Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Learn about the top issues and their resolutions when working with Apache Hadoop YARN payloads in Apache Ambari.
How do I create a new YARN queue on a cluster?
Resolution steps
Use the following steps in Ambari to create a new YARN queue, and then balance the capacity allocation among all the queues.
In this example, two existing queues (default and thriftsvr) both are changed from 50% capacity to 25% capacity, which gives the new queue (spark) 50% capacity.
| Queue | Capacity | Maximum capacity |
|---|---|---|
| default | 25% | 50% |
| thrftsvr | 25% | 50% |
| spark | 50% | 50% |
Select the Ambari Views icon, and then select the grid pattern. Next, select YARN Queue Manager.
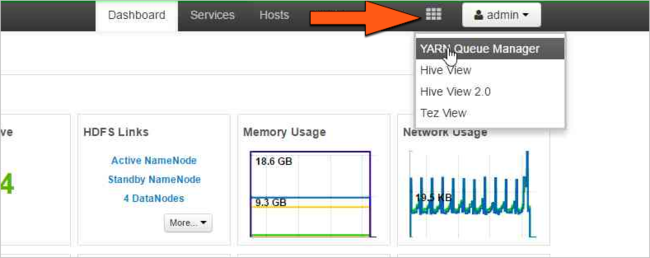
Select the default queue.
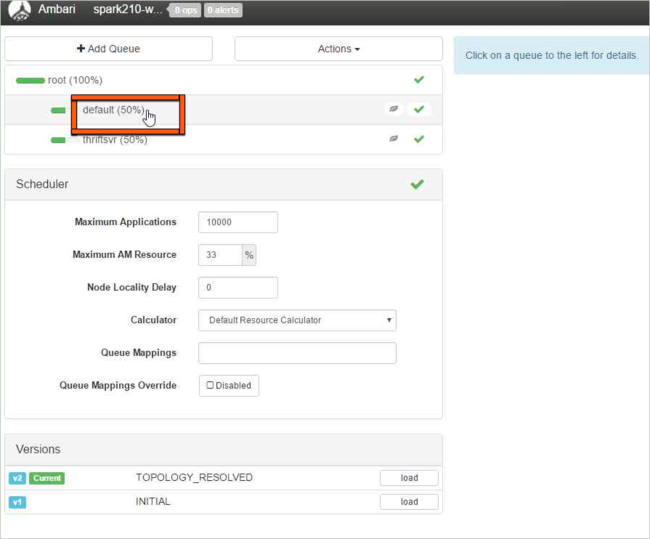
For the default queue, change the capacity from 50% to 25%. For the thriftsvr queue, change the capacity to 25%.
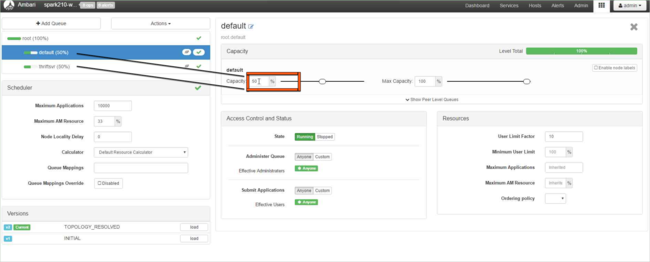
To create a new queue, select Add Queue.
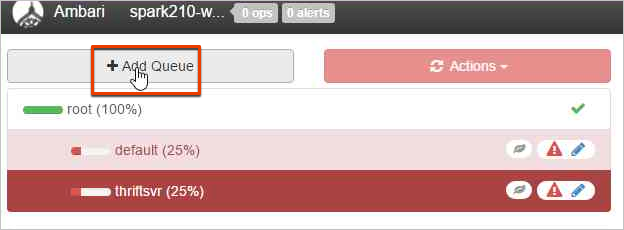
Name the new queue.
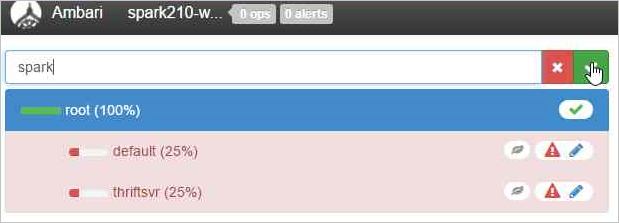
Leave the capacity values at 50%, and then select the Actions button.
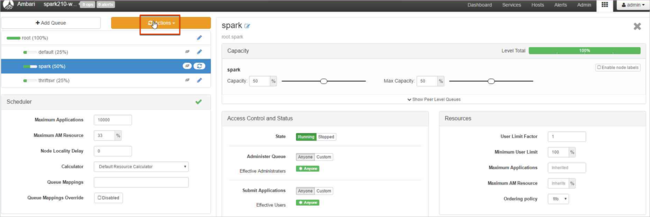
Select Save and Refresh Queues.
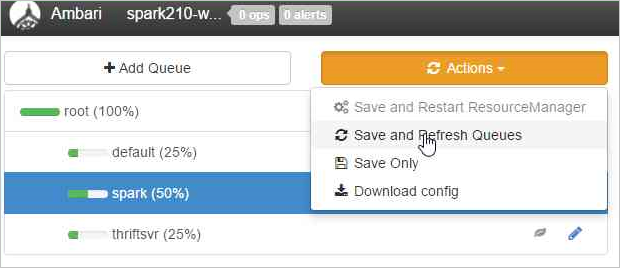
These changes are visible immediately on the YARN Scheduler UI.
Further reading
How do I download YARN logs from a cluster?
Resolution steps
Connect to the HDInsight cluster by using a Secure Shell (SSH) client. For more information, see Further reading.
To list all the application IDs of the YARN applications that are currently running, run the following command:
yarn topThe IDs are listed in the APPLICATIONID column. You can download logs from the APPLICATIONID column.
YARN top - 18:00:07, up 19d, 0:14, 0 active users, queue(s): root NodeManager(s): 4 total, 4 active, 0 unhealthy, 0 decommissioned, 0 lost, 0 rebooted Queue(s) Applications: 2 running, 10 submitted, 0 pending, 8 completed, 0 killed, 0 failed Queue(s) Mem(GB): 97 available, 3 allocated, 0 pending, 0 reserved Queue(s) VCores: 58 available, 2 allocated, 0 pending, 0 reserved Queue(s) Containers: 2 allocated, 0 pending, 0 reserved APPLICATIONID USER TYPE QUEUE #CONT #RCONT VCORES RVCORES MEM RMEM VCORESECS MEMSECS %PROGR TIME NAME application_1490377567345_0007 hive spark thriftsvr 1 0 1 0 1G 0G 1628407 2442611 10.00 18:20:20 Thrift JDBC/ODBC Server application_1490377567345_0006 hive spark thriftsvr 1 0 1 0 1G 0G 1628430 2442645 10.00 18:20:20 Thrift JDBC/ODBC ServerTo download YARN container logs for all application masters, use the following command:
yarn logs -applicationIdn logs -applicationId <application_id> -am ALL > amlogs.txtThis command creates a log file named amlogs.txt.
To download YARN container logs for only the latest application master, use the following command:
yarn logs -applicationIdn logs -applicationId <application_id> -am -1 > latestamlogs.txtThis command creates a log file named latestamlogs.txt.
To download YARN container logs for the first two application masters, use the following command:
yarn logs -applicationIdn logs -applicationId <application_id> -am 1,2 > first2amlogs.txtThis command creates a log file named first2amlogs.txt.
To download all YARN container logs, use the following command:
yarn logs -applicationIdn logs -applicationId <application_id> > logs.txtThis command creates a log file named logs.txt.
To download the YARN container log for a specific container, use the following command:
yarn logs -applicationIdn logs -applicationId <application_id> -containerId <container_id> > containerlogs.txtThis command creates a log file named containerlogs.txt.
Additional reading
Next steps
If you didn't see your problem or are unable to solve your issue, visit one of the following channels for more support:
- If you need more help, you can submit a support request from the Azure portal. Select Support from the menu bar or open the Help + support hub.