Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
APPLIES TO:
 Azure CLI ml extension v2 (current)
Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)
Python SDK azure-ai-ml v2 (current)
This article describes online endpoints for real-time inferencing in Azure Machine Learning. Inferencing is the process of applying new input data to a machine learning model to generate outputs. Azure Machine Learning allows you to perform real-time inferencing on data by using models that are deployed to online endpoints. While these outputs are typically called predictions, you can use inferencing to generate outputs for other machine learning tasks, such as classification and clustering.
Online endpoints
Online endpoints deploy models to a web server that can return predictions under the HTTP protocol. Online endpoints can operationalize models for real-time inference in synchronous, low-latency requests, and are best used when:
- You have low-latency requirements.
- Your model can answer the request in a relatively short amount of time.
- Your model's inputs fit on the HTTP payload of the request.
- You need to scale up the number of requests.
To define an endpoint, you must specify:
- Endpoint name. This name must be unique in the Azure region. For other naming requirements, see Azure Machine Learning online endpoints and batch endpoints.
- Authentication mode. You can choose from key-based authentication mode, Azure Machine Learning token-based authentication mode, or Microsoft Entra token-based authentication for the endpoint. For more information on authenticating, see Authenticate clients for online endpoints.
Managed online endpoints
Managed online endpoints deploy your machine learning models in a convenient, turnkey manner, and are the recommended way to use Azure Machine Learning online endpoints. Managed online endpoints work with powerful CPU and GPU machines in Azure in a scalable, fully managed way.
To free you from the overhead of setting up and managing the underlying infrastructure, these endpoints also take care of serving, scaling, securing, and monitoring your models. To learn how to define managed online endpoints, see Define the endpoint.
Managed online endpoints vs Azure Container Instances or Azure Kubernetes Service (AKS) v1
Managed online endpoints are the recommended way to use online endpoints in Azure Machine Learning. The following table highlights key attributes of managed online endpoints compared to Azure Container Instances and Azure Kubernetes Service (AKS) v1 solutions.
| Attributes | Managed online endpoints (v2) | Container Instances or AKS (v1) |
|---|---|---|
| Network security/isolation | Easy inbound/outbound control with quick toggle | Virtual network not supported or requires complex manual configuration |
| Managed service | * Fully managed compute provisioning/scaling * Network configuration for data exfiltration prevention * Host OS upgrade, controlled rollout of in-place updates |
* Scaling is limited * User must manage network configuration or upgrade |
| Endpoint/deployment concept | Distinction between endpoint and deployment enables complex scenarios such as safe rollout of models | No concept of endpoint |
| Diagnostics and Monitoring | * Local endpoint debugging possible with Docker and Visual Studio Code * Advanced metrics and logs analysis with chart/query to compare between deployments * Cost breakdown to deployment level |
No easy local debugging |
| Scalability | Elastic, and automatic scaling (not bound by the default cluster size) | * Container Instances isn't scalable * AKS v1 supports in-cluster scale only and requires scalability configuration |
| Enterprise readiness | Private link, customer managed keys, Microsoft Entra ID, quota management, billing integration, Service Level Agreement (SLA) | Not supported |
| Advanced ML features | * Model data collection * Model monitoring * Champion-challenger model, safe rollout, traffic mirroring * Responsible AI extensibility |
Not supported |
Managed online endpoints vs Kubernetes online endpoints
If you prefer to use Kubernetes to deploy your models and serve endpoints, and you're comfortable with managing infrastructure requirements, you can use Kubernetes online endpoints. These endpoints allow you to deploy models and serve online endpoints with CPUs or GPUs at your fully configured and managed Kubernetes cluster anywhere.
Managed online endpoints can help streamline your deployment process and provide the following benefits over Kubernetes online endpoints:
Automatic infrastructure management
- Provisions the compute and hosts the model. You just specify the virtual machine (VM) type and scale settings.
- Updates and patches the underlying host OS image.
- Performs node recovery if there's a system failure.
Monitoring and logs
- Ability to monitor model availability, performance, and SLA using native integration with Azure Monitor.
- Ease of debugging deployments by using logs and native integration with Log Analytics.
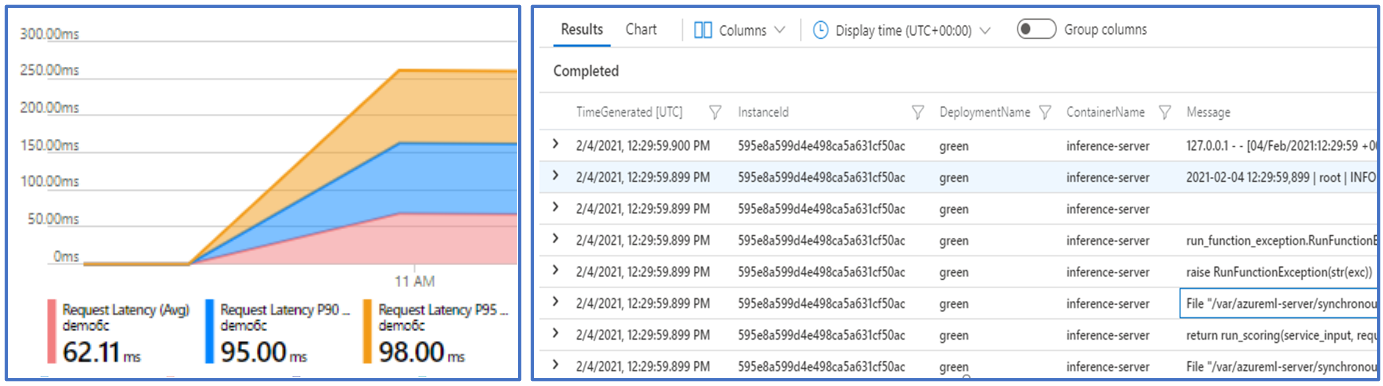
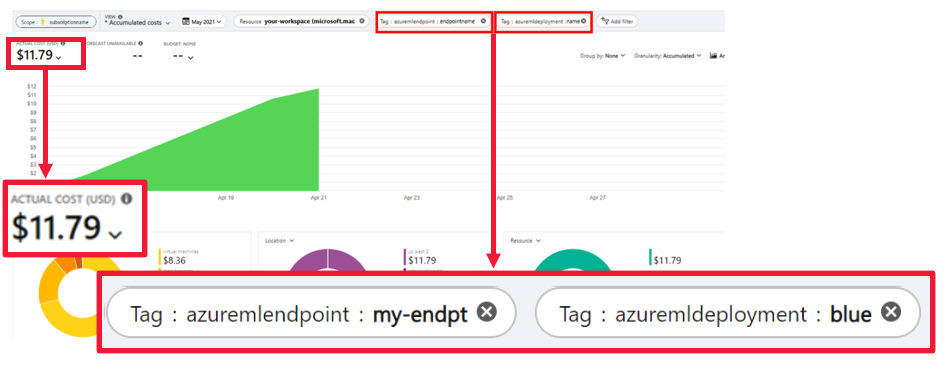
Cost analysis view allows you to monitor costs at the endpoint and deployment level.
Note
Managed online endpoints are based on Azure Machine Learning compute. When you use a managed online endpoint, you pay for the compute and networking charges. There's no added surcharge. For more information on pricing, see the Azure pricing calculator.
If you use an Azure Machine Learning virtual network to secure outbound traffic from the managed online endpoint, you're charged for the Azure private link and fully qualified domain name (FQDN) outbound rules that the managed virtual network uses. For more information, see Pricing for managed virtual network.


The following table highlights the key differences between managed online endpoints and Kubernetes online endpoints.
| Managed online endpoints | Kubernetes online endpoints (AKS v2) | |
|---|---|---|
| Recommended users | Users who want a managed model deployment and enhanced MLOps experience | Users who prefer Kubernetes and can self-manage infrastructure requirements |
| Node provisioning | Managed compute provisioning, update, removal | User responsibility |
| Node maintenance | Managed host OS image updates and security hardening | User responsibility |
| Cluster sizing (scaling) | Managed manual and autoscale supporting additional node provisioning | Manual and autoscale, supporting scaling the number of replicas within fixed cluster boundaries |
| Compute type | Managed by the service | Customer-managed Kubernetes cluster |
| Managed identity | Supported | Supported |
| Virtual network | Supported via managed network isolation | User responsibility |
| Out-of-box monitoring and logging | Azure Monitor and Log Analytics powered, including key metrics and log tables for endpoints and deployments | User responsibility |
| Logging with Application Insights (legacy) | Supported | Supported |
| Cost view | Detailed to endpoint/deployment level | Cluster level |
| Costs applied to | Virtual machines (VMs) assigned to the deployment | VMs assigned to the cluster |
| Mirrored traffic | Supported | Unsupported |
| No-code deployment | Supports MLflow and Triton models | Supports MLflow and Triton models |
Online deployments
A deployment is a set of resources and computes required to host the model that does the inferencing. A single endpoint can contain multiple deployments with different configurations. This setup helps to decouple the interface presented by the endpoint from the implementation details present in the deployment. An online endpoint has a routing mechanism that can direct requests to specific deployments in the endpoint.
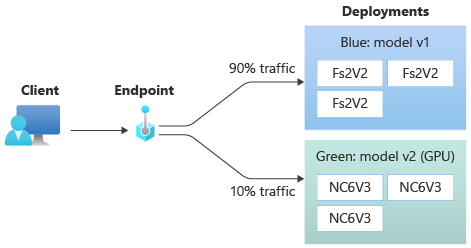
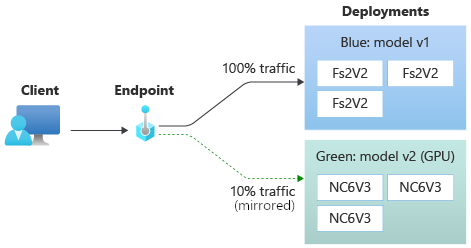
The following diagram shows an online endpoint that has two deployments, blue and green. The blue deployment uses VMs with a CPU SKU, and runs version 1 of a model. The green deployment uses VMs with a GPU SKU, and runs version 2 of the model. The endpoint is configured to route 90% of incoming traffic to the blue deployment, while the green deployment receives the remaining 10%.
To deploy a model, you must have:
Model files, or the name and version of a model already registered in your workspace.
Scoring script code that executes the model on a given input request.
The scoring script receives data submitted to a deployed web service and passes it to the model. The script then executes the model and returns its response to the client. The scoring script is specific to your model and must understand the data that the model expects as input and returns as output.
An environment to run your model. The environment can be a Docker image with Conda dependencies or a Dockerfile.
Settings to specify the instance type and scaling capacity.
To learn how to deploy online endpoints by using the Azure CLI, Python SDK, Azure Machine Learning studio, or an ARM template, see Deploy a machine learning model by using an online endpoint.
Key attributes of a deployment
The following table describes the key attributes of a deployment:
| Attribute | Description |
|---|---|
| Name | The name of the deployment. |
| Endpoint name | The name of the endpoint to create the deployment under. |
| Model | The model to use for the deployment. This value can be either a reference to an existing versioned model in the workspace or an inline model specification. For more information on how to track and specify the path to your model, see Specify model to deploy for use in online endpoint. |
| Code path | The path to the directory on the local development environment that contains all the Python source code for scoring the model. You can use nested directories and packages. |
| Scoring script | The relative path to the scoring file in the source code directory. This Python code must have an init() function and a run() function. The init() function is called after the model is created or updated, for example to cache the model in memory. The run() function is called at every invocation of the endpoint to do the actual scoring and prediction. |
| Environment | The environment to host the model and code. This value can be either a reference to an existing versioned environment in the workspace or an inline environment specification. |
| Instance type | The VM size to use for the deployment. For the list of supported sizes, see Managed online endpoints SKU list. |
| Instance count | The number of instances to use for the deployment. Base the value on the workload you expect. For high availability, set the value to at least 3. The system reserves an extra 20% for performing upgrades. For more information, see VM quota allocation for deployments. |
Notes for online deployments
The deployment can reference the model and container image defined in Environment at any time, for example when the deployment instances undergo security patches or other recovery operations. If you use a registered model or container image in Azure Container Registry for deployment and later remove the model or the container image, the deployments that rely on these assets can fail when reimaging occurs. If you remove the model or the container image, be sure to recreate or update the dependent deployments with an alternative model or container image.
The container registry that the environment refers to can be private only if the endpoint identity has permission to access it via Microsoft Entra authentication and Azure role-based access control (RBAC). For the same reason, private Docker registries other than Container Registry aren't supported.
Microsoft regularly patches the base images for known security vulnerabilities. You need to redeploy your endpoint to use the patched image. If you provide your own image, you're responsible for updating it. For more information, see Image patching.
VM quota allocation for deployment
For managed online endpoints, Azure Machine Learning reserves 20% of your compute resources for performing upgrades on some VM SKUs. If you request a given number of instances for those VM SKUs in a deployment, you must have a quota for ceil(1.2 * number of instances requested for deployment) * number of cores for the VM SKU available to avoid getting an error. For example, if you request 10 instances of a Standard_DS3_v2 VM (that comes with four cores) in a deployment, you should have a quota for 48 cores (12 instances * 4 cores) available. This extra quota is reserved for system-initiated operations such as OS upgrades and VM recovery, and it won't incur cost unless such operations run.
There are certain VM SKUs that are exempted from extra quota reservation. To view the full list, see Managed online endpoints SKU list. To view your usage and request quota increases, see View your usage and quotas in the Azure portal. To view your cost of running a managed online endpoint, see View costs for a managed online endpoint.
Shared quota pool
Azure Machine Learning provides a shared quota pool from which users across various regions can access quota to perform testing for a limited time, depending upon availability. When you use the studio to deploy Llama-2, Phi, Nemotron, Mistral, Dolly, and Deci-DeciLM models from the model catalog to a managed online endpoint, Azure Machine Learning allows you to access its shared quota pool for a short time so that you can perform testing. For more information on the shared quota pool, see Azure Machine Learning shared quota.
To deploy Llama-2, Phi, Nemotron, Mistral, Dolly, and Deci-DeciLM models from the model catalog by using the shared quota, you must have an Enterprise Agreement subscription.
For more information on quotas and limits for resources in Azure Machine Learning, see Manage and increase quotas and limits for resources with Azure Machine Learning.
Deployment for coders and noncoders
Azure Machine Learning supports model deployment to online endpoints for coders and noncoders by providing options for no-code deployment, low-code deployment, and Bring Your Own Container (BYOC) deployment.
- No-code deployment provides out-of-box inferencing for common frameworks like scikit-learn, TensorFlow, PyTorch, and Open Neural Network Exchange (ONNX) via MLflow and Triton.
- Low-code deployment allows you to provide minimal code along with your machine learning model for deployment.
- BYOC deployment lets you bring virtually any containers to run your online endpoint. You can use all the Azure Machine Learning platform features such as autoscaling, GitOps, debugging, and safe rollout to manage your MLOps pipelines.
The following table highlights key aspects of the online deployment options:
| No-code | Low-code | BYOC | |
|---|---|---|---|
| Summary | Uses out-of-box inferencing for popular frameworks such as scikit-learn, TensorFlow, PyTorch, and ONNX, via MLflow and Triton. For more information, see Deploy MLflow models to online endpoints. | Uses secure, publicly published curated images for popular frameworks, with updates every two weeks to address vulnerabilities. You provide scoring script and/or Python dependencies. For more information, see Azure Machine Learning Curated Environments. | You provide your complete stack via Azure Machine Learning support for custom images. For more information, see Use a custom container to deploy a model to an online endpoint. |
| Custom base image | None. Curated environments provide the base image for easy deployment. | You can use either a curated image or your customized image. | Bring either an accessible container image location like docker.io, Container Registry, or Microsoft Artifact Registry, or a Dockerfile that you can build/push with Container Registry for your container. |
| Custom dependencies | None. Curated environments provide dependencies for easy deployment. | Bring the Azure Machine Learning environment in which the model runs, either a Docker image with Conda dependencies, or a dockerfile. | Custom dependencies are included in the container image. |
| Custom code | None. The scoring script is autogenerated for easy deployment. | Bring your scoring script. | The scoring script is included in the container image. |
Note
AutoML runs create a scoring script and dependencies automatically for users. For no-code deployment, you can deploy any AutoML model without authoring other code. For low-code deployment, you can modify autogenerated scripts to your business needs. To learn how to deploy with AutoML models, see How to deploy an AutoML model to an online endpoint.
Online endpoint debugging
If possible, test-run your endpoint locally to validate and debug your code and configuration before you deploy to Azure. Azure CLI and Python SDK support local endpoints and deployments, while Azure Machine Learning studio and ARM templates don't support local endpoints or deployments.
Azure Machine Learning provides the following ways to debug online endpoints locally and by using container logs:
- Local debugging with Azure Machine Learning inference HTTP server
- Local debugging with local endpoint
- Local debugging with local endpoint and Visual Studio Code
- Debugging with container logs
Local debugging with Azure Machine Learning inference HTTP server
You can debug your scoring script locally by using the Azure Machine Learning inference HTTP server. The HTTP server is a Python package that exposes your scoring function as an HTTP endpoint and wraps the Flask server code and dependencies into a single package.
Azure Machine Learning includes an HTTP server in the prebuilt Docker images for inference used to deploy a model. By using the package alone, you can deploy the model locally for production, and you can also easily validate your entry scoring script in a local development environment. If there's a problem with the scoring script, the server returns an error and the location where the error occurred. You can also use Visual Studio Code to debug with the Azure Machine Learning inference HTTP server.
Tip
You can use the Azure Machine Learning inference HTTP server Python package to debug your scoring script locally without Docker Engine. Debugging with the inference server helps you to debug the scoring script before deploying to local endpoints, so you can debug without being affected by the deployment container configurations.
For more information about debugging with the HTTP server, see Debug scoring script with Azure Machine Learning inference HTTP server.
Local debugging with local endpoint
For local debugging, you need a model deployed to a local Docker environment. You can use this local deployment for testing and debugging before deployment to the cloud.
To deploy locally, you need the Docker Engine installed and running. Azure Machine Learning then creates a local Docker image to mimic the online image. Azure Machine Learning builds and runs deployments for you locally and caches the image for rapid iterations.
Tip
If Docker Engine doesn't start when the computer starts, you can troubleshoot Docker Engine. You can use client-side tools such as Docker Desktop to debug what happens in the container.
Local debugging typically involves the following steps:
- First, check that the local deployment succeeded.
- Next, invoke the local endpoint for inferencing.
- Finally, review the output logs for the
invokeoperation.
Local endpoints have the following limitations:
No support for traffic rules, authentication, or probe settings.
Support for only one deployment per endpoint.
Support for local model files and environment with local conda file only.
For more information about local debugging, see Deploy and debug locally by using a local endpoint.
Local debugging with local endpoint and Visual Studio Code (preview)
Important
This feature is currently in public preview. This preview version is provided without a service-level agreement, and we don't recommend it for production workloads. Certain features might not be supported or might have constrained capabilities.
For more information, see Supplemental Terms of Use for Azure Previews.
As with local debugging, you need to have the Docker Engine installed and running, and then deploy a model to the local Docker environment. Once you have a local deployment, Azure Machine Learning local endpoints use Docker and Visual Studio Code development containers (dev containers) to build and configure a local debugging environment.
With dev containers, you can use Visual Studio Code features such as interactive debugging from inside a Docker container. For more information about interactively debugging online endpoints in Visual Studio Code, see Debug online endpoints locally in Visual Studio Code.
Debugging with container logs
You can't get direct access to a VM where a model deploys, but you can get logs from the following containers that are running on the VM:
- The inference server console log contains the output of print/logging functions from your scoring script score.py code.
- Storage initializer logs contain information on whether code and model data successfully downloaded to the container. The container runs before the inference server container starts to run.
For more information about debugging with container logs, see Get container logs.
Traffic routing and mirroring to online deployments
A single online endpoint can have multiple deployments. As the endpoint receives incoming traffic requests, it can route percentages of traffic to each deployment, as in the native blue/green deployment strategy. The endpoint can also mirror or copy traffic from one deployment to another, called traffic mirroring or shadowing.
Traffic routing for blue/green deployment
Blue/green deployment is a deployment strategy that lets you roll out a new green deployment to a small subset of users or requests before rolling it out completely. The endpoint can implement load balancing to allocate certain percentages of the traffic to each deployment, with the total allocation across all deployments adding up to 100%.
Tip
A request can bypass the configured traffic load balancing by including an HTTP header of azureml-model-deployment. Set the header value to the name of the deployment you want the request to route to.
The following image shows settings in Azure Machine Learning studio for allocating traffic between a blue and green deployment.
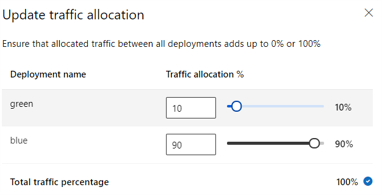
The preceding traffic allocation routes 10% of the traffic to the green deployment and 90% of the traffic to the blue deployment, as shown in the following image.
Traffic mirroring to online deployments
The endpoint can also mirror or copy traffic from one deployment to another. You can use traffic mirroring, also called shadow testing, when you want to test a new deployment with production traffic without impacting the results that customers receive from existing deployments.
For example, you can implement a blue/green deployment where 100% of the traffic is routed to blue and 10% is mirrored to the green deployment. The results of the mirrored traffic to the green deployment aren't returned to the clients, but the metrics and logs are recorded.
For more information about how to use traffic mirroring, see Perform safe rollout of new deployments for real-time inference.
More online endpoint capabilities
The following sections describe other capabilities of Azure Machine Learning online endpoints.
Authentication and encryption
- Authentication: Key and Azure Machine Learning tokens
- Managed identity: User assigned and system assigned
- Secure socket layer (SSL) by default for endpoint invocation
Autoscaling
Autoscale automatically runs the right amount of resources to handle the load on your application. Managed endpoints support autoscaling through integration with the Azure Monitor autoscale feature. You can configure metrics-based scaling such as CPU utilization >70%, schedule-based scaling such as peak business hour rules, or both.

For more information, see Autoscale online endpoints in Azure Machine Learning.
Managed network isolation
When you deploy a machine learning model to a managed online endpoint, you can secure communication with the online endpoint by using private endpoints. You can configure security for inbound scoring requests and outbound communications separately.
Inbound communications use the private endpoint of the Azure Machine Learning workspace, while outbound communications use private endpoints created for the workspace's managed virtual network. For more information, see Network isolation with managed online endpoints.
Monitoring online endpoints and deployments
Azure Machine Learning endpoints integrate with Azure Monitor. Azure Monitor integration lets you view metrics in charts, configure alerts, query log tables, and use Application Insights to analyze events from user containers. For more information, see Monitor online endpoints.
Secret injection in online deployments (preview)
Secret injection for an online deployment involves retrieving secrets such as API keys from secret stores and injecting them into the user container that runs inside the deployment. To provide secure secret consumption for the inference server that runs your scoring script or the inferencing stack in your BYOC deployment, you can use environment variables to access secrets.
You can inject secrets yourself by using managed identities or you can use the secret injection feature. For more information, see Secret injection in online endpoints (preview).
Related content
- Deploy and score a machine learning model by using an online endpoint
- Batch endpoints
- Secure your managed online endpoints with network isolation
- Deploy models with REST
- Monitor online endpoints
- View costs for an Azure Machine Learning managed online endpoint
- Manage and increase quotas and limits for resources with Azure Machine Learning