Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Applies to: ✅ Azure Data Explorer ✅ Azure Monitor ✅ Microsoft Sentinel
Graph semantics enables you to model and query data as interconnected networks. A graph consists of nodes (entities) and edges (relationships) that connect them. Both nodes and edges can contain properties, creating a rich data model for complex relationships.
Graphs excel at representing complex data with many-to-many relationships, hierarchical structures, or networked connections—such as social networks, recommendation systems, connected assets, and knowledge graphs. Unlike relational databases that require indexes and joins to connect data across tables, graphs use direct adjacency between nodes, enabling fast and intuitive traversal of relationships.
The following graph illustrates a cybersecurity attack path scenario. Nodes represent entities such as external sources, users, and critical assets, while edges represent actions or relationships that form a potential attack sequence.

Graph queries leverage graph structure to perform sophisticated operations such as finding paths, patterns, shortest distances, communities, and centrality measures. These capabilities make graphs powerful for modeling relationships, interactions, dependencies, and flows across domains—including social networks, supply chains, IoT device networks, digital twins, recommendation systems, and organizational structures.
The following graph shows a supply chain scenario where nodes represent suppliers, manufacturers, and distributors, and edges represent supply relationships. This example demonstrates how graphs model flows and dependencies across different business contexts.

Why use graph semantics?
Graph capabilities offer significant advantages by leveraging existing data investments while adding sophisticated relationship modeling:
- No data migration required - Build graph models directly from current data without duplication.
- Cost-effective solution - Eliminates the complexity and expense of dedicated graph databases.
- Temporal analysis support - As a time-series database, you can naturally analyze how graphs evolve over time.
- Event-based modeling - Models graphs as sequences of relationship events, aligning with strong event processing capabilities.
- Seamless KQL integration - Graph operators work alongside all existing KQL capabilities with full IntelliSense support.
This approach delivers enterprise-grade relationship modeling while maintaining performance, scale, and a familiar interface. Organizations can analyze complex interconnected data across domains—from supply chains and organizational hierarchies to IoT device networks and social relationships—without extra infrastructure investments.
Transient graph creation approach
Transient graphs are created dynamically using the make-graph operator. These graphs exist in memory during query execution and are automatically discarded when the query completes.
Key characteristics
- Dynamic creation - Built from tabular data using KQL queries with the entire structure residing in memory
- Immediate availability - No preprocessing or setup requirements
- Memory constraints - Graph size is limited by available memory on cluster nodes
- Performance factors - Graph topology and property sizes determine memory requirements
This approach is optimal for smaller to medium-sized datasets where immediate analysis is needed.
Use cases for transient graphs
Transient graphs excel in several scenarios:
- Ad hoc analysis - One-time investigations requiring quick pattern examination
- Exploratory data analysis - Testing hypotheses and validating analytical approaches
- Small to medium datasets - Real-time analysis of recent events or focused data subsets
- Rapid prototyping - Testing graph patterns before implementing persistent models
- Dynamic data analysis - Frequently changing data that doesn't justify persistent storage
Common applications include real-time IoT monitoring, supply chain relationship analysis, customer journey mapping, and any scenario requiring immediate visualization of entity relationships.
Persistent graph creation approach
Persistent graphs use graph models and graph snapshots to provide robust solutions for large-scale, complex graphs representing organizational networks, supply chains, IoT ecosystems, digital twins, and other interconnected data domains.
Key characteristics for persistent graphs
- Persistent storage - Graph models and snapshots are stored in database metadata for durability and consistency
- Scalability - Handle graphs exceeding memory limitations with enterprise-scale analysis capabilities
- Reusability - Multiple users can query the same structure without rebuilding, enabling collaborative analysis
- Performance optimization - Eliminate graph construction latency for repeated queries
- Version control - Multiple snapshots represent graphs at different time points for historical analysis
- Schema support - Structured definitions for different entity types and their properties
The schema capability supports both static labels (predefined in the graph model) and dynamic labels (generated at runtime from data), providing flexibility for complex environments with diverse entity types.
Use cases for persistent graphs
Persistent graphs are essential for:
- Enterprise analytics - Continuous monitoring workflows across complex networks
- Large-scale data analysis - Enterprise-scale graphs with millions of nodes and relationships
- Collaborative analysis - Multiple teams working with shared graph structures
- Production workflows - Automated systems requiring consistent graph access
- Historical comparison - Time-based analysis of graph evolution and changes
Example: Digital Twin Persistent Graph
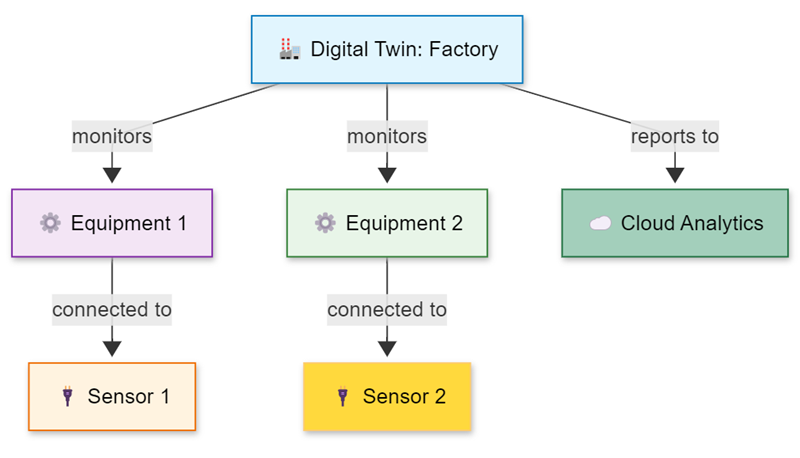
In digital twin and IoT scenarios, persistent graphs support regular analysis of device relationships, equipment dependencies, and system evolution over time. Historical analysis allows comparing system states across different periods, tracking the evolution of assets, and conducting long-term trend analysis.
Example: IoT and digital twin persistent graph
IoT and digital twin applications benefit significantly from persistent graphs when modeling complex relationships between physical devices and their virtual representations across distributed systems. These graphs enable organizations to:
- Create comprehensive models of IoT deployments and connected assets
- Support real-time monitoring, predictive maintenance, and performance optimization
- Analyze equipment dependencies and identify potential failure points
- Optimize sensor placements through physical and logical topology understanding
- Track device configurations, communications, and performance characteristics over time
- Detect communication pattern anomalies and visualize smart environment evolution
- Simulate operating conditions before implementing physical infrastructure changes
This persistent approach proves invaluable for managing complex IoT ecosystems at scale.
Graph querying capabilities
Once a graph is established (through make-graph or from a snapshot), you can leverage the full suite of KQL graph operators for comprehensive analysis:
Core operators:
graph-match- Enables sophisticated pattern matching and traversal operations for identifying complex relationship sequencesgraph-shortest-paths- Finds optimal paths between entities, helping prioritize connections and identify critical relationshipsgraph-to-table- Converts graph analysis results to tabular format for integration with existing systems
Advanced analysis capabilities:
- Time-based analysis - Examine how relationships and patterns evolve over time
- Geospatial integration - Combine graph data with location-based intelligence for geographic pattern analysis
- Machine learning integration - Apply algorithms for entity clustering, pattern classification, and anomaly detection
These capabilities support diverse use cases including customer journey analysis, product recommendation systems, IoT networks, digital twins, and knowledge graphs.
Choosing the right approach
The following decision tree helps you select the most appropriate graph creation approach based on your specific requirements and constraints.
Decision Tree: Transient vs Persistent Graphs
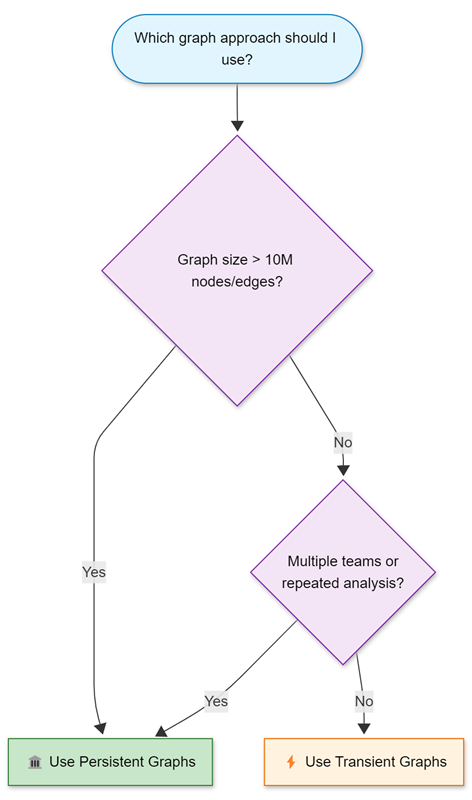
When to use transient graphs
Choose transient graphs for:
- Graph size under 10 million nodes and edges (for optimal performance)
- Single user or small team analysis with minimal collaboration requirements
- One-time or exploratory investigations where immediate results are needed
- Real-time data analysis requiring current state information
- Rapid prototyping and testing of graph patterns and query logic
While transient graphs can handle larger datasets, query execution time increases as the graph must be reconstructed for every query. Consider this performance trade-off when working with larger datasets.
When to use persistent graphs
Choose persistent graphs for:
- Graph size exceeding 10 million nodes and edges where distributed storage is beneficial
- Multiple teams requiring shared access for collaborative analysis
- Repeated analysis on stable datasets where construction latency impacts productivity
- Production workflow integration requiring consistent, reliable graph access
- Historical comparison requirements for tracking changes over time
- Memory capacity limitations affecting query performance
- Collaborative investigation workflows across teams and time zones
Persistent graphs are essential when working with enterprise-scale data or when memory limitations affect performance.
Performance considerations
Memory usage
- Transient graphs - Limited by single cluster node memory, constraining use to datasets within available RAM
- Persistent graphs - Leverage distributed storage and optimized access patterns for enterprise-scale data
Query latency
- Transient graphs - Include construction time in each query, with delays increasing for large datasets or external data sources
- Persistent graphs - Eliminate construction latency through prebuilt snapshots, enabling rapid analysis
External data source dependencies, such as cross cluster queries or external tables to SQL and CosmosDB, can significantly affect transient graph construction time because each query must wait for external responses.
Data freshness
- Transient graphs - Always reflect current data state, ideal for real-time analysis
- Persistent graphs - Reflect data at snapshot creation time, providing consistency for collaborative analysis but requiring periodic refreshes
Integration with KQL ecosystem
Graph semantics integrate seamlessly with KQL's broader capabilities:
- Time-series analysis - Track relationship evolution over time
- Geospatial functions - Analyze location-based patterns and geographic anomalies
- Machine learning operators - Detect patterns, classify behaviors, and identify anomalies
- Scalar and tabular operators - Enable complex transformations, aggregations, and data enrichment
This integration enables sophisticated workflows including supply chain evolution tracking, geographical asset distribution analysis, community detection through clustering algorithms, and correlation of graph insights with traditional log analysis and external intelligence.