Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This page describes how to use Delta Lake tables as sources and sinks for Spark Structured Streaming with readStream and writeStream. Delta Lake solves common performance and reliability problems for streaming systems and files. The benefits include:
- Coalesce small files produced by low-latency ingest and improve performance.
- Maintain "exactly-once" processing with more than one stream (or concurrent batch jobs).
- Efficiently discover new files when using files as a stream source.
To learn how to load data using streaming tables in Databricks SQL, see Use standalone streaming tables.
For stream-static joins with Delta Lake, see Stream-static joins.
For a complete list of DataStreamReader and DataStreamWriter options for Delta Lake, see DataStreamReader Delta Lake options and DataStreamWriter Delta Lake options.
Warning
If you use a Delta Lake table as a streaming source, the streaming query must run at least one time within the source table's retention window. The default retention windows are 7 days for VACUUM-removed data files and 30 days for the transaction log (logRetentionDuration). If a query falls behind these windows, it fails with DELTA_FILE_NOT_FOUND_DETAILED and must be reset with a full refresh.
Do not set spark.sql.files.ignoreMissingFiles to true as a workaround because this configuration silently produces incorrect results. If a stream's schedule can't keep up with the default retention windows, increase the source table's retention instead.
Use Delta Lake tables as a sink
You can write data into a Delta Lake table using Structured Streaming. The Delta Lake transaction log guarantees exactly-once processing, even when there are other streams or batch queries running concurrently against the table.
When you write to a Delta Lake table using a Structured Streaming sink, you might see empty commits with epochId = -1. These are expected and typically occur:
- On the first batch of each run of the streaming query (this happens every batch for
Trigger.AvailableNow). - When a schema is changed (such as adding a column).
These empty commits are intentional and do not indicate an error. They do not affect the correctness or performance of the query in any significant way.
Note
The Delta Lake VACUUM function removes all files not managed by Delta Lake but skips any directories that begin with _. You can safely store checkpoints alongside other data and metadata for a Delta Lake table using a directory structure such as <table-name>/_checkpoints.
Monitor backlog with metrics
Use the following metrics to monitor the backlog of a streaming query process:
numBytesOutstanding: Number of bytes yet to be processed in the backlog.numFilesOutstanding: Number of files yet to be processed in the backlog.numNewListedFiles: Number of Delta Lake files listed to calculate the backlog for this batch.backlogEndOffset: The Delta Lake table version used to calculate the backlog.
In a notebook, view these metrics under the Raw Data tab in the streaming query progress dashboard:
{
"sources": [
{
"description": "DeltaSource[file:/path/to/source]",
"metrics": {
"numBytesOutstanding": "3456",
"numFilesOutstanding": "8"
}
}
]
}
Append mode
By default, streams run in append mode and only add new records to the table.
Use the toTable method when streaming to tables:
Python
(events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
)
Scala
events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
Complete mode
Use Structured Streaming with complete mode to replace the entire table after every batch. For example, you can continuously update an aggregated summary table of events by customer:
Python
(spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
)
Scala
spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
For applications without strict latency requirements, you can save computing resources and costs with one-time triggers such as AvailableNow. For example, use this trigger to update summary aggregation tables on a given schedule, processing only new data that has arrived since the last update. See AvailableNow: Incremental batch processing.
Handle changes to source Delta Lake tables
Structured Streaming incrementally reads Delta Lake tables. When a streaming query reads from a Delta Lake table, new records are processed idempotently as new table versions commit to the source table. Structured Streaming only accepts append inputs and throws an exception if any modifications occur on the source Delta Lake table. For example, if an UPDATE, DELETE, MERGE INTO, or OVERWRITE operation modifies a source Delta Lake table that is read by a streaming query, the stream fails with an error.
There are four typical approaches for handling upstream changes to source Delta Lake tables, depending on your use case. A reference table and details on each are provided below:
| Approach | Pros | Cons |
|---|---|---|
skipChangeCommits |
Simple, does not require you to write complex logic. Useful for append-only processing where upstream changes are handled separately, or for temporarily handling a bad record. | Does not propagate changes and only processes appends. |
| Full refresh | Also simple, does not require you to write complex logic. Useful for small datasets with rare upstream changes. | Expensive for large datasets. Requires reprocessing all downstream tables. |
| Change data feed | Process all change types (inserts, updates, and deletes). Databricks recommends streaming from the CDC feed of a Delta Lake table rather than directly from the table whenever possible. | Requires you to write more complex logic to handle each change type. |
| Materialized views | Simple alternative to Structured Streaming that has automatic change propagation. | Higher latency. Only available in Lakeflow Spark Declarative Pipelines and Databricks SQL. |
Skip upstream change commits with skipChangeCommits
Set skipChangeCommits to ignore transactions that delete or modify existing records, and to process only appends. This is useful when changes to existing data do not need to be propagated through the stream, or when you prefer separate logic to handle those changes. You can turn on and turn off skipChangeCommits if you need to temporarily ignore one-time changes.
Databricks recommends using skipChangeCommits for most workloads that do not use change data feeds.
Python
(spark.readStream
.option("skipChangeCommits", "true")
.table("source_table")
)
Scala
spark.readStream
.option("skipChangeCommits", "true")
.table("source_table")
Important
If the schema for a Delta Lake table changes after a streaming read begins against the table, the query fails. For most schema changes, you can restart the stream to resolve schema mismatch and continue processing.
In Databricks Runtime 12.2 LTS and below, you cannot stream from a Delta Lake table with column mapping enabled that has undergone non-additive schema evolution such as renaming or dropping columns. For details, see Column mapping and streaming.
Note
In Databricks Runtime 12.2 LTS and above, skipChangeCommits replaces ignoreChanges. In Databricks Runtime 11.3 LTS and lower, ignoreChanges is the only supported option. See Legacy option: ignoreChanges for details.
Legacy option: ignoreDeletes
ignoreDeletes is a legacy option that only handles transactions that delete data at partition boundaries (that is, full partition drops). If you need to handle non-partition deletes, updates, or other modifications, use skipChangeCommits instead.
Python
(spark.readStream
.option("ignoreDeletes", "true")
.table("user_events")
)
Scala
spark.readStream
.option("ignoreDeletes", "true")
.table("user_events")
Legacy option: ignoreChanges
ignoreChanges is available in Databricks Runtime 11.3 LTS and lower. In Databricks Runtime 12.2 LTS and above, it is replaced by skipChangeCommits.
With ignoreChanges enabled, rewritten data files in the source table are re-emitted after a data modification operation such as UPDATE, MERGE INTO, DELETE (within partitions), or OVERWRITE. Unchanged rows are often emitted alongside new rows, so downstream consumers must be able to handle duplicates. Deletes are not propagated downstream. ignoreChanges takes precedence over ignoreDeletes.
In contrast, skipChangeCommits disregards file-changing operations entirely. Rewritten data files in the source table due to data modification operations such as UPDATE, MERGE INTO, DELETE, and OVERWRITE are ignored entirely. To reflect changes in stream source tables, you must implement separate logic to propagate these changes.
Databricks recommends using skipChangeCommits for all new workloads. To migrate a workload from ignoreChanges to skipChangeCommits, refactor your streaming logic.
Full refresh of downstream tables
If upstream changes are rare and the data is small enough to reprocess, you can delete the streaming checkpoint and output table, then restart the stream from the beginning. This causes the stream to reprocess all data from the source table. Be aware that this approach also requires reprocessing all downstream tables that depend on the output of this stream.
This approach is best suited for smaller datasets or workloads where upstream changes are infrequent and the cost of a full refresh is acceptable.
Use change data feed
For workloads that process all types of changes (inserts, updates, and deletes), use the Delta Lake change data feed. The change data feed records row-level changes to a Delta Lake table, allowing you to stream those changes and write logic to handle each change type in downstream tables. This is the most robust approach because your code explicitly handles every type of change event. See Use change data feed on Azure Databricks.
If you are using Lakeflow Spark Declarative Pipelines, see The AUTO CDC APIs: Simplify change data capture with pipelines.
Important
In Databricks Runtime 12.2 LTS and below, you can't stream from the change data feed for a Delta Lake table with column mapping enabled that has undergone non-additive schema evolution, such as renaming or dropping columns. See Column mapping and streaming.
Use materialized views
Materialized views automatically handle upstream changes by recomputing results when source data changes. If you do not need the lowest possible latency and want to avoid managing streaming complexity, a materialized view can simplify your architecture. Materialized views are available in Lakeflow Spark Declarative Pipelines and standalone pipelines. See Materialized views.
Example
For example, suppose you have a table user_events with date, user_email, and action columns that is partitioned by date. You stream out of the user_events table and you need to delete data from it due to GDPR.
skipChangeCommits allows you to delete data in multiple partitions (in this example, filtering on user_email). Use the following syntax:
spark.readStream
.option("skipChangeCommits", "true")
.table("user_events")
If you update a user_email with the UPDATE statement, the file containing the user_email in question is rewritten. Use skipChangeCommits to ignore the changed data files.
Databricks recommends using skipChangeCommits instead of ignoreDeletes unless you are certain that deletes are always full partition drops.
Use foreachBatch for idempotent table writes
Note
Databricks recommends configuring a separate streaming write for each sink you want to update instead of using foreachBatch. Writes to multiple sinks in foreachBatch reduces parallelization and increases overall latency because writes to multiple tables are serialized in foreachBatch.
Delta Lake tables support the following DataFrameWriter options to make writes to multiple tables within foreachBatch idempotent:
txnAppId: A unique string that you can pass on each DataFrame write. For example, you can use the StreamingQuery ID astxnAppId.txnAppIdcan be any user-generated unique string and does not have to be related to the stream ID.txnVersion: A monotonically increasing number that acts as transaction version.
Delta Lake uses txnAppId and txnVersion to identify and ignore duplicate writes. For example, after a failure interrupts a batch write, you can re-run the batch with the same txnAppId and txnVersion to correctly identify and ignore duplicates. See Use foreachBatch to write to arbitrary data sinks.
Warning
If you delete the streaming checkpoint and restart the query with a new checkpoint, you must provide a different txnAppId. New checkpoints start with a batch ID of 0. Delta Lake uses the batch ID and txnAppId as a unique key, and skips batches with already seen values.
The following code example demonstrates this pattern:
Python
app_id = ... # A unique string that is used as an application ID.
def writeToDeltaLakeTableIdempotent(batch_df, batch_id):
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 1
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 2
streamingDF.writeStream.foreachBatch(writeToDeltaLakeTableIdempotent).start()
Scala
val appId = ... // A unique string that is used as an application ID.
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 1
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 2
}
Upsert from streaming queries using foreachBatch
You can use merge and foreachBatch to write complex upserts from a streaming query into a Delta Lake table. See Use foreachBatch to write to arbitrary data sinks.
This approach has many applications:
- Improve write performance with
updateoutput mode, whereascompleteoutput mode requires rewriting the entire result table for each microbatch. - Continuously apply a stream of changes to a Delta Lake table by using a merge query to write change data in
foreachBatch. See Slowly changing data (SCD) and change data capture (CDC) with Delta Lake. - Handle deduplication during stream processing. You can use an insert-only merge query in
foreachBatchto continuously write data to a Delta Lake table with automatic deduplication. See Data deduplication when writing into Delta Lake tables.
Note
Verify that your
mergestatement insideforeachBatchis idempotent. Otherwise, restarts of the streaming query can apply the operation on the same batch of data multiple times. See UseforeachBatchfor idempotent table writes.When
mergeis used inforeachBatch, the input data rate metric might return a multiple of the actual rate that data is generated at the source.mergereads input data multiple times, which multiplies the metrics. To prevent metric multiplication, cache the batch DataFrame beforemergeand then uncache it aftermerge.Input data rate is available through
StreamingQueryProgressand in the notebook streaming rate graph. See Monitoring Structured Streaming queries on Azure Databricks.
For example, you can use MERGE SQL statements within foreachBatch:
Scala
// Function to upsert microBatchOutputDF into Delta Lake table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
// Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
// Use the view name to apply MERGE
// NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
microBatchOutputDF.sparkSession.sql(s"""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
}
// Write the output of a streaming aggregation query into Delta Lake table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
# Function to upsert microBatchOutputDF into Delta Lake table using merge
def upsertToDelta(microBatchOutputDF, batchId):
# Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
# Use the view name to apply MERGE
# NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
# In Databricks Runtime 10.5 and below, you must use the following:
# microBatchOutputDF._jdf.sparkSession().sql("""
microBatchOutputDF.sparkSession.sql("""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
# Write the output of a streaming aggregation query into Delta Lake table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
You can also use the Delta Lake APIs for streaming upserts:
Scala
import io.delta.tables.*
val deltaTable = DeltaTable.forName(spark, "table_name")
// Function to upsert microBatchOutputDF into Delta Lake table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
deltaTable.as("t")
.merge(
microBatchOutputDF.as("s"),
"s.key = t.key")
.whenMatched().updateAll()
.whenNotMatched().insertAll()
.execute()
}
// Write the output of a streaming aggregation query into Delta Lake table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
from delta.tables import *
deltaTable = DeltaTable.forName(spark, "table_name")
# Function to upsert microBatchOutputDF into Delta Lake table using merge
def upsertToDelta(microBatchOutputDF, batchId):
(deltaTable.alias("t").merge(
microBatchOutputDF.alias("s"),
"s.key = t.key")
.whenMatchedUpdateAll()
.whenNotMatchedInsertAll()
.execute()
)
# Write the output of a streaming aggregation query into Delta Lake table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
Set initial table version to process changes
By default, streams begin with the latest available Delta Lake table version. This includes a complete snapshot of the table at that moment and all future changes. Databricks recommends that you use the default initial table version for most workloads.
Optionally, you can use the following options to specify the starting point of the Delta Lake streaming source without processing the entire table.
startingVersion: The Delta Lake table version to start reading from. All table changes committed at or after the specified version are read by the stream. If the specified version is not available, the stream fails to start.To find available commit versions, run
DESCRIBE HISTORYand check theversion. To return only the latest changes, specifylatest. For information on Delta Lake table versions, see Work with table history.startingTimestamp: The timestamp to start reading from. All table changes committed at or after the specified timestamp are read by the stream. If the provided timestamp precedes all table commits, the streaming read begins with the earliest available timestamp. Set either:- A timestamp string. For example,
"2019-01-01T00:00:00.000Z". - A date string. For example,
"2019-01-01".
- A timestamp string. For example,
You cannot set both startingVersion and startingTimestamp at the same time. These settings apply to new streaming queries only. If a streaming query has started and the progress has been recorded in its checkpoint, these settings are ignored.
Important
Although you can start the streaming source from a specified version or timestamp, the schema of the streaming source is always the latest schema of the Delta Lake table. You must ensure there is no incompatible schema change to the Delta Lake table after the specified version or timestamp. Otherwise, the streaming source might return incorrect results when reading the data with an incorrect schema.
Example
For example, suppose you have a table user_events. If you want to read changes since version 5, use:
spark.readStream
.option("startingVersion", "5")
.table("user_events")
If you want to read changes since 2018-10-18, use:
spark.readStream
.option("startingTimestamp", "2018-10-18")
.table("user_events")
Process initial snapshot without dropping data
This feature is available on Databricks Runtime 11.3 LTS and above.
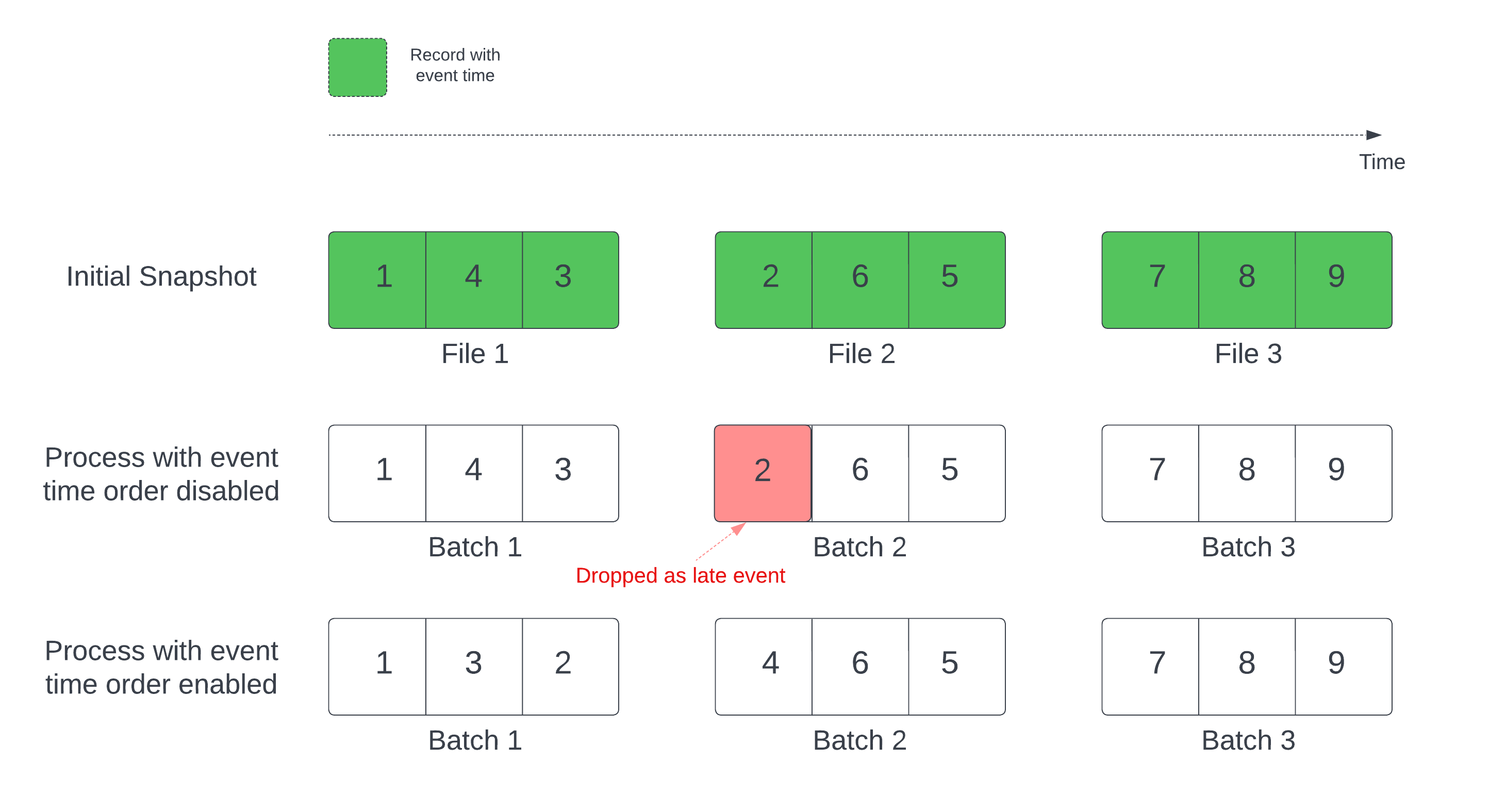
In a stateful streaming query with a defined watermark, processing files by modification time can process records in the wrong order. This can cause the watermark to incorrectly mark records as late events and drop them. This can only occur when the initial Delta snapshot is processed in the default order.
For streams with a Delta source table, the query first processes all of the data present in the table and creates a version called the initial snapshot. By default, the Delta Lake table's data files are processed based on which file was last modified. However, the last modification time does not necessarily represent the record event time order.
To avoid data drops during initial snapshot processing, enable the withEventTimeOrder option. withEventTimeOrder divides the event time range of initial snapshot data into time buckets. Each micro-batch processes a bucket by filtering data within the time range. The maxFilesPerTrigger and maxBytesPerTrigger options are still applicable to control the micro-batch size, but only approximately due to the processing approach.
The following diagram shows this process:
Constraints
- You cannot change
withEventTimeOrderif the stream query has started and the initial snapshot is actively processing. To restart withwithEventTimeOrderchanged, you must delete the checkpoint. - If
withEventTimeOrderis enabled, you cannot downgrade a stream to a Databricks Runtime version that does not support this feature until the initial snapshot processing completes. To downgrade, wait for the initial snapshot to finish, or delete the checkpoint and restart the query. - This feature is not supported in the following scenarios:
- The event time column is a generated column and there are non-projection transformations between the Delta source and watermark.
- There is a watermark that has more than one Delta source in the stream query.
Performance
If withEventTimeOrder is enabled, initial snapshot processing performance might be slower. Each micro-batch scans the initial snapshot to filter data within the corresponding event time range. To improve filtering performance:
- Use a Delta source column as the event time so that data skipping can be applied. See Data skipping.
- Partition the table along the event time column.
Use the Spark UI to see how many Delta files are scanned for a specific micro-batch.
Example
Suppose you have a table user_events with an event_time column. Your streaming query is an aggregation query. If you want to ensure no data drop during the initial snapshot processing, you can use:
spark.readStream
.option("withEventTimeOrder", "true")
.table("user_events")
.withWatermark("event_time", "10 seconds")
You can set withEventTimeOrder with a Spark configuration on the cluster to apply it to all streaming queries: spark.databricks.delta.withEventTimeOrder.enabled true.
Limit input rate to improve processing performance
By default, Structured Streaming processes as many files as possible in each micro-batch. To limit the amount of data processed per batch and manage memory usage, stabilize latency, or reduce cloud storage costs, use the following options:
maxFilesPerTrigger: The number of new files to be considered in every micro-batch. The default is 1000.maxBytesPerTrigger: The amount of data that gets processed in each micro-batch. This option sets a "soft max", meaning that a batch processes approximately this amount of data and might process more than the limit in order to make the streaming query move forward in cases when the smallest input unit is larger than this limit. This is not set by default.
If you use both maxBytesPerTrigger and maxFilesPerTrigger, the micro-batch processes data until either the maxFilesPerTrigger or maxBytesPerTrigger limit is reached.
Note
By default, if logRetentionDuration cleans up transactions in the source table and the streaming query tries to process those versions, the query fails to prevent data loss. You can set the option failOnDataLoss to false to ignore lost data and continue processing. See Configure data retention for time travel queries.
Control cloud storage cost
Streaming queries have several trigger modes available that allow you to balance cost and latency, including processingTime, availableNow, and realTime. See Control cloud storage cost.