Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
The Azure Cosmos DB change feed lets you efficiently process large datasets with high write volumes. It provides an alternative to querying entire datasets to identify changes. This article explains common change feed design patterns, their tradeoffs, and limitations to help you build scalable solutions.
Scenarios
Azure Cosmos DB is ideal for IoT, gaming, retail, and operational logging applications. A common design pattern in these applications is to use changes to the data to trigger other actions. These actions include:
- Triggering a notification or a call to an API when an item is inserted, updated, or deleted.
- Real-time stream processing for IoT or analytics on operational data.
- Data movement such as synchronizing with a cache, a search engine, a data warehouse, or cold storage.
The change feed in Azure Cosmos DB lets you build efficient, scalable solutions for these patterns, as shown in the following image:
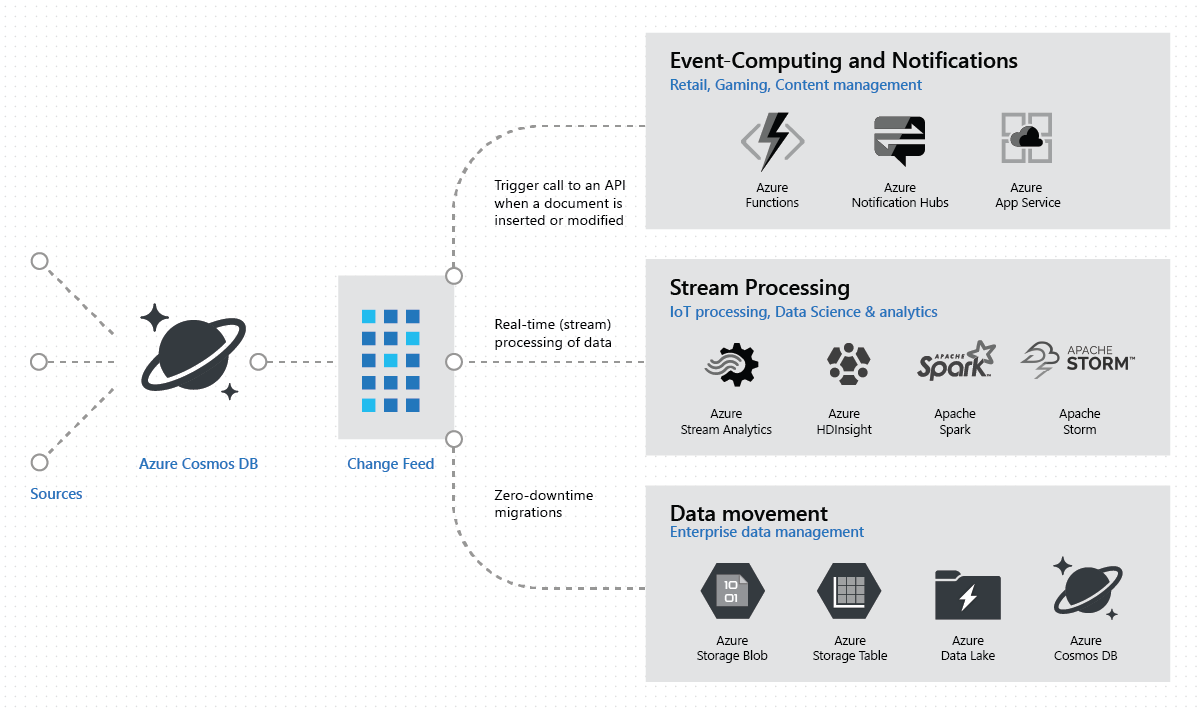
Event computing and notifications
The Azure Cosmos DB change feed simplifies scenarios that trigger a notification or call an API based on a specific event. Use the change feed processor to automatically poll your container for changes and call an external API for each write, update, or delete.
Selectively trigger a notification or call an API based on specific criteria. For example, if you're reading from the change feed using Azure Functions, add logic to the function to send a notification only if a condition is met. Although the Azure Function code executes for each change, the notification is sent only if the condition is met.
Real-time stream processing
The Azure Cosmos DB change feed lets you perform real-time stream processing for IoT or real-time analytics on operational data. For example, you receive and store event data from devices, sensors, infrastructure, and applications, and process these events in real time by using Spark. The following image shows how to implement a lambda architecture by using the Azure Cosmos DB change feed:
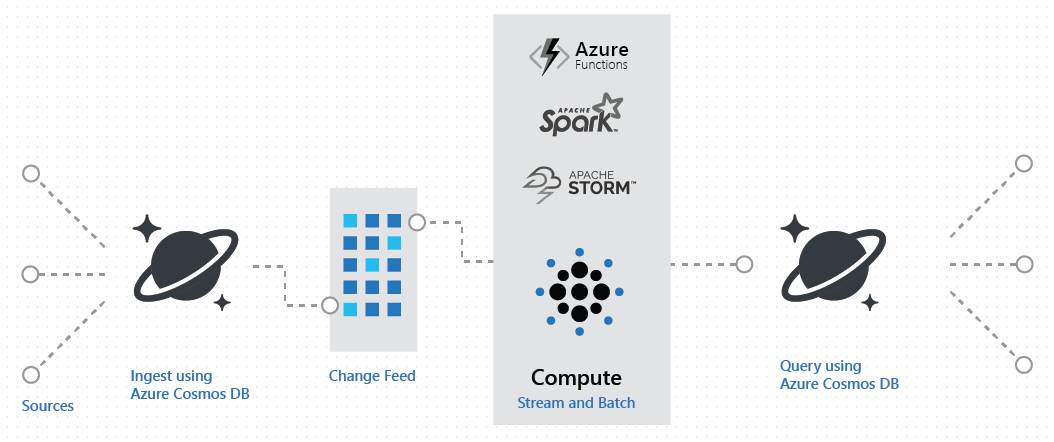
In many cases, stream processing implementations first receive a high volume of incoming data into a temporary message queue such as Azure Event Hubs or Apache Kafka. The change feed is a great alternative due to Azure Cosmos DB's ability to support a sustained high rate of data ingestion with guaranteed low read and write latency.
Data persistence
Data written to Azure Cosmos DB appears in the change feed. In latest version mode, the data remains in the change feed until deletion. Message queues usually have a maximum retention period. For example, Azure Event Hubs offers a maximum data retention of 90 days.
Query ability
In addition to reading from an Azure Cosmos DB container's change feed, run SQL queries on the data stored in Azure Cosmos DB. The change feed isn't a duplication of data that's already in the container, but rather, it's just a different mechanism of reading the data. Therefore, if you read data from the change feed, the data is always consistent with queries of the same Azure Cosmos DB container.
High availability
Azure Cosmos DB provides up to 99.999% read and write availability. Unlike many message queues, Azure Cosmos DB data can be multiple-regionally distributed and configured with an recovery time objective (RTO) of zero.
After processing items in the change feed, build a materialized view and persist aggregated values back in Azure Cosmos DB. For example, use Azure Cosmos DB's change feed to implement real-time leaderboards based on scores from completed games.
Data movement
Read from the change feed for real-time data movement.
For example, the change feed lets you perform the following tasks efficiently:
Update a cache, search index, or data warehouse with data stored in Azure Cosmos DB.
Perform zero-downtime migrations to another Azure Cosmos DB account or to another Azure Cosmos DB container that has a different logical partition key.
Implement application-level data tiering and archival. For example, store "hot data" in Azure Cosmos DB and age out "cold data" to other storage systems like Azure Blob Storage.
When you have to denormalize data across partitions and containers, you can read from your container's change feed as a source for this data replication. Real-time data replication with the change feed guarantees only eventual consistency. You can monitor how far the change feed processor lags behind in processing changes in your Azure Cosmos DB container.
Event sourcing
The event sourcing pattern uses an append-only store to record the full series of actions on data. The Azure Cosmos DB change feed is a great choice as a central data store in event sourcing architectures in which all data ingestion is modeled as writes (no updates or deletes). In this case, each write to Azure Cosmos DB is an "event," so there's a full record of past events in the change feed. Typical uses of the events published by the central event store are to maintain materialized views or to integrate with external systems. Because there isn't a time limit for retention in the change feed, you can replay all past events by reading from the beginning of your Azure Cosmos DB container's change feed.
Azure Cosmos DB is an excellent central append-only persistent data store in the event sourcing pattern because of its strengths in horizontal scalability and high availability. Additionally, the change feed processor offers an "at least once" guarantee, ensuring that you don't miss processing any events.
Current limitations
The change feed has multiple modes, each with important limitations you should understand. There are several areas to consider when you design an application that uses the change feed in either latest version mode or all versions and deletes mode.
Intermediate updates
In latest version mode, only the most recent change for a specific item is included in the change feed. When processing changes, you read the latest available item version. If there are multiple updates to the same item in a short period of time, it's possible to miss processing intermediate updates. To replay past individual updates to an item, model these updates as a series of writes or use all versions and deletes mode.
Deletes
The change feed latest version mode doesn't capture deletes. When you delete an item from your container, the item is removed from the change feed. The most common method to handle delete operations is to add a soft marker to the items being deleted. You can add a property called deleted and set it to true at the time of deletion. This document update shows up in the change feed. You can set a Time to Live (TTL) on this item so that it can be automatically deleted later.
Retention
The change feed in latest version mode has an unlimited retention. As long as an item exists in your container, it's available in the change feed.
Guaranteed order
All change feed modes have a guaranteed order within a partition key value, but not across partition key values. You should select a partition key that gives you a guarantee of meaningful order.
Consider a retail application that uses the event sourcing design pattern. In this application, different user actions are each "events," which are modeled as writes to Azure Cosmos DB. Imagine if some example events occurred in the following sequence:
- Customer adds Item A to their shopping cart.
- Customer adds Item B to their shopping cart.
- Customer removes Item A from their shopping cart.
- Customer checks out and shopping cart contents are shipped.
A materialized view of current shopping cart contents is maintained for each customer. This application must ensure that these events are processed in the order in which they occur. For example, if the cart checkout were to be processed before Item A's removal, it's likely that Item A shipped to the customer instead of the Item B the customer wanted instead. To ensure these four events are processed in order, they should fall within the same partition key value. If you select username (each customer has a unique username) as the partition key, you can guarantee that these events show up in the change feed in the same order in which they're written to Azure Cosmos DB.
Examples
Here are real-world change feed code examples for the latest version mode that go beyond the scope of the provided samples:
- Learn more in Introduction to the change feed.
- Learn more in IoT use case centered around the change feed.
- Learn more in Retail use case centered around the change feed.