magic 或 mssparkutils 笔记本实用程序,在 Synapse 笔记本活动中引用其他笔记本。 两者都支持嵌套函数调用。 根据你的方案,你应该考虑的这两种方法的主要区别是:
-
%run magic 将引用的笔记本中的所有单元格复制到 %run 单元格,并共享变量上下文。 当 notebook1 通过
%run notebook2引用 notebook2,以及 notebook2 调用 mssparkutils.notebook.exit 函数时,将停止 notebook1 中的单元格执行。 如果要“包含”笔记本文件,建议使用 %run magic。 -
mssparkutils 笔记本实用程序将引用的笔记本作为方法或函数进行调用。 变量上下文不共享。 当 notebook1 通过
mssparkutils.notebook.run("notebook2")引用 notebook2,以及 notebook2 调用 mssparkutils.notebook.exit 函数时,notebook1 中的单元格将继续执行。 如果要“导入”笔记本,建议使用 mssparkutils 笔记本实用程序。
请查看笔记本活动的运行历史记录
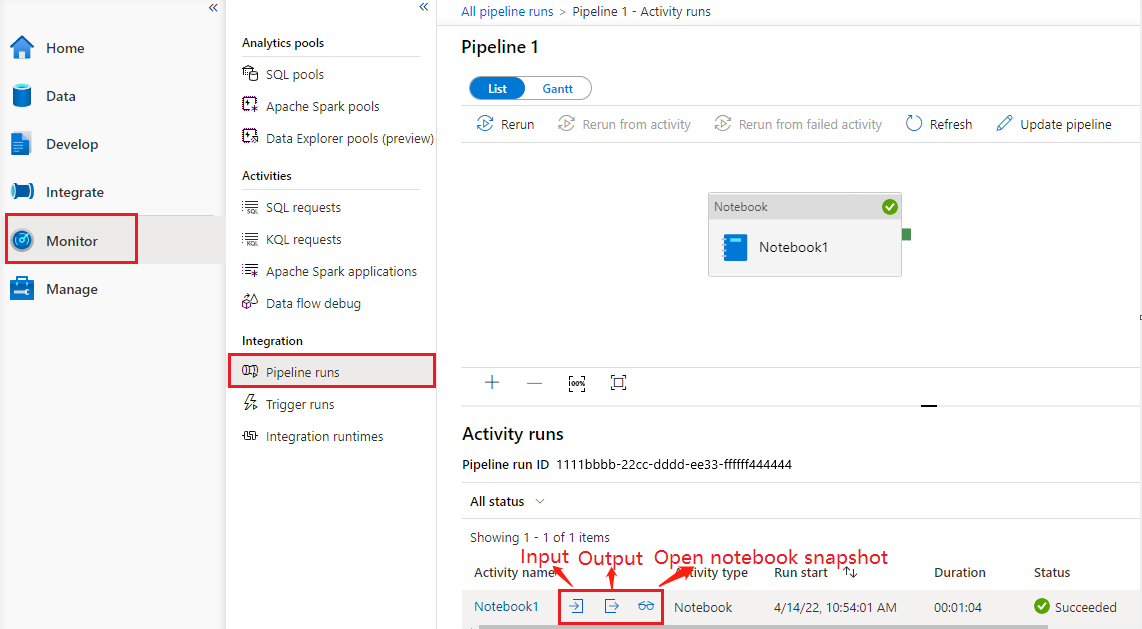
转到“监视”选项卡下的“管道运行”,您将看到已触发的管道。 打开包含笔记本活动的管道以查看运行历史。
可以通过单击“打开笔记本”按钮查看最新的笔记本运行快照,包括单元格输入和输出。
打开笔记本快照:
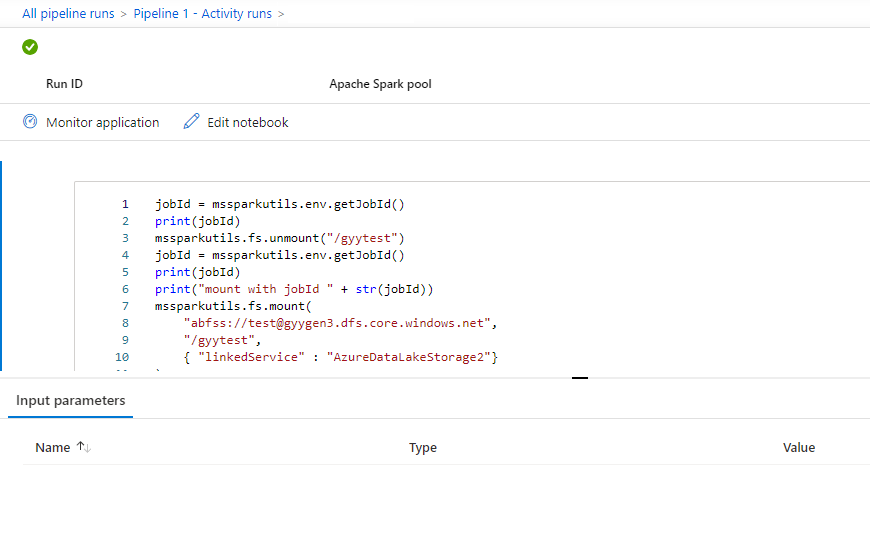
可以通过选择“输入”或“输出”按钮查看笔记本活动输入或输出 。 如果管道因用户错误而失败,请选择“输出”以检查“结果”字段,以查看详细的用户错误回溯信息。
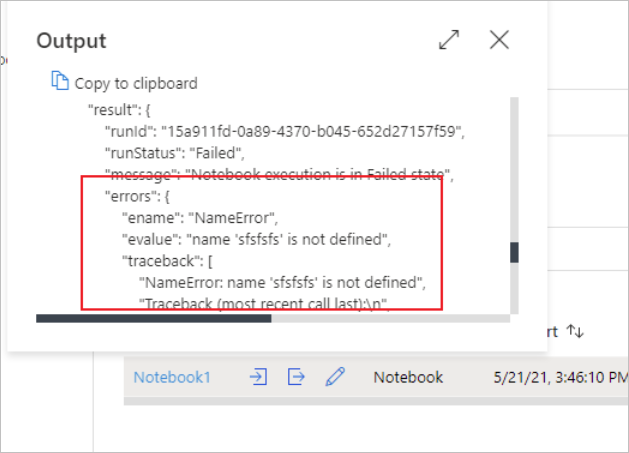
Synapse 笔记本活动描述
下面是 Synapse 笔记本活动的示例 JSON 定义:
{
"name": "parameter_test",
"type": "SynapseNotebook",
"dependsOn": [],
"policy": {
"timeout": "7.00:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"userProperties": [],
"typeProperties": {
"notebook": {
"referenceName": "parameter_test",
"type": "NotebookReference"
},
"parameters": {
"input": {
"value": {
"value": "@pipeline().parameters.input",
"type": "Expression"
}
}
}
}
}
Synapse 笔记本活动输出
下面是 Synapse 笔记本活动输出的示例 JSON:
{
{
"status": {
"Status": 1,
"Output": {
"status": <livySessionInfo>
},
"result": {
"runId": "<GUID>",
"runStatus": "Succeed",
"message": "Notebook execution is in Succeeded state",
"lastCheckedOn": "2021-03-23T00:40:10.6033333Z",
"errors": {
"ename": "",
"evalue": ""
},
"sessionId": 4,
"sparkpool": "sparkpool",
"snapshotUrl": "https://myworkspace.dev.azuresynapse.azure.cn/notebooksnapshot/{guid}",
"exitCode": "abc" // return value from user notebook via mssparkutils.notebook.exit("abc")
}
},
"Error": null,
"ExecutionDetails": {}
},
"effectiveIntegrationRuntime": "DefaultIntegrationRuntime (China North 3)",
"executionDuration": 234,
"durationInQueue": {
"integrationRuntimeQueue": 0
},
"billingReference": {
"activityType": "ExternalActivity",
"billableDuration": [
{
"meterType": "AzureIR",
"duration": 0.06666666666666667,
"unit": "Hours"
}
]
}
}
已知问题
如果在“管道笔记本”活动中参数化了笔记本名称,则无法在调试运行中引用处于未发布状态的笔记本版本。