Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
APPLIES TO:
![]() MongoDB
MongoDB
Important
Are you looking for a database solution for high-scale scenarios with a 99.999% availability service level agreement (SLA), instant autoscale, and automatic failover across multiple regions? Consider Azure Cosmos DB for NoSQL.
This migration guide is part of series on migrating databases from MongoDB to Azure Cosmos DB API for MongoDB. The critical migration steps are premigration, migration, and post-migration, as shown below.
Data migration using Azure Databricks
Azure Databricks is a platform as a service (PaaS) offering for Apache Spark. It offers a way to do offline migrations on a large-scale dataset. You can use Azure Databricks to do an offline migration of databases from MongoDB to Azure Cosmos DB for MongoDB.
In this tutorial, you'll learn how to:
Create an Azure Databricks workspace and compute
Add dependencies
Create and run Scala or Python notebook
Optimize the migration performance
Troubleshoot rate-limiting errors that could be observed during migration
Prerequisites
To complete this tutorial, you need to:
- Complete the premigration steps such as estimating throughput and choosing a shard key.
- Create an Azure Cosmos DB for MongoDB account.
Create an Azure Databricks workspace
You can follow instructions to create an Azure Databricks workspace. You can use the default compute available or create a new compute resource to run your notebook. Be sure to select a Databricks runtime that supports at least Spark 3.0.
Add dependencies
Add the MongoDB Connector for Spark library to your compute to connect to both native MongoDB and Azure Cosmos DB for MongoDB endpoints. In your compute, select Libraries > Install New > Maven, and then add org.mongodb.spark:mongo-spark-connector_2.12:3.0.1 Maven coordinates.
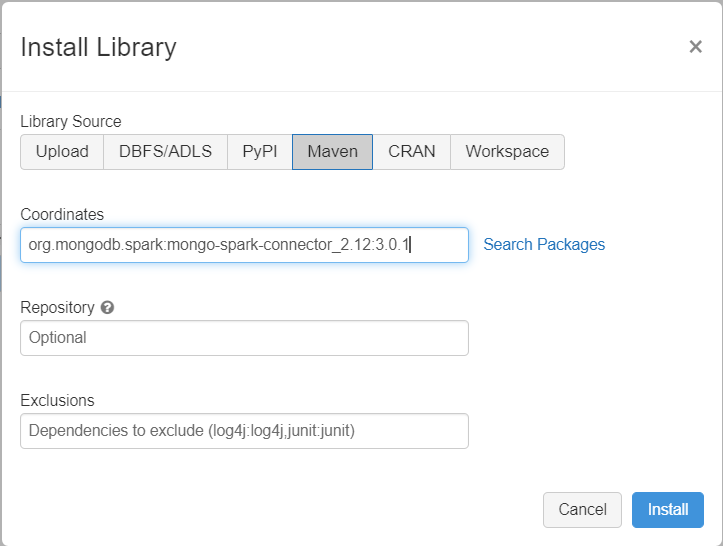
Select Install, and then restart the compute when installation is complete.
Note
Make sure that you restart the Databricks cluster after the MongoDB Connector for Spark library has been installed.
After that, you can create a Scala or Python notebook for migration.
Create Scala notebook for migration
Create a Scala Notebook in Databricks. Make sure to enter the right values for the variables before running the following code:
import com.mongodb.spark._
import com.mongodb.spark.config._
import org.apache.spark._
import org.apache.spark.sql._
var sourceConnectionString = "mongodb://<USERNAME>:<PASSWORD>@<HOST>:<PORT>/<AUTHDB>"
var sourceDb = "<DB NAME>"
var sourceCollection = "<COLLECTIONNAME>"
var targetConnectionString = "mongodb://<ACCOUNTNAME>:<PASSWORD>@<ACCOUNTNAME>.mongo.cosmos.azure.cn:10255/?ssl=true&replicaSet=globaldb&retrywrites=false&maxIdleTimeMS=120000&appName=@<ACCOUNTNAME>@"
var targetDb = "<DB NAME>"
var targetCollection = "<COLLECTIONNAME>"
val readConfig = ReadConfig(Map(
"spark.mongodb.input.uri" -> sourceConnectionString,
"spark.mongodb.input.database" -> sourceDb,
"spark.mongodb.input.collection" -> sourceCollection,
))
val writeConfig = WriteConfig(Map(
"spark.mongodb.output.uri" -> targetConnectionString,
"spark.mongodb.output.database" -> targetDb,
"spark.mongodb.output.collection" -> targetCollection,
"spark.mongodb.output.maxBatchSize" -> "8000"
))
val sparkSession = SparkSession
.builder()
.appName("Data transfer using spark")
.getOrCreate()
val customRdd = MongoSpark.load(sparkSession, readConfig)
MongoSpark.save(customRdd, writeConfig)
Create Python notebook for migration
Create a Python Notebook in Databricks. Make sure to enter the right values for the variables before running the following code:
from pyspark.sql import SparkSession
sourceConnectionString = "mongodb://<USERNAME>:<PASSWORD>@<HOST>:<PORT>/<AUTHDB>"
sourceDb = "<DB NAME>"
sourceCollection = "<COLLECTIONNAME>"
targetConnectionString = "mongodb://<ACCOUNTNAME>:<PASSWORD>@<ACCOUNTNAME>.mongo.cosmos.azure.cn:10255/?ssl=true&replicaSet=globaldb&retrywrites=false&maxIdleTimeMS=120000&appName=@<ACCOUNTNAME>@"
targetDb = "<DB NAME>"
targetCollection = "<COLLECTIONNAME>"
my_spark = SparkSession \
.builder \
.appName("myApp") \
.getOrCreate()
df = my_spark.read.format("com.mongodb.spark.sql.DefaultSource").option("uri", sourceConnectionString).option("database", sourceDb).option("collection", sourceCollection).load()
df.write.format("mongo").mode("append").option("uri", targetConnectionString).option("maxBatchSize",2500).option("database", targetDb).option("collection", targetCollection).save()
Optimize the migration performance
The migration performance can be adjusted through these configurations:
Number of workers and cores in the Spark cluster: More workers mean more compute shards to execute tasks.
maxBatchSize: The
maxBatchSizevalue controls the rate at which data is saved to the target Azure Cosmos DB collection. However, if the maxBatchSize is too high for the collection throughput, it can cause rate limiting errors.You would need to adjust the number of workers and maxBatchSize, depending on the number of executors in the Spark cluster, potentially the size (and that's why RU cost) of each document being written, and the target collection throughput limits.
Tip
maxBatchSize = Collection throughput / ( RU cost for 1 document * number of Spark workers * number of CPU cores per worker )
MongoDB Spark partitioner and partitionKey: The default partitioner used is MongoDefaultPartitioner and default partitionKey is _id. Partitioner can be changed by assigning value
MongoSamplePartitionerto the input configuration propertyspark.mongodb.input.partitioner. Similarly, partitionKey can be changed by assigning the appropriate field name to the input configuration propertyspark.mongodb.input.partitioner.partitionKey. Right partitionKey can help avoid data skew (large number of records being written for the same shard key value).Disable indexes during data transfer: For large amounts of data migration, consider disabling indexes, specially wildcard index on the target collection. Indexes increase the RU cost for writing each document. Freeing these RUs can help improve the data transfer rate. You can enable the indexes once the data has been migrated over.
Troubleshoot
Time-out Error (Error code 50)
You might see a 50 error code for operations against the Azure Cosmos DB for MongoDB database. The following scenarios can cause time-out errors:
- Throughput allocated to the database is low: Ensure that the target collection has sufficient throughput assigned to it.
- Excessive data skew with large data volume. If you have a large amount of data to migrate into a given table but have a significant skew in the data, you might still experience rate limiting even if you have several request units provisioned in your table. Request units are divided equally among physical partitions, and heavy data skew can cause a bottleneck of requests to a single shard. Data skew means large number of records for the same shard key value.
Rate limiting (Error code 16500)
You might see a 16500 error code for operations against the Azure Cosmos DB for MongoDB database. These are rate limiting errors and could be observed on older accounts or accounts where server-side retry feature is disabled.
- Enable Server-side retry: Enable the Server Side Retry (SSR) feature and let the server retry the rate limited operations automatically.
Post-migration optimization
After you migrate the data, you can connect to Azure Cosmos DB and manage the data. You can also follow other post-migration steps such as optimizing the indexing policy, update the default consistency level, or configure multiple-regional distribution for your Azure Cosmos DB account. For more information, see the Post-migration optimization article.
More resources
- Trying to do capacity planning for a migration to Azure Cosmos DB?
- If all you know is the number of vcores and servers in your existing database cluster, read about estimating request units using vCores or vCPUs
- If you know typical request rates for your current database workload, read about estimating request units using Azure Cosmos DB capacity planner