Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
In this quickstart, you learn how to use Apache Zeppelin to run Apache Hive queries in Azure HDInsight. HDInsight Interactive Query clusters include Apache Zeppelin notebooks that you can use to run interactive Hive queries.
If you don't have an Azure subscription, create a trial subscription before you begin.
Prerequisites
An HDInsight Interactive Query cluster. See Create cluster to create an HDInsight cluster. Make sure to choose the Interactive Query cluster type.
Create an Apache Zeppelin Note
Replace
CLUSTERNAMEwith the name of your cluster in the following URLhttps://CLUSTERNAME.azurehdinsight.cn/zeppelin. Then enter the URL in a web browser.Enter your cluster login username and password. From the Zeppelin page, you can either create a new note or open existing notes. HiveSample contains some sample Hive queries.
Select Create new note.
From the Create new note dialog, type or select the following values:
- Note Name: Enter a name for the note.
- Default interpreter: Select jdbc from the drop-down list.
Select Create Note.
Enter the following Hive query in the code section, and then press Shift + Enter:
%jdbc(hive) show tables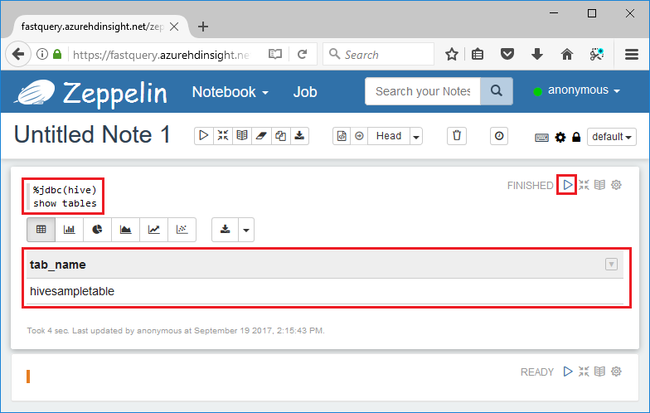
The
%jdbc(hive)statement in the first line tells the notebook to use the Hive JDBC interpreter.The query shall return one Hive table called hivesampletable.
The following are two more Hive queries that you can run against hivesampletable:
%jdbc(hive) select * from hivesampletable limit 10 %jdbc(hive) select ${group_name}, count(*) as total_count from hivesampletable group by ${group_name=market,market|deviceplatform|devicemake} limit ${total_count=10}Compared to the traditional Hive, the query results come back much faster.
More examples
Create a table. Execute the code in the Zeppelin Notebook:
%jdbc(hive) CREATE EXTERNAL TABLE log4jLogs ( t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE;Load data into the new table. Execute the code in the Zeppelin Notebook:
%jdbc(hive) LOAD DATA INPATH 'wasbs:///example/data/sample.log' INTO TABLE log4jLogs;Insert a single record. Execute the code in the Zeppelin Notebook:
%jdbc(hive) INSERT INTO TABLE log4jLogs2 VALUES ('A', 'B', 'C', 'D', 'E', 'F', 'G');
Review the Hive language manual for more syntax.
Clean up resources
After you complete the quickstart, you may want to delete the cluster. With HDInsight, your data is stored in Azure Storage, so you can safely delete a cluster when it isn't in use. You're also charged for an HDInsight cluster, even when it isn't in use. Since the charges for the cluster are many times more than the charges for storage, it makes economic sense to delete clusters when they aren't in use.
To delete a cluster, see Delete an HDInsight cluster using your browser, PowerShell, or the Azure CLI.
Next steps
In this quickstart, you learned how to use Apache Zeppelin to run Apache Hive queries in Azure HDInsight. To learn more about Hive queries, the next article will show you how to execute queries with Visual Studio.