Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
In Azure Data Factory and Synapse pipelines, you can use the Copy activity to copy data among data stores located on-premises and in the cloud. After you copy the data, you can use other activities to further transform and analyze it. You can also use the Copy activity to publish transformation and analysis results for business intelligence (BI) and application consumption.
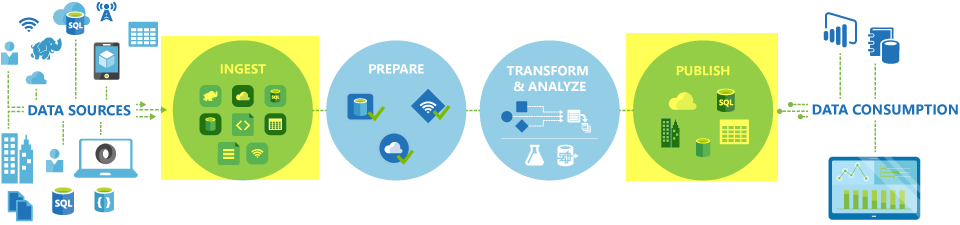
The Copy activity is executed on an integration runtime. You can use different types of integration runtimes for different data copy scenarios:
- When you're copying data between two data stores that are publicly accessible through the internet from any IP, you can use the Azure integration runtime for the copy activity. This integration runtime is secure, reliable, scalable, and globally available.
- When you're copying data to and from data stores that are located on-premises or in a network with access control (for example, an Azure virtual network), you need to set up a self-hosted integration runtime.
An integration runtime needs to be associated with each source and sink data store. For information about how the Copy activity determines which integration runtime to use, see Determining which IR to use.
Note
You can't use more than one self-hosted integration runtime within the same Copy activity. The source and sink for the activity must be connected with the same self-hosted integration runtime.
To copy data from a source to a sink, the service that runs the Copy activity performs these steps:
- Reads data from a source data store.
- Performs serialization/deserialization, compression/decompression, column mapping, and so on. It performs these operations based on the configuration of the input dataset, output dataset, and Copy activity.
- Writes data to the sink/destination data store.

Note
If a self-hosted integration runtime is used in either a source or sink data store within a Copy activity, then both the source and sink must be accessible from the server hosting the integration runtime for the Copy activity to be successful.
Supported data stores and formats
Note
If a connector is marked Preview, you can try it out and give us feedback. If you want to take a dependency on preview connectors in your solution, contact Azure support.
Supported file formats
Azure Data Factory supports the following file formats. Refer to each article for format-based settings.
- Avro format
- Binary format
- Delimited text format
- Excel format
- Iceberg format (only for Azure Data Lake Storage Gen2)
- JSON format
- ORC format
- Parquet format
- XML format
You can use the Copy activity to copy files as-is between two file-based data stores, in which case the data is copied efficiently without any serialization or deserialization. In addition, you can also parse or generate files of a given format, for example, you can perform the following:
- Copy data from a SQL Server database and write to Azure Data Lake Storage Gen2 in Parquet format.
- Copy files in text (CSV) format from an on-premises file system and write to Azure Blob storage in Avro format.
- Copy zipped files from an on-premises file system, decompress them on-the-fly, and write extracted files to Azure Data Lake Storage Gen2.
- Copy data in Gzip compressed-text (CSV) format from Azure Blob storage and write it to Azure SQL Database.
- Many more activities that require serialization/deserialization or compression/decompression.
Supported regions
The service that enables the Copy activity is available globally in the regions and geographies listed in Azure integration runtime locations. The globally available topology ensures efficient data movement that usually avoids cross-region hops. See Products by region to check the availability of Data Factory, Synapse Workspaces, and data movement in a specific region.
Configuration
To perform the copy activity with a pipeline, you can use one of the following tools or SDKs:
- Copy Data tool
- Azure portal
- .NET SDK
- Python SDK
- Azure PowerShell
- REST API
- Azure Resource Manager template
In general, to use the Copy activity in Azure Data Factory or Synapse pipelines, you need to:
- Create linked services for the source data store and the sink data store. You can find the list of supported connectors in the Supported data stores and formats section of this article. Refer to the connector article's "Linked service properties" section for configuration information and supported properties.
- Create datasets for the source and sink. Refer to the "Dataset properties" sections of the source and sink connector articles for configuration information and supported properties.
- Create a pipeline with the Copy activity. The next section provides an example.
Syntax
The following template of a Copy activity contains a complete list of supported properties. Specify the ones that fit your scenario.
"activities":[
{
"name": "CopyActivityTemplate",
"type": "Copy",
"inputs": [
{
"referenceName": "<source dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<sink dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>",
<properties>
},
"sink": {
"type": "<sink type>"
<properties>
},
"translator":
{
"type": "TabularTranslator",
"columnMappings": "<column mapping>"
},
"dataIntegrationUnits": <number>,
"parallelCopies": <number>,
"enableStaging": true/false,
"stagingSettings": {
<properties>
},
"enableSkipIncompatibleRow": true/false,
"redirectIncompatibleRowSettings": {
<properties>
}
}
}
]
Syntax details
| Property | Description | Required? |
|---|---|---|
| type | For a Copy activity, set to Copy |
Yes |
| inputs | Specify the dataset that you created that points to the source data. The Copy activity supports only a single input. | Yes |
| outputs | Specify the dataset that you created that points to the sink data. The Copy activity supports only a single output. | Yes |
| typeProperties | Specify properties to configure the Copy activity. | Yes |
| source | Specify the copy source type and the corresponding properties for retrieving data. For more information, see the "Copy activity properties" section in the connector article listed in Supported data stores and formats. |
Yes |
| sink | Specify the copy sink type and the corresponding properties for writing data. For more information, see the "Copy activity properties" section in the connector article listed in Supported data stores and formats. |
Yes |
| translator | Specify explicit column mappings from source to sink. This property applies when the default copy behavior doesn't meet your needs. For more information, see Schema mapping in copy activity. |
No |
| dataIntegrationUnits | Specify a measure that represents the amount of power that the Azure integration runtime uses for data copy. These units were formerly known as cloud Data Movement Units (DMU). For more information, see Data Integration Units. |
No |
| parallelCopies | Specify the parallelism that you want the Copy activity to use when reading data from the source and writing data to the sink. For more information, see Parallel copy. |
No |
| preserve | Specify whether to preserve metadata/ACLs during data copy. For more information, see Preserve metadata. |
No |
| enableStaging stagingSettings |
Specify whether to stage the interim data in Blob storage instead of directly copying data from source to sink. For information about useful scenarios and configuration details, see Staged copy. |
No |
| enableSkipIncompatibleRow redirectIncompatibleRowSettings |
Choose how to handle incompatible rows when you copy data from source to sink. For more information, see Fault tolerance. |
No |
Monitoring
You can monitor the Copy activity run in the Azure Data Factory and Synapse pipelines both visually and programmatically. For details, see Monitor copy activity.
Incremental copy
Data Factory and Synapse pipelines enable you to incrementally copy delta data from a source data store to a sink data store. For details, see Tutorial: Incrementally copy data.
Performance and tuning
The copy activity monitoring experience shows you the copy performance statistics for each of your activity run. The Copy activity performance and scalability guide describes key factors that affect the performance of data movement via the Copy activity. It also lists the performance values observed during testing and discusses how to optimize the performance of the Copy activity.
Resume from last failed run
Copy activity supports resume from last failed run when you copy large size of files as-is with binary format between file-based stores and choose to preserve the folder/file hierarchy from source to sink, for example, to migrate data from Amazon S3 to Azure Data Lake Storage Gen2. It applies to the following file-based connectors: Amazon S3, Amazon S3 Compatible Storage Azure Blob, Azure Data Lake Storage Gen2, Azure Files, File System, FTP, Google Cloud Storage, HDFS, Oracle Cloud Storage and SFTP.
You can use the copy activity resume in the following two ways:
Activity level retry: You can set retry count on copy activity. During the pipeline execution, if this copy activity run fails, the next automatic retry starts from last trial's failure point.
Rerun from failed activity: After pipeline execution completion, you can also trigger a rerun from the failed activity in the ADF UI monitoring view or programmatically. If the failed activity is a copy activity, the pipeline won't only rerun from this activity, but also resume from the previous run's failure point.
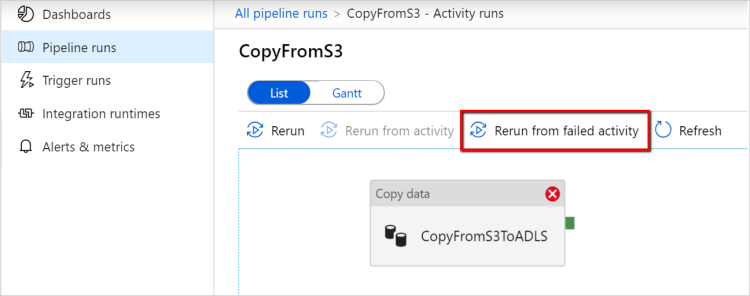
Few points to note:
- Resume happens at file level. If copy activity fails when copying a file, in next run, this specific file will be recopied.
- For resume to work properly, don't change the copy activity settings between the reruns.
- When you copy data from Amazon S3, Azure Blob, Azure Data Lake Storage Gen2, and Google Cloud Storage, copy activity can resume from arbitrary number of copied files. While for the rest of file-based connectors as source, currently copy activity supports resume from a limited number of files, usually at the range of tens of thousands and varies depending on the length of the file paths; files beyond this number will be recopied during reruns.
For other scenarios than binary file copy, copy activity rerun starts from the beginning.
Note
Resuming from last failed run via self-hosted integration runtime is now only supported in the self-hosted integration runtime version 5.43.8935.2 or above.
Preserve metadata along with data
While copying data from source to sink, in scenarios like data lake migration, you can also choose to preserve the metadata and ACLs along with data using copy activity. See Preserve metadata for details.
Add metadata tags to file based sink
When the sink is Azure Storage based (Azure data lake storage or Azure Blob Storage), we can opt to add some metadata to the files. These metadata will be appearing as part of the file properties as Key-Value pairs. For all the types of file based sinks, you can add metadata involving dynamic content using the pipeline parameters, system variables, functions, and variables. In addition to this, for binary file based sink, you have the option to add Last Modified datetime (of the source file) using the keyword $$LASTMODIFIED, and custom values as a metadata to the sink file.
Schema and data type mapping
See Schema and data type mapping for information about how the Copy activity maps your source data to your sink.
Add additional columns during copy
In addition to copying data from source data store to sink, you can also configure to add additional data columns to copy along to sink. For example:
- When you copy from a file-based source, store the relative file path as an additional column of type String to trace from which file the data comes from.
- Duplicate the specified source column as another column.
- Add a column with ADF expression, to attach ADF system variables like pipeline name/pipeline ID, or store other dynamic value from upstream activity's output.
- Add a column with static value to meet your downstream consumption need.
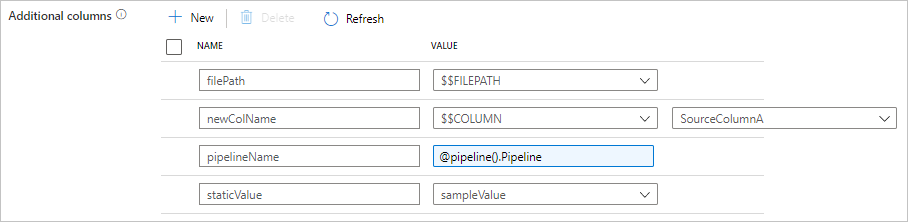
You can find the following configuration on copy activity source tab. You can also map those additional columns in copy activity schema mapping as usual by using your defined column names.
Tip
This feature works with the latest dataset model. If you don't see this option from the UI, try creating a new dataset.
To configure it programmatically, add the additionalColumns property in your copy activity source:
| Property | Description | Required |
|---|---|---|
| additionalColumns | Add additional data columns to copy to sink. Each object under the additionalColumns array represents an extra column. The name defines the column name, and the value indicates the data value of that column.Allowed data values are: - $$FILEPATH - a reserved variable indicates to store the source files' relative path to the folder path specified in dataset. Apply to file-based source.- $$COLUMN:<source_column_name> - a reserved variable pattern indicates to duplicate the specified source column as another column- Expression - Static value |
No |
Example:
"activities":[
{
"name": "CopyWithAdditionalColumns",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "<source type>",
"additionalColumns": [
{
"name": "filePath",
"value": "$$FILEPATH"
},
{
"name": "newColName",
"value": "$$COLUMN:SourceColumnA"
},
{
"name": "pipelineName",
"value": {
"value": "@pipeline().Pipeline",
"type": "Expression"
}
},
{
"name": "staticValue",
"value": "sampleValue"
}
],
...
},
"sink": {
"type": "<sink type>"
}
}
}
]
Tip
After configuring additional columns remember to map them to your destination sink, in the Mapping tab.
Auto create sink tables
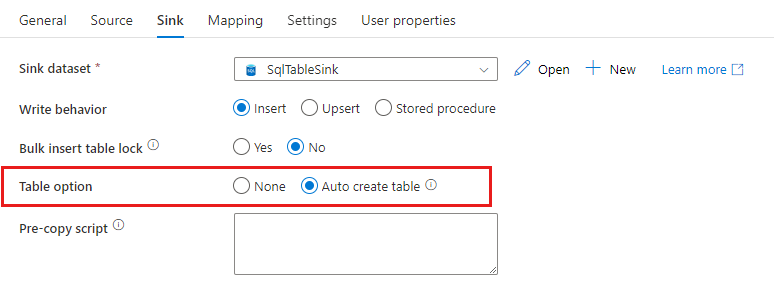
When you copy data into SQL database/Azure Synapse Analytics, if the destination table doesn't exist, copy activity supports automatically creating it based on the source data. It aims to help you quickly get started to load the data and evaluate SQL database/Azure Synapse Analytics. After the data ingestion, you can review and adjust the sink table schema according to your needs.
This feature is supported when copying data from any source into the following sink data stores. You can find the option on ADF authoring UI -> Copy activity sink -> Table option -> Auto create table, or via tableOption property in copy activity sink payload.
Fault tolerance
By default, the Copy activity stops copying data and returns a failure when source data rows are incompatible with sink data rows. To make the copy succeed, you can configure the Copy activity to skip and log the incompatible rows and copy only the compatible data. See Copy activity fault tolerance for details.
Data consistency verification
When you move data from source to destination store, copy activity provides an option for you to do extra data consistency verification to ensure the data isn't only successfully copied from source to destination store, but also verified to be consistent between source and destination store. Once inconsistent files have been found during the data movement, you can either abort the copy activity or continue to copy the rest by enabling fault tolerance setting to skip inconsistent files. You can get the skipped file names by enabling session log setting in copy activity. See Data consistency verification in copy activity for details.
Session log
You can log your copied file names, which can help you to further ensure the data isn't only successfully copied from source to destination store, but also consistent between source and destination store by reviewing the copy activity session logs. See Session sign in copy activity for details.
Related content
See the following quickstarts, tutorials, and samples: