Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Personally Identifiable Information (PII) detection is an Azure Language core capability that helps you identify, classify, and redact sensitive data across text, conversations, and native documents. Submit input text to the service and receive structured output with entity categories, confidence scores, and redacted results based on your API configuration. You can use this capability to implement privacy controls, reduce sensitive data exposure, and support compliance requirements in application and data-processing workflows.
PII documentation by feature type
PII capabilities are grouped by feature type. Each feature type maps to a specific input format and processing model.
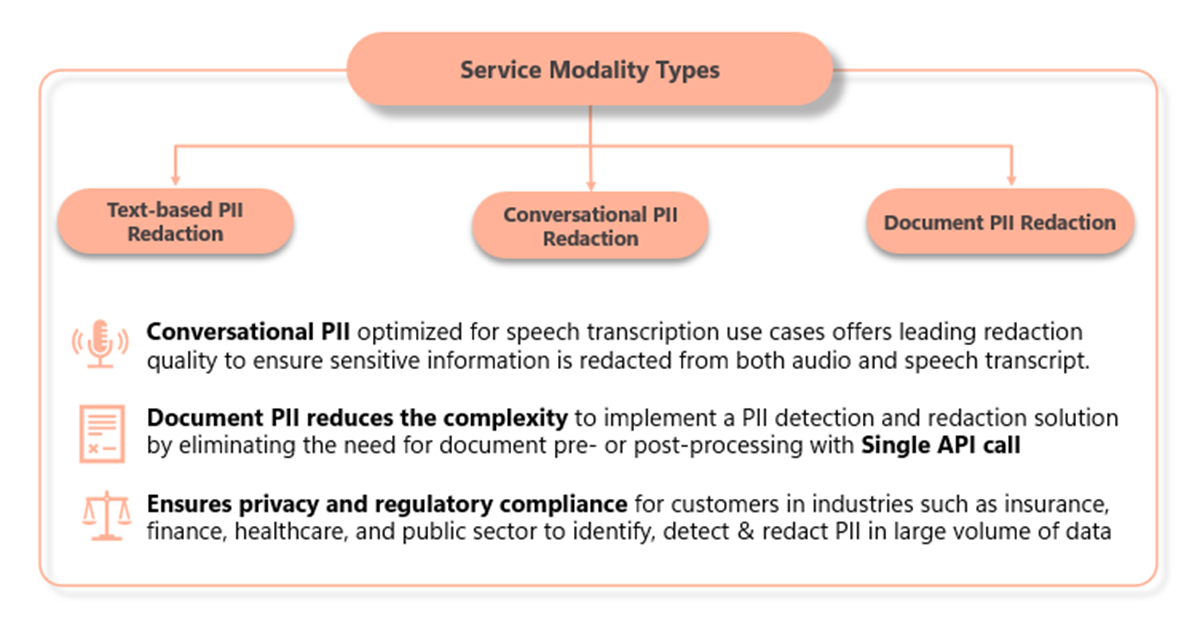
Choose the feature type that matches your data shape and runtime requirements.
Text PII
Text PII processes string-based payloads and returns synchronous detection and redaction results. Use this feature when your system handles request-time processing for messages, prompts, logs, and other text fields.
Use the following documentation to implement and tune Text PII workloads:
- Quickstart: Detect personally identifiable information (PII)
- Detect and redact Personally Identifiable Information in text
- Text PII recognized entity categories (extended format)
- Text PII recognized entity categories (list format)
Conversation PII
Conversation PII processes multi-turn exchanges and transcript-oriented payloads where turn boundaries and conversation context affect detection and masking behavior. Use this feature for asynchronous workloads that analyze chat and transcript structures.
Use the following documentation to implement Conversation PII job-based processing:
- Conversation PII overview
- Detect and redact Personally Identifiable Information in conversations
- Conversation PII recognized entity categories (extended format)
- Conversation PII recognized entity categories (list format)
Document-based PII
Document-based PII processes native files and returns redaction output that preserves document structure while also producing machine-readable metadata. Use this feature for asynchronous, storage-based pipelines that handle .pdf, .docx, and .txt inputs.
Use the following documentation to implement Document-based PII in native-file pipelines:
- Document-based PII overview
- Detect and redact Personally Identifiable Information in native documents
Choose the right PII feature
Use the following table to select the right experience before you start implementation:
| Feature type | Input | Best for | Key strength |
|---|---|---|---|
| Text PII | Raw text strings | Apps, prompts, logs, tickets | Broad language coverage and flexible redaction options |
| Conversation PII | Turn-based chat or transcript data | Contact centers, meetings, voice transcripts | Conversational context and transcript-aware output |
| Document-based PII | Native files (.pdf, .docx, .txt) |
Compliance workflows and document sharing | Redacted files with document fidelity and JSON metadata |
Get started
To use PII detection, you submit text for analysis and handle the API output in your application. Analysis is performed as-is, with no customization to the model used on your data. There are two ways to use PII detection:
| Development option | Description |
|---|---|
| Language studio | Language Studio is a web-based platform that lets you use personally identifying information detection with text examples with your own data when you sign up. For more information, see the Language Studio website or language studio quickstart. |
| REST API or Client library (Azure SDK) | Integrate PII detection into your applications using the REST API, or the client library available in various languages. |
Typical workflow
To use this feature, you submit data for analysis and handle the API output in your application. Analysis is performed as-is, with no added customization to the model used on your data.
Create an Azure Language resource, which grants you access to the features offered by Language. It generates a password (called a key) and an endpoint URL that you use to authenticate API requests.
Create a request using either the REST API or the client library for C#, Java, JavaScript, and Python. You can also send asynchronous calls with a batch request to combine API requests for multiple features into a single call.
Send the request containing your text data. Your key and endpoint are used for authentication.
Stream or store the response locally.
What differs across feature types?
All feature types use predefined entity categories and return confidence-scored detections. They differ mainly by input format and processing model:
- Text PII is optimized for synchronous string-based input.
- Conversation PII is optimized for turn-based transcript and chat structures.
- Document-based PII is asynchronous and optimized for processing native files while preserving document structure.
Note
Document-based PII focuses on native-file redaction workflows. Some text-only options are not available in every document API version.
GA and preview guidance
To avoid integration issues, use API versions and features that match your deployment target:
- Use generally available (GA) API versions for production workloads.
- Use preview API versions only when you need preview-only features.
- Avoid combining request payload examples from different API versions.
Each feature-specific how-to article identifies preview-only sections where applicable.
Input requirements and service limits
Use the following references to verify language coverage, service limits, and model-version behavior:
- Language support for text, document, and conversation PII
- Quotas and limits
- Model lifecycle and API version guidance
Reference documentation and code samples
As you use this feature in your applications, see the following reference documentation and samples for Azure Language:
| Development option / language | Reference documentation | Samples |
|---|---|---|
| REST API | REST API documentation | |
| C# | C# documentation | C# samples |
| Java | Java documentation | Java Samples |
| JavaScript | JavaScript documentation | JavaScript samples |
| Python | Python documentation | Python samples |
Common use cases
PII detection is useful when you need to apply privacy controls before storage, analytics, sharing, or downstream AI processing.
Typical examples include:
- Applying sensitivity labels based on detected PII categories.
- Redacting personal information in documents that are distributed more broadly.
- Masking personal identifiers in resume screening workflows to reduce bias risk.
- Replacing sensitive values with placeholders in machine learning training datasets.
- Redacting names and contact details in call center transcription workflows.
- Preparing datasets for analytics and data science without exposing customer data.
Next steps
Use the following references to continue implementation:
- Quickstart: Detect personally identifiable information (PII)
- Detect and redact Personally Identifiable Information in text
- Detect and redact Personally Identifiable Information in conversations
- Detect and redact Personally Identifiable Information in native documents
- Language support for text, document, and conversation PII
- Quotas and limits