Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
These features and Azure Databricks platform improvements were released in October 2019.
Note
In most cases, the release date and content listed below only correspond to actual deployment of the Azure Public Cloud.
It provide the evolution history of Azure Databricks service on Azure Public Cloud for your reference, which may not be consistent with the actual deployment on Azure operated by 21Vianet.
Note
Releases are staged. Your Azure Databricks account may not be updated until up to a week after the initial release date.
Supportability metrics moved to Azure Event Hubs
October 22-29, 2019
The supportability metrics that enable Azure Databricks to monitor cluster health have been migrated from Azure Blob storage to Event Hubs endpoints. This enables Azure Databricks to provide lower latency responses to resolve customer incidents. For VNet injection workspaces, we have added an additional rule to the network security group for the EventHub service endpoint. Details are available in the Deploy Azure Databricks in your Azure virtual network (VNet injection) table. There is no action required for continued availability of services.
For a list of the Azure Databricks supportability metrics Event Hubs endpoints by region, see Metastore, artifact Blob storage, system tables storage, log Blob storage, and Event Hubs endpoint IP addresses.
Azure Data Lake Storage credential passthrough on standard clusters and Scala is GA
October 22 - 29, 2019: Version 3.5
Credential passthrough for Python, SQL, and Scala on standard clusters running Databricks Runtime 5.5 and above, as well as SparkR on Databricks Runtime 6.0 and above is generally available. See Enable Azure Data Lake Storage credential passthrough for a Standard cluster.
Databricks Runtime 6.1 for Genomics GA
October 22, 2019
Databricks Runtime 6.1 for Genomics is generally available.
Databricks Runtime 6.1 for Machine Learning GA
October 22, 2019
Databricks Runtime 6.1 ML is generally available. It includes support for GPU clusters and upgrades to the following machine learning libraries:
- TensorFlow to 1.14.0
- PyTorch to 1.2.0
- Torchvision to 0.4.0
- MLflow to 1.3.0
MLflow API calls are now rate limited
October 22 - 29, 2019: Version 3.5
To ensure high quality of service under heavy load, Azure Databricks now enforces API rate limits for all MLflow API calls. The limits are set per account to ensure fair usage and high availability for all organizations sharing a workspace.
The MLflow clients with automatic retries are available in MLflow 1.3.0 and are in Databricks Runtime 6.1 ML. We advise all customers to switch to the latest MLflow client version.
For details, see Experiments API.
Pools of instances for quick cluster launch generally available
October 22 - 29, 2019: Version 3.5
The Azure Databricks feature that supports attaching a cluster to a predefined pool of idle instances is now generally available.
Azure Databricks does not charge DBUs while instances are idle in the pool. Instance provider billing does apply. See pricing.
For details, see Pool configuration reference.
Databricks Runtime 6.1 GA
October 16, 2019
Databricks Runtime 6.1 brings several enhancements to Delta Lake:
- Easily convert tables to Delta Lake format
- Python APIs for Delta tables (Public Preview)
- Dynamic File Pruning (DFP) enabled by default
Databricks Runtime 6.1 also removes several limitations in credential passthrough.
Note
Starting with the 6.1 release, Databricks Runtime supports only CPU clusters. If you want to use GPU clusters, you must use Databricks Runtime ML.
Databricks Runtime 6.0 for Genomics GA
October 16, 2019
Databricks Runtime for Genomics (Databricks Runtime Genomics) is a variant of Databricks Runtime optimized for working with genomic and biomedical data. Beginning with release 6.0, Databricks Runtime for Genomics is generally available.
Ability to deploy an Azure Databricks workspace to your own virtual network, also known as VNet injection, is GA
October 9, 2019
We are very pleased to announce the GA of the ability to deploy an Azure Databricks workspace to your own virtual network, also known as VNet injection. This option is intended for those of you who require network customization and therefore don't want to use the default VNet that is created when you deploy an Azure Databricks workspace in the standard manner. With VNet injection, you can:
- Connect Azure Databricks to other Azure services (such as Azure Storage) in a more secure manner using service endpoints.
- Connect to on-premises data sources for use with Azure Databricks, taking advantage of user-defined routes.
- Connect Azure Databricks to a network virtual appliance to inspect all outbound traffic and take actions according to allow and deny rules.
- Configure Azure Databricks to use custom DNS.
- Configure network security group (NSG) rules to specify egress traffic restrictions.
- Deploy Azure Databricks clusters in your existing virtual network.
Deploying Azure Databricks to your own virtual network also lets you take advantage of flexible CIDR ranges (anywhere between /16-/24 for the virtual network and up to /26 for the subnets).
Configuration using the Azure portal UI is quick and easy: when you create a workspace, just select Deploy Azure Databricks workspace in your Virtual Network, select your virtual network, and provide CIDR ranges for two subnets. Azure Databricks updates the virtual network with the two new subnets and network security groups, allows access to inbound and outbound subnet traffic, and deploys the workspace to the updated virtual network.
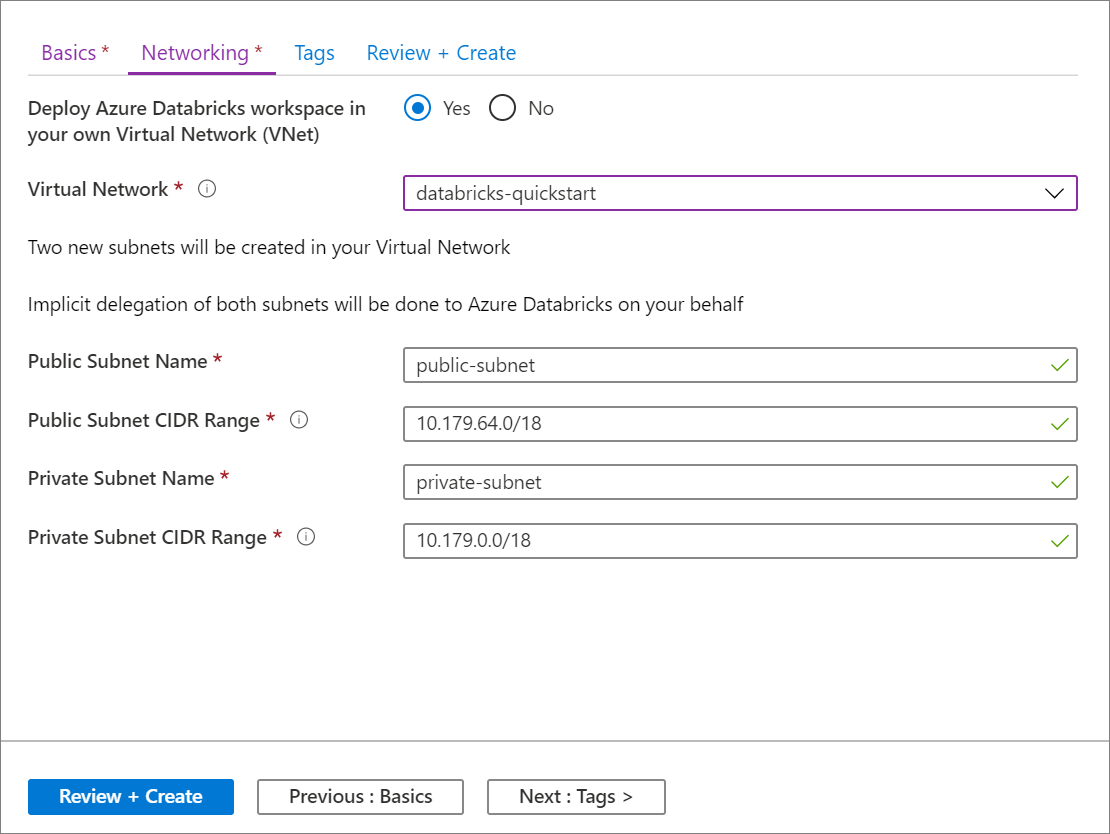
If you prefer to configure the virtual network for VNet injection yourself—for example, you want to use existing subnets, use existing network security groups, or create your own security rules—you can use Azure-Databricks-supplied ARM templates instead of the portal UI.
Note
If you participated in the VNet injection preview, you must upgrade your preview workspace to the GA version before January 31, 2020 to continue to receive support.
For details, see Deploy Azure Databricks in your Azure virtual network (VNet injection) and Connect your Azure Databricks workspace to your on-premises network.
Non-admin Azure Databricks users can read user and group names and IDs using SCIM API
October 8 - 15, 2019: Version 3.4
Non-admin users can now invoke the Groups API Get Users and Get Groups endpoints to read user and group display names and IDs only. All other SCIM API operations continue to require administrator access.
Workspace API returns notebook and folder object IDs
October 8 - 15, 2019: Version 3.4
The get-status and list endpoints of the Workspace API now return notebook and folder object IDs, giving you the ability to reference those objects in other API calls.
Databricks Runtime 6.0 ML GA
October 4, 2019
Databricks Runtime 6.0 ML includes the following updates:
- MLflow
- A new Spark data source for MLflow experiments now provides a standard API to load MLflow experiment run data.
- Added MLflow Java Client
- MLflow is now promoted as a top-tier library
- Hyperopt GA - Notable improvements since public preview include support for MLflow logging on Spark workers, correct handling of PySpark broadcast variables, as well as a new guide on model selection using Hyperopt.
- Upgraded Horovod and MLflow libraries and Anaconda distribution.
Note
Only CPU clusters are supported in this release.
New regions: Brazil South and France Central
October 1, 2019
Azure Databricks is now available in Brazil South (Sao Paulo State) and France Central (Paris).
Databricks Runtime 6.0 GA
October 1, 2019
Databricks Runtime 6.0 brings many library upgrades and new features, including:
- New Scala and Java APIs for Delta Lake DML commands, as well as the vacuum and history utility commands.
- Enhanced DBFS FUSE client for faster and more reliable reads and writes during model training.
- Support for multiple matplotlib plots per notebook cell.
- Update to Python 3.7, as well as updated numpy, pandas, matplotlib, and other libraries.
- Sunset of Python 2 support.
Note
Only CPU clusters are supported in this release.