本文介绍如何管理在 HDInsight 上运行的 Spark 应用程序的依赖项。 我们介绍了在 Spark 应用程序和群集范围内使用的 Scala 和 PySpark。
请根据你的用户案例,使用快速链接跳转到相应的部分:
- 使用 Jupyter Notebook 设置 Spark 作业 jar 依赖项
- 使用 Azure Toolkit for IntelliJ 设置 Spark 作业 jar 依赖项
- 为 Spark 群集配置 jar 依赖项
- 安全地管理 JAR 依赖项
- 使用 Jupyter Notebook 设置 Spark 作业 Python 包
- 安全地管理 Spark 群集的 Python 包
用于一个 Spark 作业的 Jar 库
使用 Jupyter Notebook
当 Spark 会话在用于 Scala 的 Spark 内核上的 Jupyter Notebook 中启动时,可以从以下位置配置包:
你可以使用 %%configure magic 将笔记本配置为使用外部包。 在使用外部包的笔记本中,确保在第一个代码单元中调用 %%configure magic。 这可以确保将内核配置为在启动会话之前使用该包。
重要
如果忘记了在第一个单元中配置内核,可以结合 -f 参数使用 %%configure,但这会重新启动会话,导致所有进度都会丢失。
Maven 存储库中的包或 Spark 包的示例
从 Maven 存储库中找到包后,收集 GroupId、ArtifactId 和 Version 的值。 串连这三个值并以冒号分隔 ( : )。
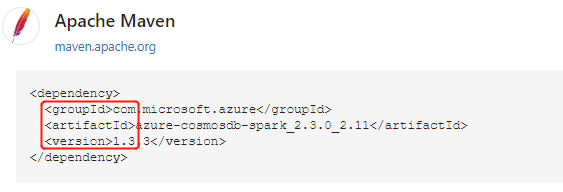
确保收集的值与群集相匹配。 在本例中,我们使用适用于 Scala 2.11 的 Spark Cosmos DB 连接器包,以及适用于 HDInsight 3.6 Spark 群集的 Spark 2.3。 如果不确定,请在 Spark 内核上运行代码单元中的 scala.util.Properties.versionString 以获取群集 Scala 版本。 运行 sc.version 以获取群集 Spark 版本。
%%configure { "conf": {"spark.jars.packages": "com.microsoft.azure:azure-cosmosdb-spark_2.3.0_2.11:1.3.3" }}
主存储上存储的 Jar 示例
将 URI 方案用于群集主存储上的 jar 文件。 对于 Azure 存储,此值为 wasb://;对于 Azure Data Lake Storage Gen2,此值为 abfs://。 如果为 Azure 存储或 Data Lake Storage Gen2 启用了安全传输,则 URI 是 wasbs:// 或 abfss://。 请参阅安全传输。
对多个 jar 文件使用以逗号分隔的 jar 路径的列表,允许 Glob。 jar 包括在驱动程序和执行程序类路径中。
%%configure { "conf": {"spark.jars": "wasb://mycontainer@mystorageaccount.blob.core.windows.net/libs/azure-cosmosdb-spark_2.3.0_2.11-1.3.3.jar" }}
配置外部包后,可以在代码单元中运行 import,以验证是否已正确放置包。
import com.microsoft.azure.cosmosdb.spark._
使用 Azure Toolkit for IntelliJ
Azure Toolkit for IntelliJ 插件提供将 Spark Scala 应用程序提交到 HDInsight 群集的 UI 体验。 它提供 Referenced Jars 和 Referenced Files 属性,用于在提交 Spark 应用程序时配置 jar 库路径。 如需更多详细信息,请参阅如何使用适用于 HDInsight 的 Azure Toolkit for IntelliJ 插件。
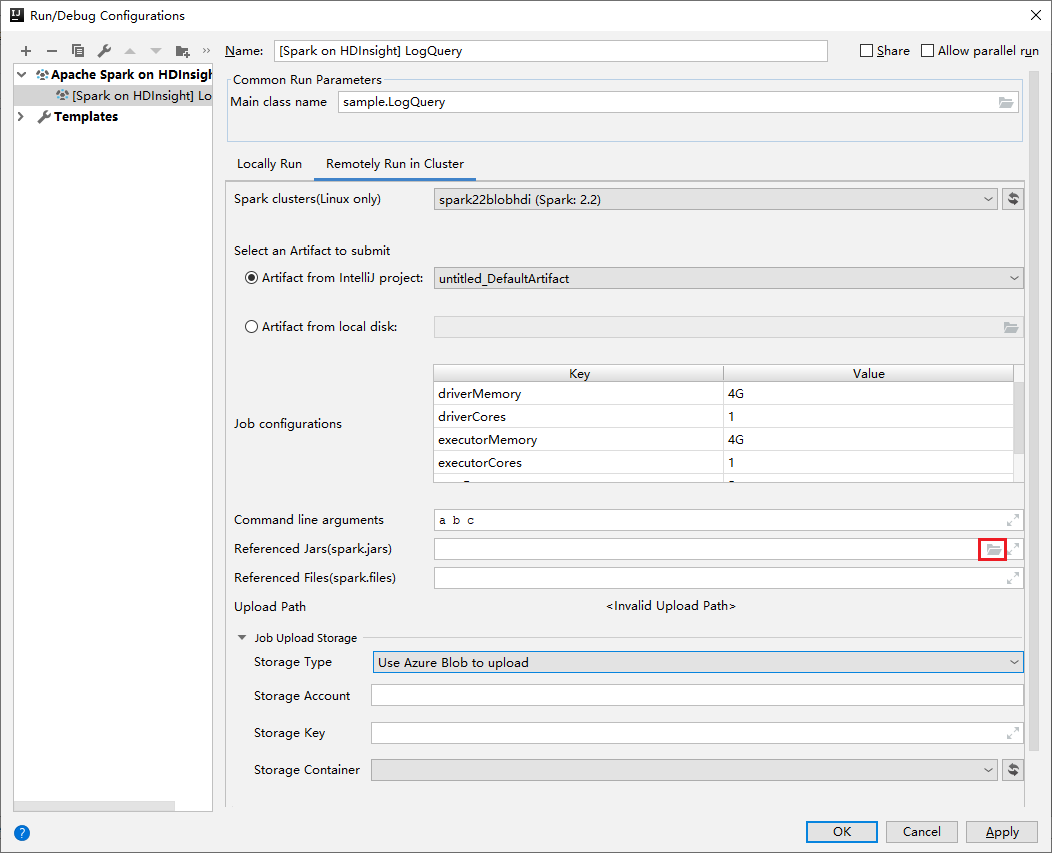
用于群集的 Jar 库
在某些情况下,你可能希望在群集级别配置 jar 依赖项,以便每个应用程序都默认设有相同的依赖项。 方法是将 jar 路径添加到 Spark 驱动程序和执行程序类路径。
运行示例脚本操作,以便将 jar 文件从主存储
wasb://mycontainer@mystorageaccount.blob.core.windows.net/libs/*复制到群集本地文件系统/usr/libs/sparklibs。 需要此步骤是因为 Linux 使用:来分隔类路径列表,而 HDInsight 仅支持wasb://之类的方案的存储路径。 如果将远程存储路径直接添加到类路径,则远程存储路径将无法正常发挥作用。sudo mkdir -p /usr/libs/sparklibs sudo hadoop fs -copyToLocal wasb://mycontainer@mystorageaccount.blob.core.windows.net/libs/*.* /usr/libs/sparklibs更改 Ambari 中的 Spark 服务配置,以更新类路径。 转到“Ambari”>“Spark”>“配置”>“自定义 Spark2-defaults”。 按下面所示添加属性。 如果要添加多个路径,请使用
:来分隔路径。 允许使用 Glob。spark.driver.extraClassPath=/usr/libs/sparklibs/* spark.executor.extraClassPath=/usr/libs/sparklibs/*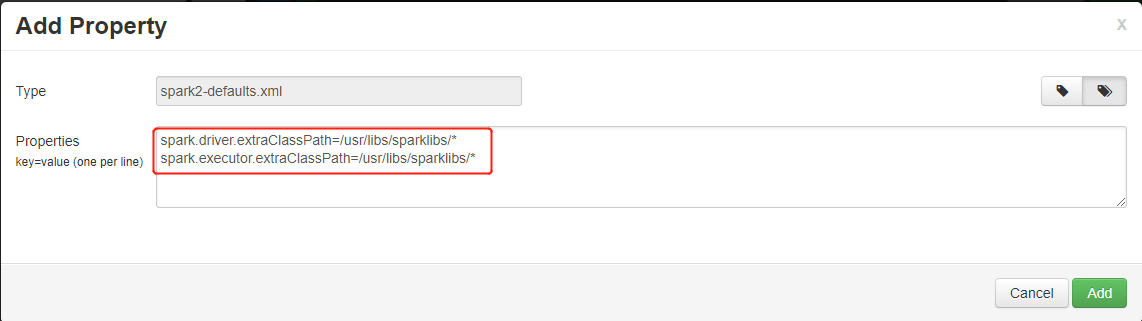 ult config" border="true":::
ult config" border="true":::保存更改的配置并重启受影响的服务。
 ted services" border="true":::
ted services" border="true":::
可以使用脚本操作自动执行这些步骤。 可以参考用于添加 Hive 自定义库的脚本操作。 更改 Spark 服务配置时,请确保使用 Ambari API,而不是直接修改配置文件。
安全地管理 JAR 依赖项
HDInsight 群集有内置的 jar 依赖项,对这些 jar 版本的更新会不时地发生。 为了避免内置 jar 与你带来的要引用的 jar 之间出现版本冲突,请考虑将应用程序依赖项改装。
用于一个 Spark 作业的 Python 包
使用 Jupyter Notebook
HDInsight Jupyter Notebook PySpark 内核不支持直接从 PyPi 或 Anaconda 包存储库安装 Python 包。 如果你有 .zip、.egg 或 .py 依赖项,并且想要为一个 Spark 会话引用它们,请执行以下步骤:
运行示例脚本操作,以便将
.zip、.egg或.py文件从主存储wasb://mycontainer@mystorageaccount.blob.core.windows.net/libs/*复制到群集本地文件系统/usr/libs/pylibs。 需要此步骤是因为 Linux 使用:来分隔搜索路径列表,而 HDInsight 仅支持wasb://之类的方案的存储路径。 当你使用sys.path.insert时,远程存储路径将无法正常发挥作用。sudo mkdir -p /usr/libs/pylibs sudo hadoop fs -copyToLocal wasb://mycontainer@mystorageaccount.blob.core.windows.net/libs/*.* /usr/libs/pylibs在笔记本中,使用 PySpark 内核运行代码单元中的以下代码:
import sys sys.path.insert(0, "/usr/libs/pylibs/pypackage.zip")运行
import以检查是否已成功包含包。
用于群集的 Python 包
可以使用 conda 命令通过脚本操作将 Python 包从 Anaconda 安装到群集。 安装的包位于群集级别,适用于所有应用程序。
HDInsight Spark 群集包含两个内置的 Python 安装:Anaconda Python 2.7 和 Anaconda Python 3.5。 若要详细了解服务的默认 Python 设置,以及如何在不中断群集运行的情况下安全地安装外部 Python 包,请查看安全地管理群集的 Python 依赖项中提供的更多详细信息。