Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Azure Data Lake Storage Gen2 is a set of capabilities dedicated to big data analytics, built into Azure Blob storage. It allows you to interface with your data using both file system and object storage paradigms.
Azure Data Factory (ADF) is a fully managed cloud-based data integration service. You can use the service to populate the lake with data from a rich set of on-premises and cloud-based data stores and save time when building your analytics solutions. For a detailed list of supported connectors, see the table of Supported data stores.
Azure Data Factory offers a scale-out, managed data movement solution. Due to the scale-out architecture of ADF, it can ingest data at a high throughput. For details, see Copy activity performance.
This article shows you how to use the Data Factory Copy Data tool to load data from Amazon Web Services S3 service into Azure Data Lake Storage Gen2. You can follow similar steps to copy data from other types of data stores.
Prerequisites
- Azure subscription: If you don't have an Azure subscription, create a trial account before you begin.
- Azure Storage account with Data Lake Storage Gen2 enabled: If you don't have a Storage account, create an account.
- AWS account with an S3 bucket that contains data: This article shows how to copy data from Amazon S3. You can use other data stores by following similar steps.
Create a data factory
If you have not created your data factory yet, follow the steps in Quickstart: Create a data factory by using the Azure portal and Azure Data Factory Studio to create one. After creating it, browse to the data factory in the Azure portal.
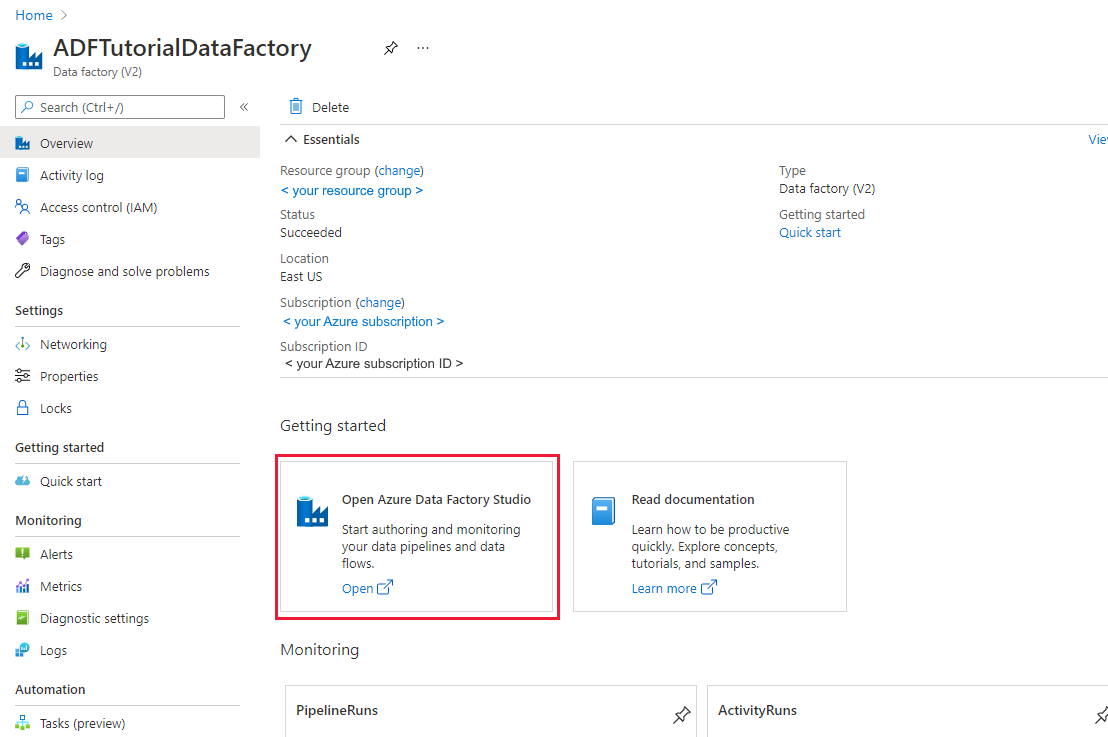
Select Open on the Open Azure Data Factory Studio tile to launch the Data Integration application in a separate tab.
Load data into Azure Data Lake Storage Gen2
In the home page of Azure Data Factory, select the Ingest tile to launch the Copy Data tool.
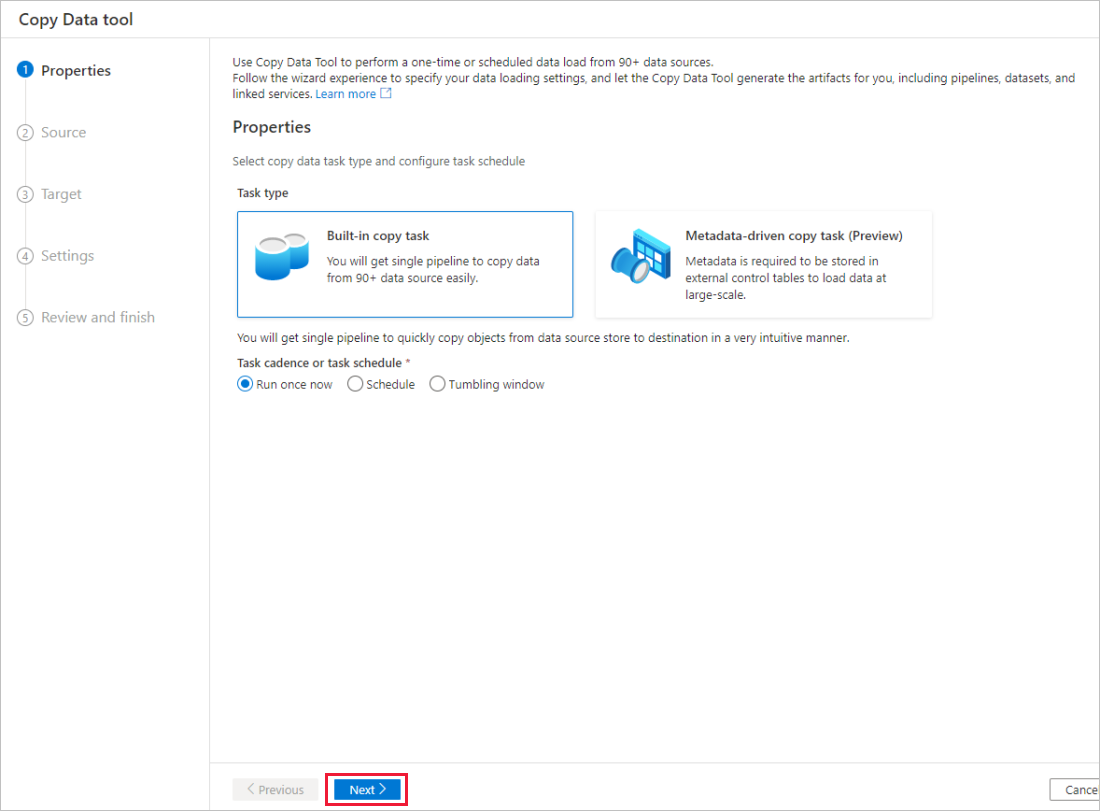
In the Properties page, choose Built-in copy task under Task type, and choose Run once now under Task cadence or task schedule, then select Next.
In the Source data store page, complete the following steps:
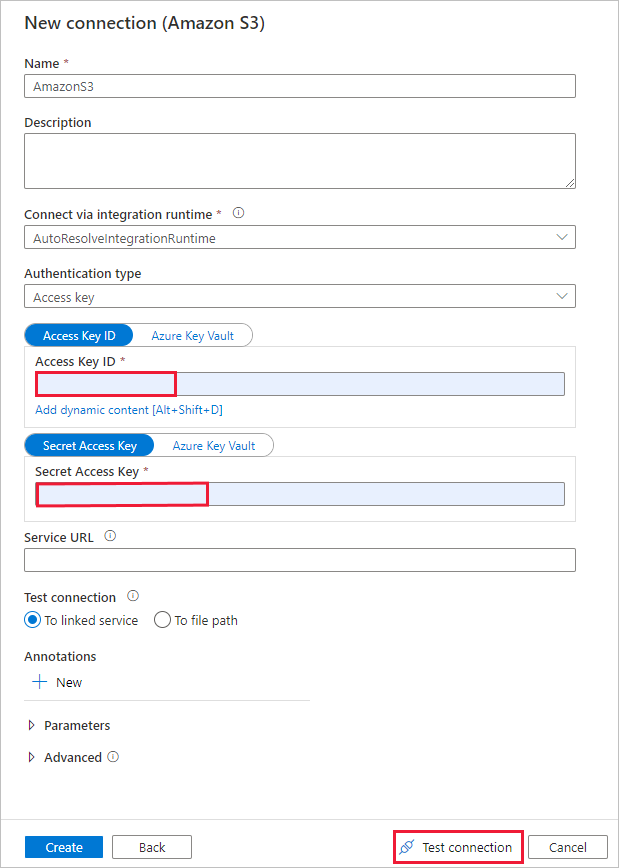
Select + New connection. Select Amazon S3 from the connector gallery, and select Continue.

In the New connection (Amazon S3) page, do the following steps:
- Specify the Access Key ID value.
- Specify the Secret Access Key value.
- Select Test connection to validate the settings, then select Create.
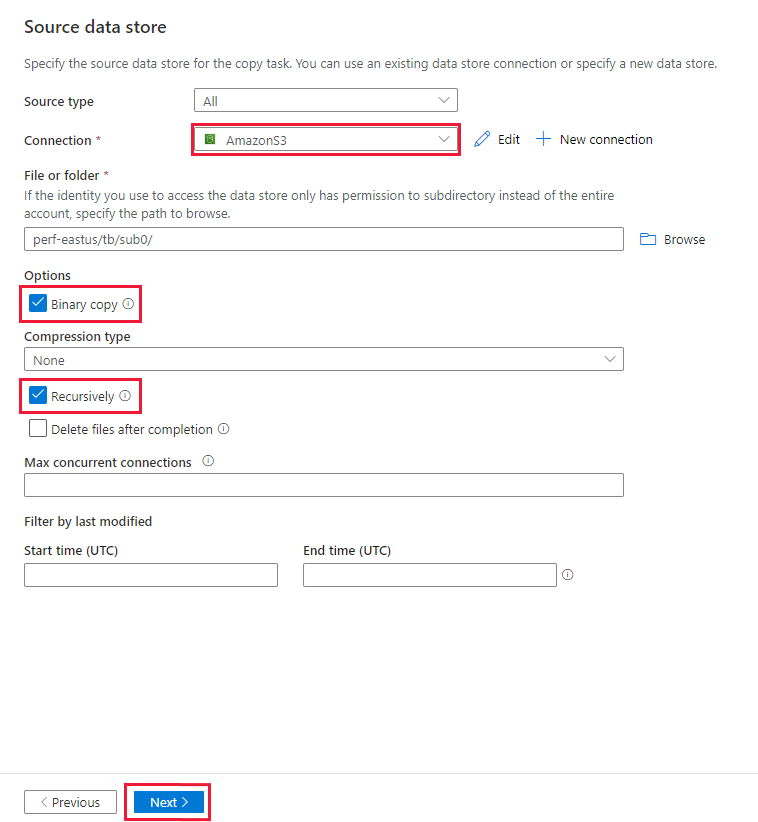
In the Source data store page, ensure that the newly created Amazon S3 connection is selected in the Connection block.
In the File or folder section, browse to the folder and file that you want to copy over. Select the folder/file, and then select OK.
Specify the copy behavior by checking the Recursively and Binary copy options. Select Next.
In the Destination data store page, complete the following steps.
Select + New connection, and then select Azure Data Lake Storage Gen2, and select Continue.
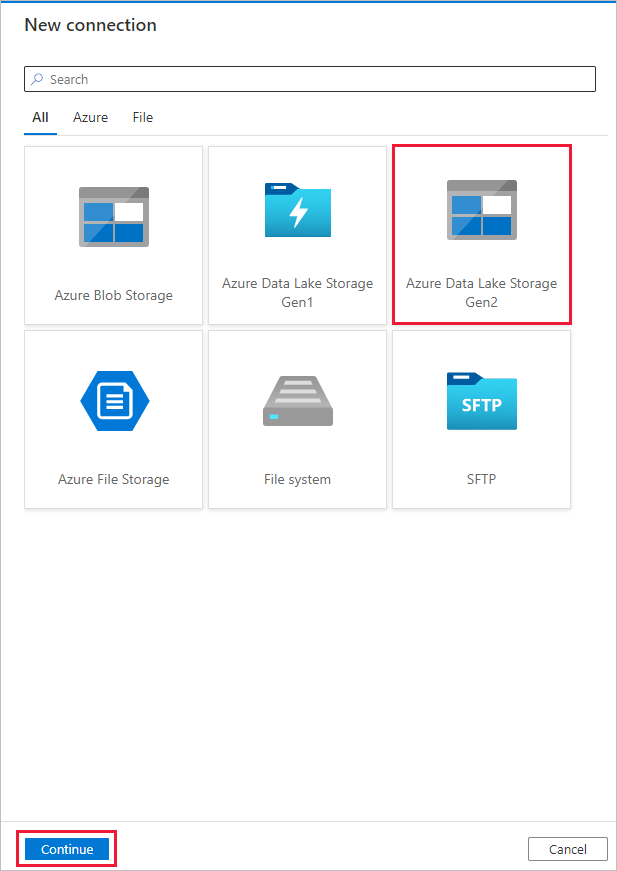
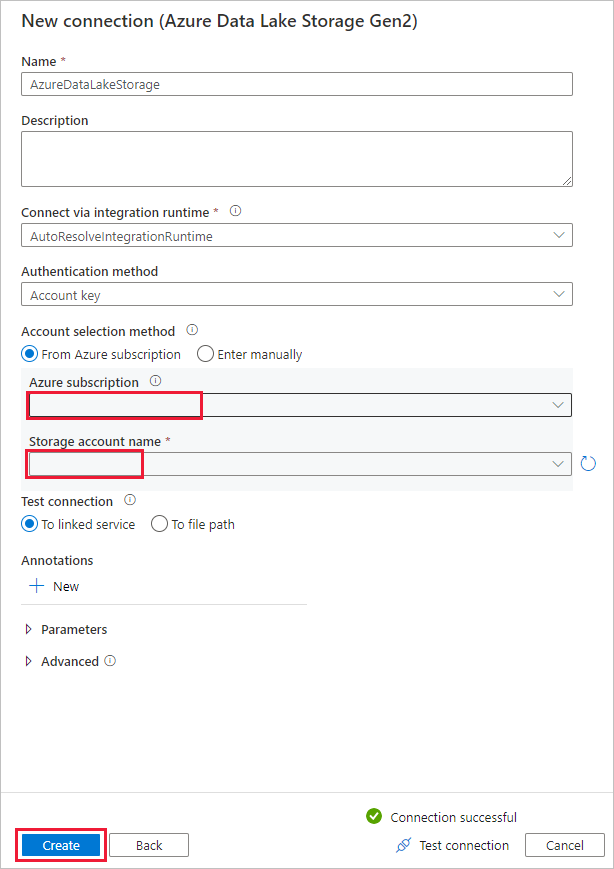
In the New connection (Azure Data Lake Storage Gen2) page, select your Data Lake Storage Gen2 capable account from the "Storage account name" drop-down list, and select Create to create the connection.
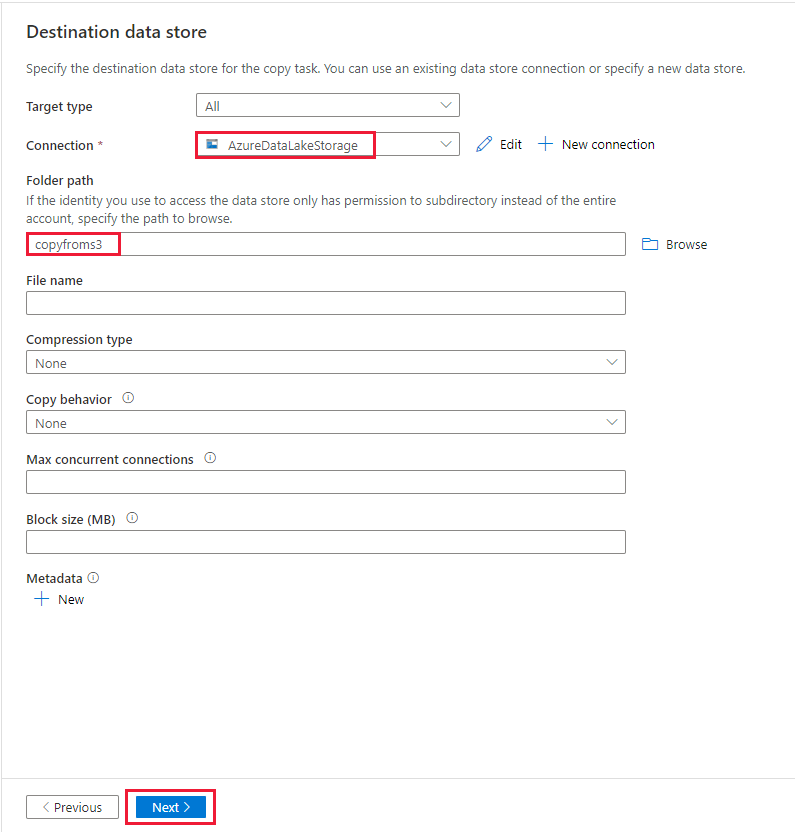
In the Destination data store page, select the newly created connection in the Connection block. Then under Folder path, enter copyfroms3 as the output folder name, and select Next. ADF will create the corresponding ADLS Gen2 file system and subfolders during copy if it doesn't exist.
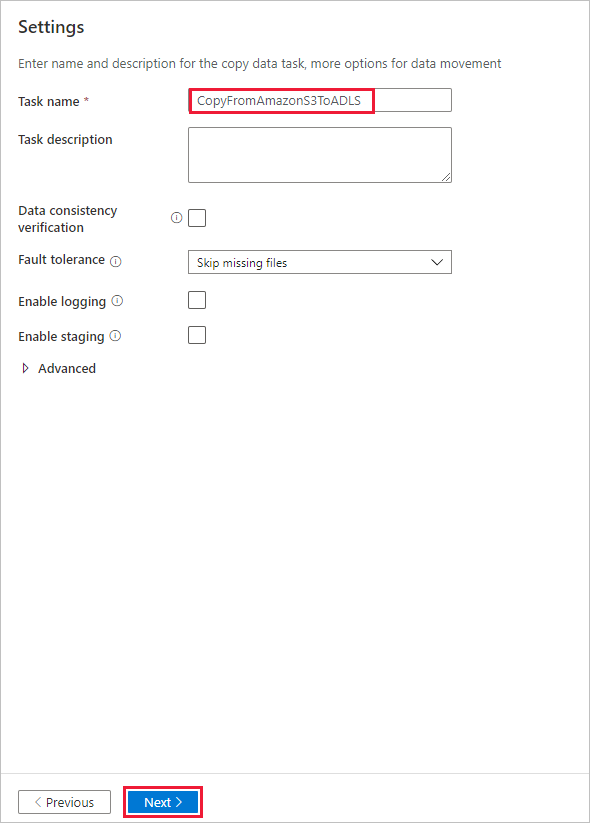
In the Settings page, specify CopyFromAmazonS3ToADLS for the Task name field, and select Next to use the default settings.
In the Summary page, review the settings, and select Next.
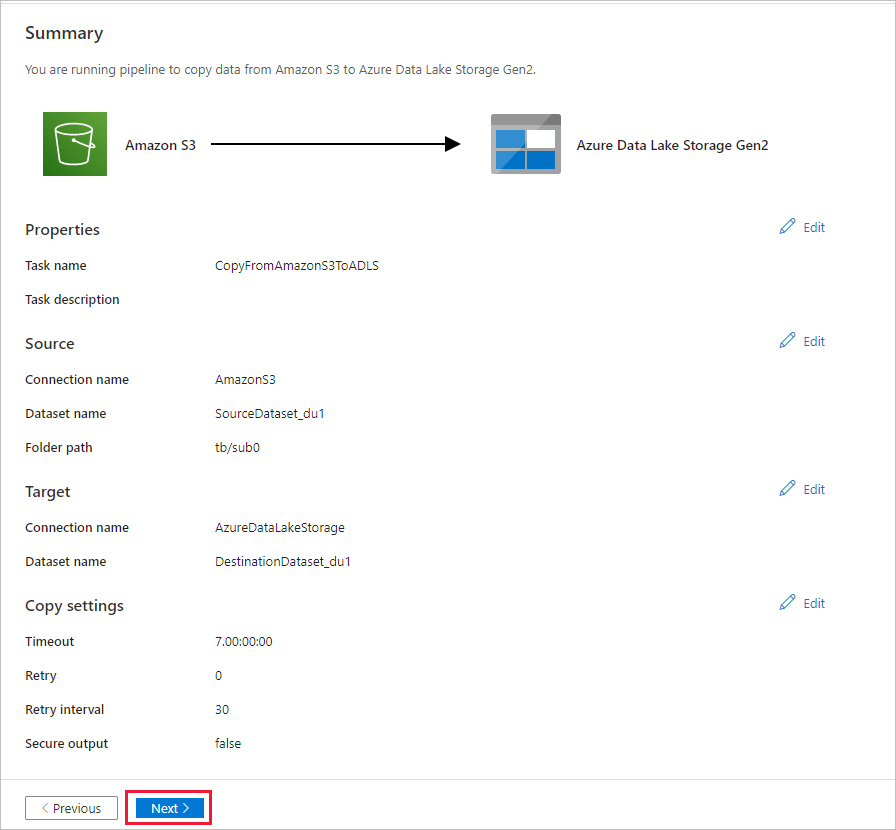
On the Deployment page, select Monitor to monitor the pipeline (task).
When the pipeline run completes successfully, you see a pipeline run that is triggered by a manual trigger. You can use links under the Pipeline name column to view activity details and to rerun the pipeline.
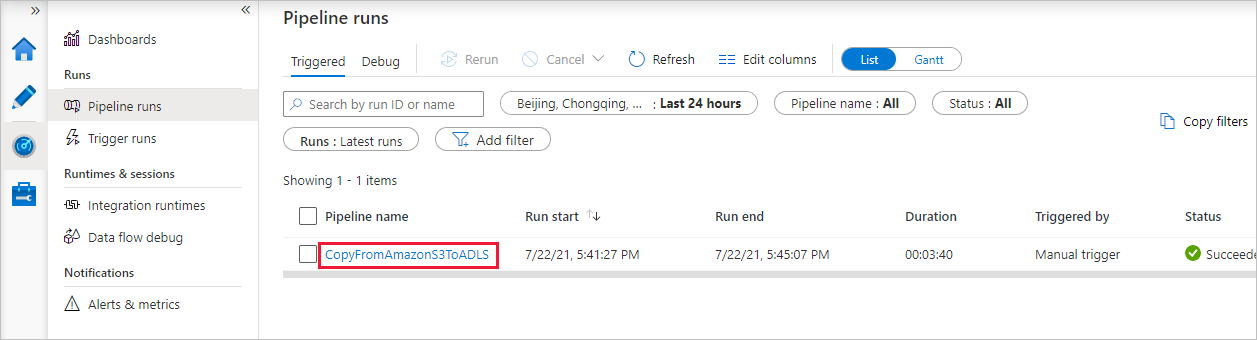
To see activity runs associated with the pipeline run, select the CopyFromAmazonS3ToADLS link under the Pipeline name column. For details about the copy operation, select the Details link (eyeglasses icon) under the Activity name column. You can monitor details like the volume of data copied from the source to the sink, data throughput, execution steps with corresponding duration, and used configuration.
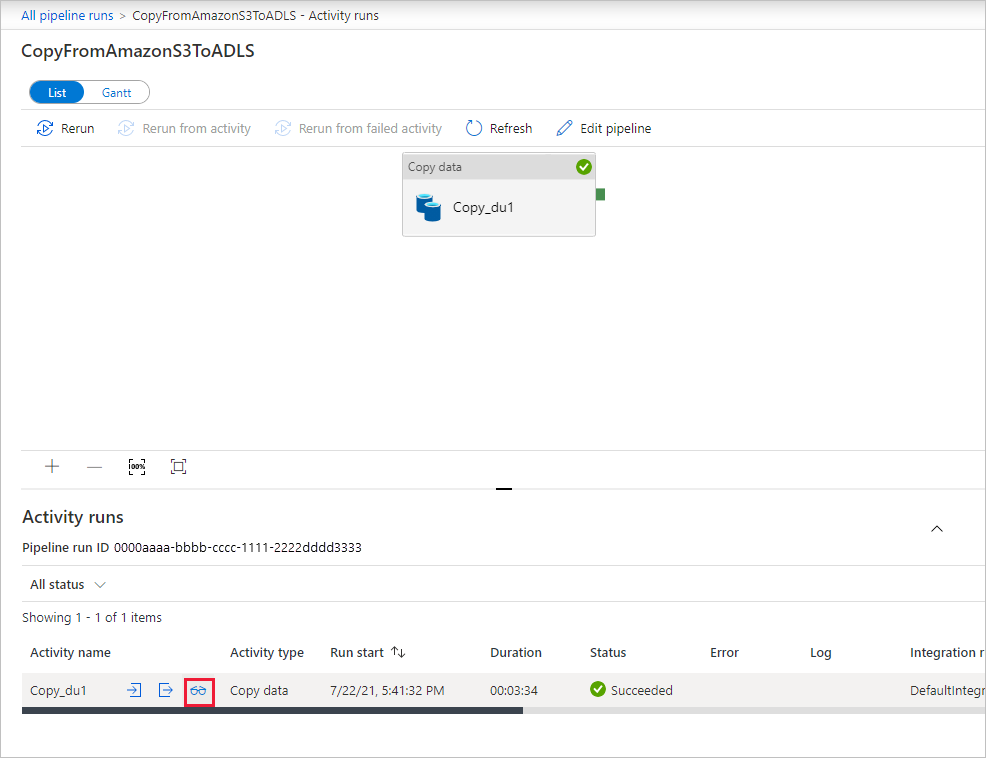
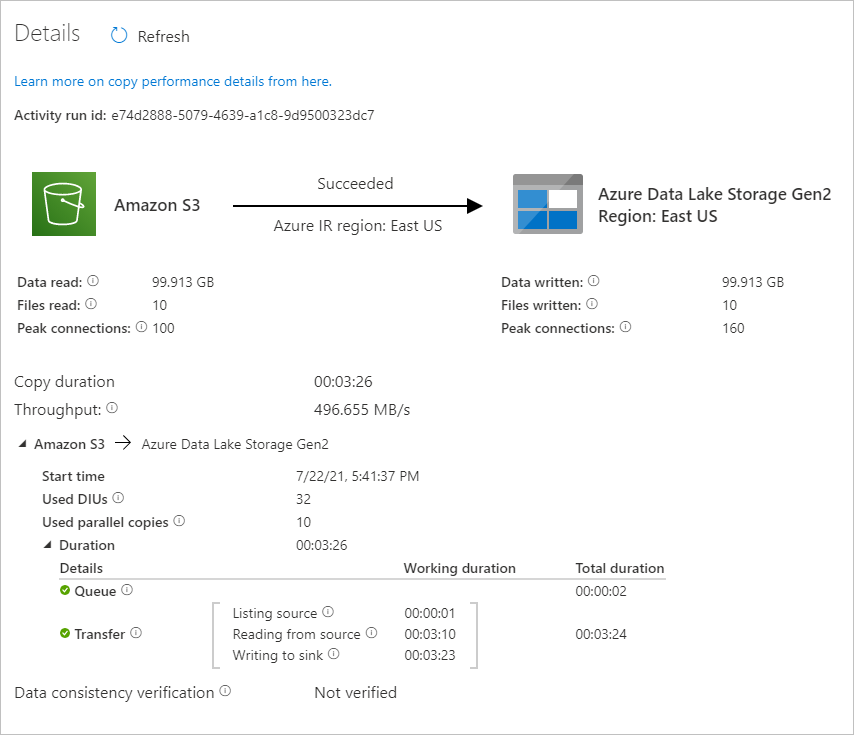
To refresh the view, select Refresh. Select All pipeline runs at the top to go back to the "Pipeline runs" view.
Verify that the data is copied into your Data Lake Storage Gen2 account.