Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
A batch run executes a prompt flow with a large dataset and generates outputs for each data row. To evaluate how well your prompt flow performs with a large dataset, you can submit a batch run and use evaluation methods to generate performance scores and metrics.
After the batch flow completes, the evaluation methods automatically execute to calculate the scores and metrics. You can use the evaluation metrics to assess the output of your flow against your performance criteria and goals.
This article describes how to submit a batch run and use an evaluation method to measure the quality of your flow output. You learn how to view the evaluation result and metrics, and how to start a new round of evaluation with a different method or subset of variants.
Prerequisites
To run a batch flow with an evaluation method, you need the following components:
A working Azure Machine Learning prompt flow that you want to test performance for.
A test dataset to use for the batch run.
Your test dataset must be in CSV, TSV, or JSONL format, and should have headers that match the input names of your flow. However, you can map different dataset columns to input columns during the evaluation run setup process.
Create and submit an evaluation batch run
To submit a batch run, you select the dataset to test your flow with. You can also select an evaluation method to calculate metrics for your flow output. If you don't want to use an evaluation method, you can skip the evaluation steps and run the batch run without calculating any metrics. You can also run an evaluation round later.
To start a batch run with or without evaluation, select Evaluate at the top of your prompt flow page.
On the Basic settings page of the Batch run & Evaluate wizard, customize the Run display name if desired and optionally provide a Run description and Tags. Select Next.
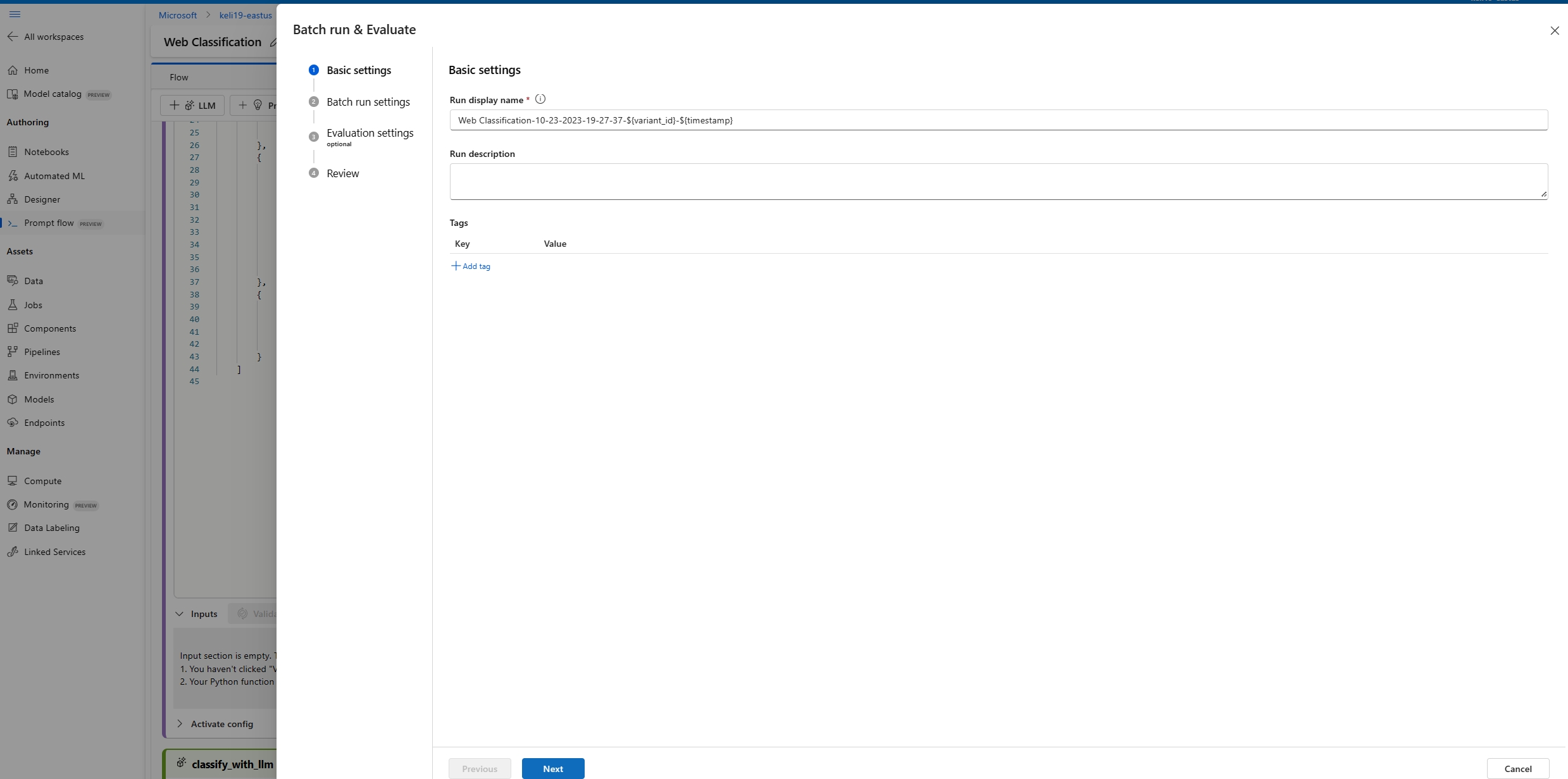
On the Batch run settings page, select the dataset to use and configure input mapping.
Prompt flow supports mapping your flow input to a specific data column in your dataset. You can assign a dataset column to a certain input by using
${data.<column>}. If you want to assign a constant value to an input, you can enter that value directly.
You can select Review + submit at this point to skip the evaluation steps and run the batch run without using any evaluation method. The batch run then generates individual outputs for each item in your dataset. You can check the outputs manually or export them for further analysis.
Otherwise, to use an evaluation method to validate the performance of this run, select Next. You can also add a new round of evaluation to a completed batch run.
On the Select evaluation page, select one or more customized or built-in evaluations to run. You can select View details button to see more information about the evaluation method, such as the metrics it generates and the connections and inputs it requires.
Next, on the Configure evaluation screen, specify the sources of required inputs for the evaluation. For example, the ground truth column might come from a dataset. By default, evaluation uses the same dataset as the overall batch run. However, if the corresponding labels or target ground truth values are in a different dataset, you can use that one.
Note
If your evaluation method doesn't require data from a dataset, dataset selection is an optional configuration that doesn't affect evaluation results. You don't need to select a dataset, or reference any dataset columns in the input mapping section.
In the Evaluation input mapping section, indicate the sources of required inputs for the evaluation.
- If the data is from your test dataset, set the source as
${data.[ColumnName]}. - If the data is from your run output, set the source as
${run.outputs.[OutputName]}.
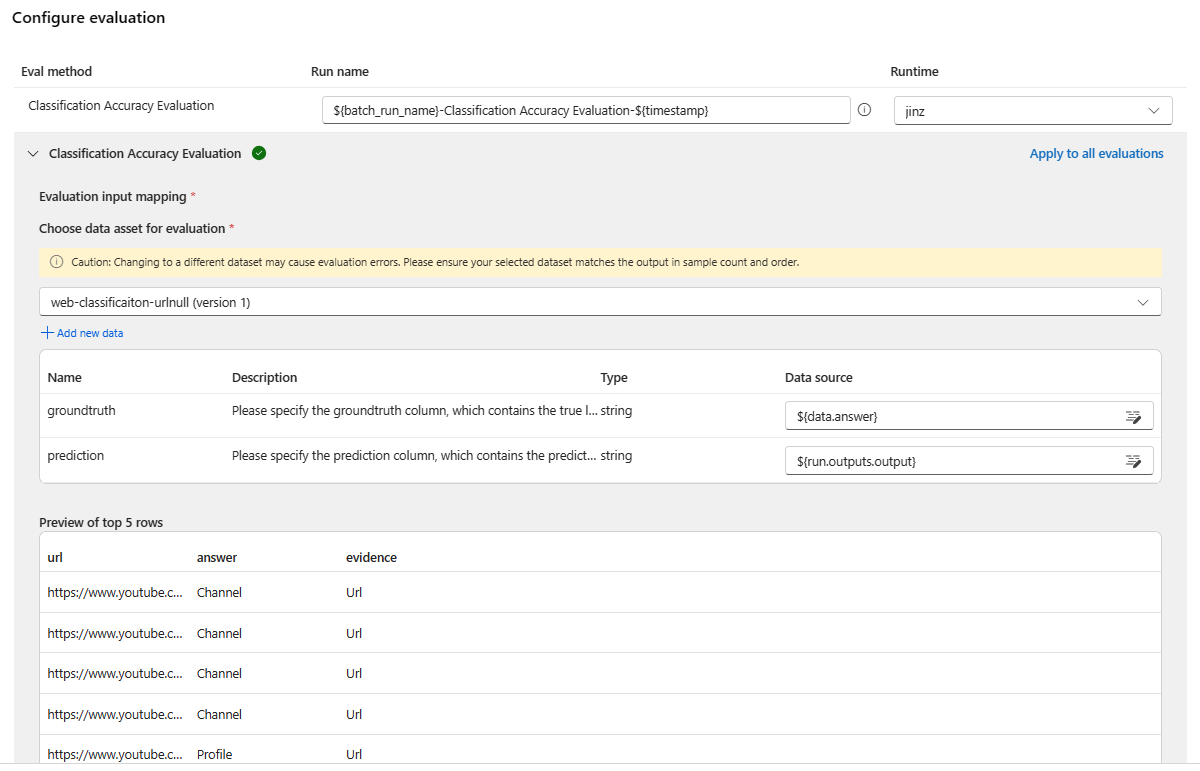
- If the data is from your test dataset, set the source as
Some evaluation methods require Large Language Models (LLMs) like GPT-4 or GPT-3.5, or need other connections to consume credentials or keys. For those methods, you must enter the connection data in the Connection section at the bottom of this screen to be able to use the evaluation flow.

Select Review + submit to review your settings, and then select Submit to start the batch run with evaluation.






Note
- Some evaluation processes use many tokens, so it's recommended to use a model that can support >=16k tokens.
- Batch runs have a maximum duration of 10 hours. If a batch run exceeds this limit, it terminates and shows as failed. Monitor your LLM capacity to avoid throttling. If necessary, consider reducing the size of your data. If you still have issues, file a feedback form or support request.
View evaluation results and metrics
You can find the list of submitted batch runs on the Runs tab in the Azure Machine Learning studio Prompt flow page.
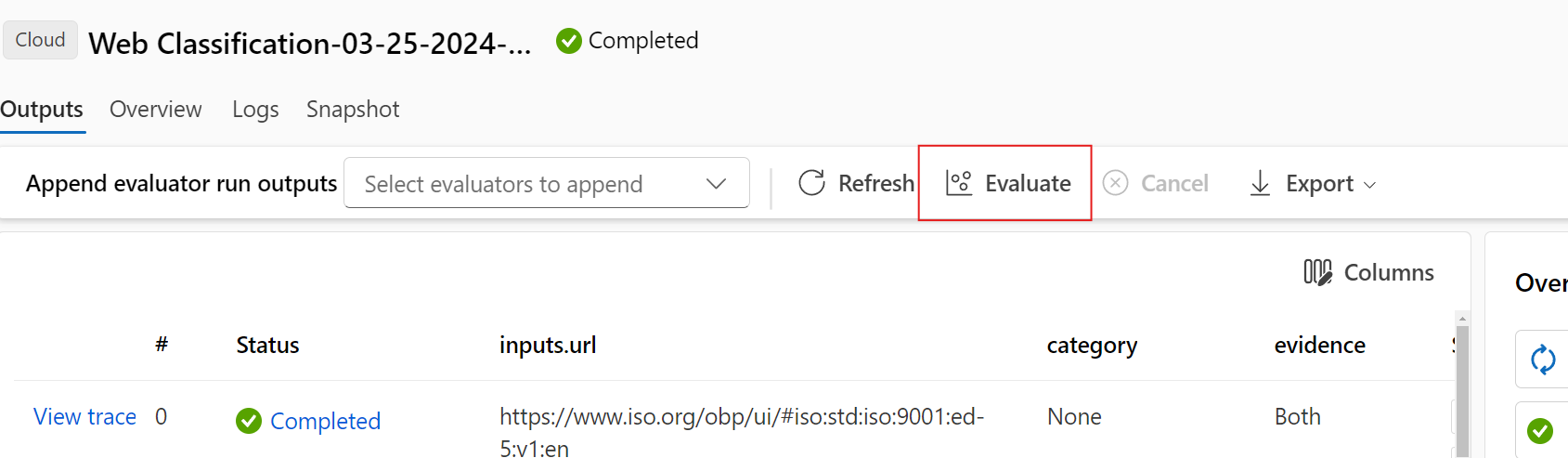
To check the results of a batch run, select the run and then select Visualize outputs.
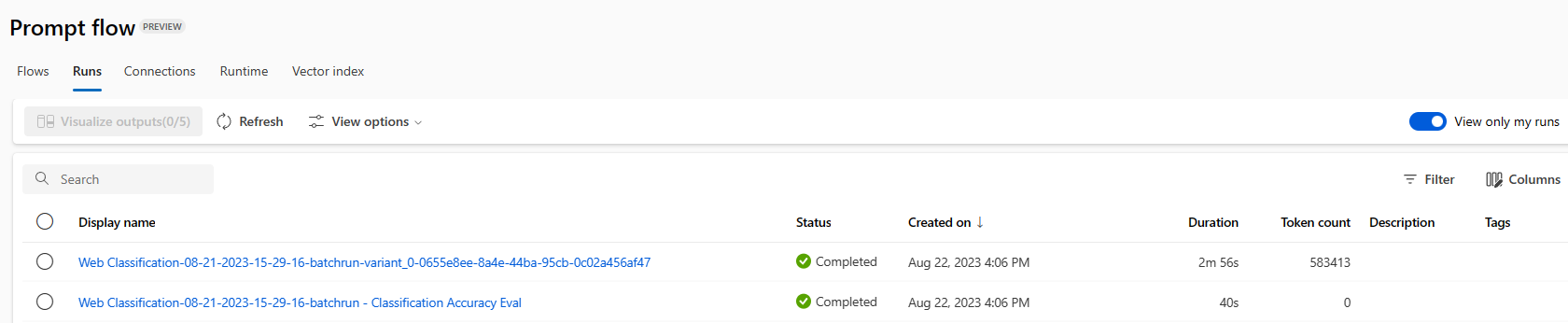
On the Visualize outputs screen, the Runs & metrics section shows overall results for the batch run and the evaluation run. The Outputs section shows the run inputs line by line in a results table that also includes line ID, Run, Status, and System metrics.
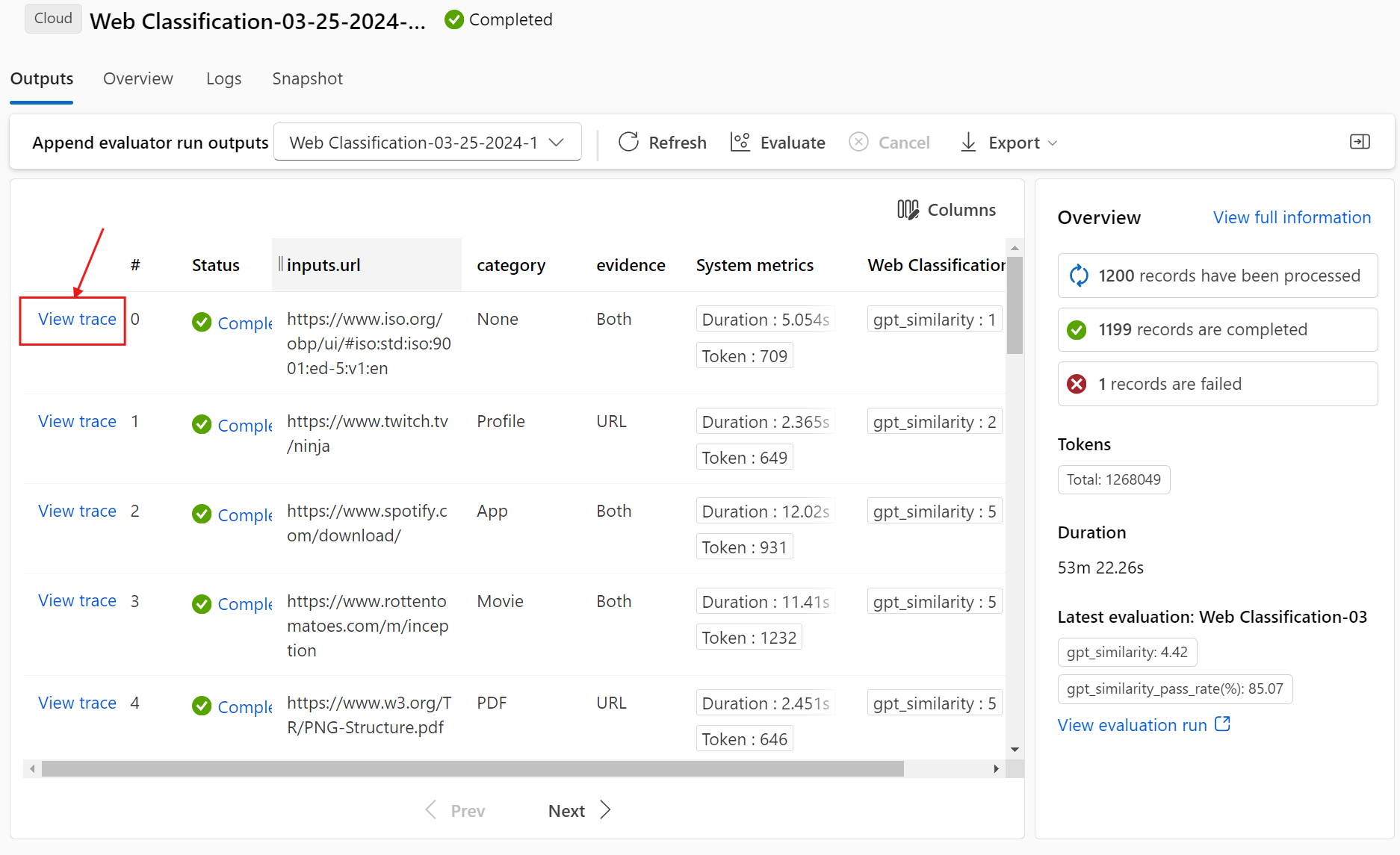
If you enable the View icon next to the evaluation run in the Runs & metrics section, the Outputs table also shows the evaluation score or grade for each line.
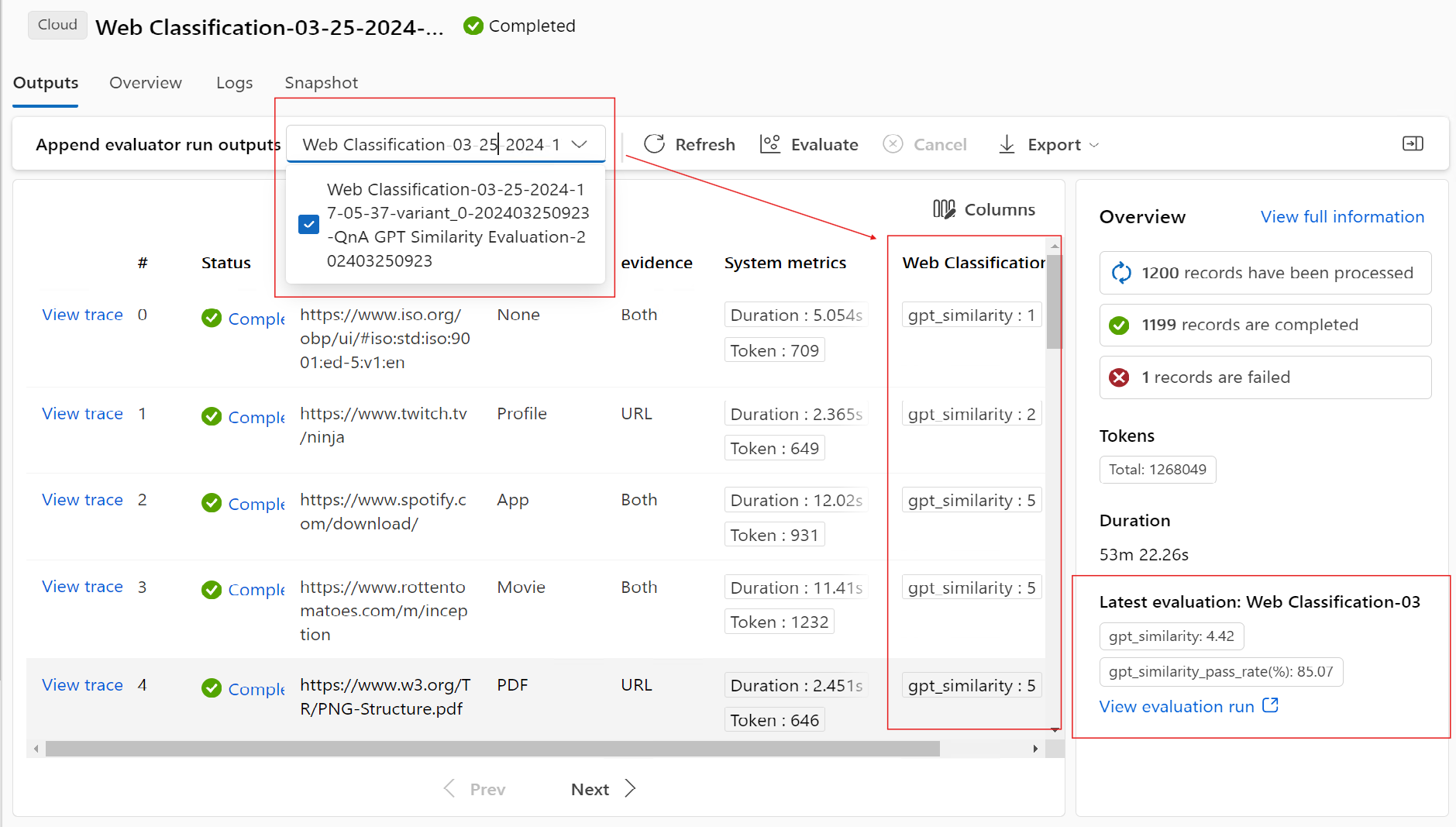
Select the View details icon next to each line in the Outputs table to observe and debug the Trace view and Details for that test case. The Trace view shows information such as number of Tokens and duration for that case. Expand and select any step to see the Overview and Inputs for that step.




You can also view evaluation run results from the prompt flow you tested. Under View batch runs, select View batch runs to see the list of batch runs for the flow, or select View latest batch run outputs to see the outputs for the latest run.

In the batch run list, select a batch run name to open the flow page for that run.
On the flow page for an evaluation run, select View outputs or Details to see details for the flow. You can also Clone the flow to create a new flow, or Deploy it as an online endpoint.

On the Details screen:
The Overview tab shows comprehensive information about the run, including run properties, input dataset, output dataset, tags, and description.
The Outputs tab shows a summary of results at the top of the page, followed by the batch run results table. If you select the evaluation run next to Append related results, the table also shows the evaluation run results.
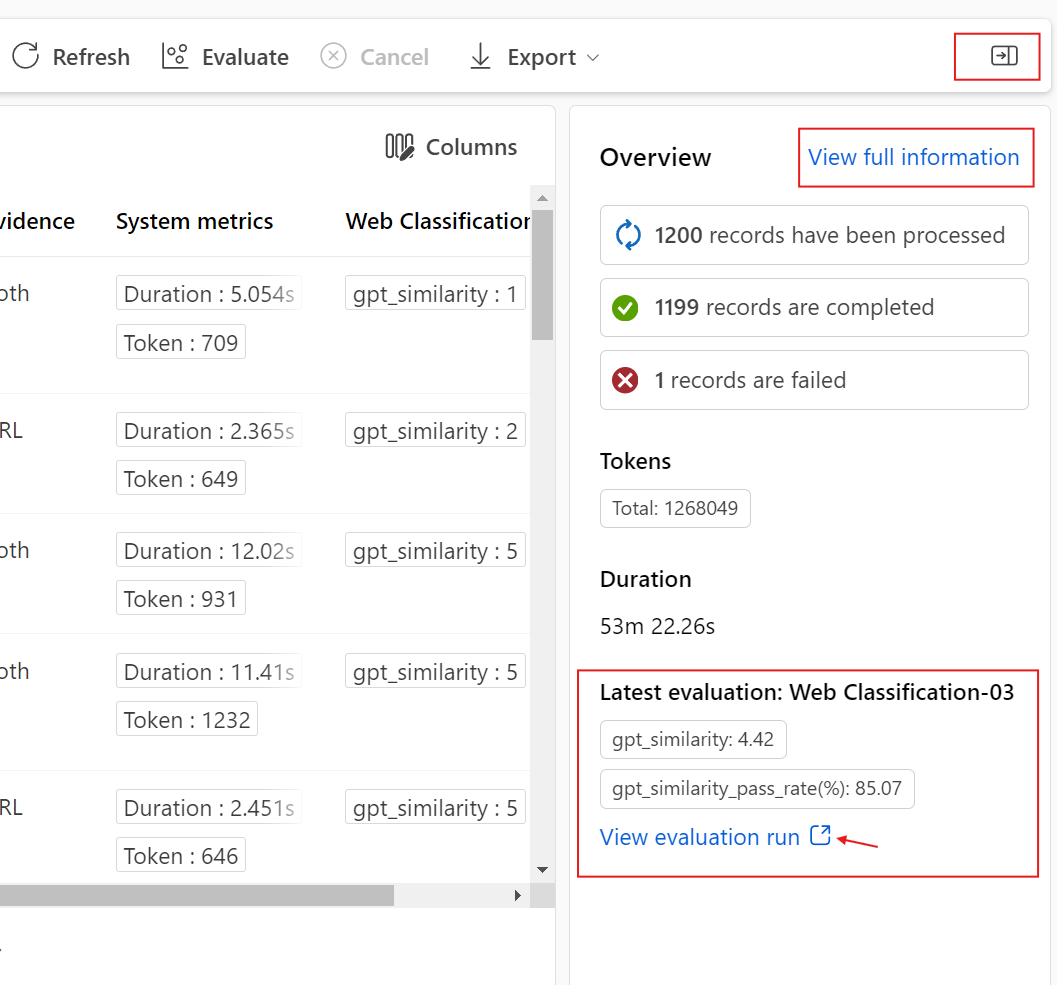
The Logs tab shows the run logs, which can be useful for detailed debugging of execution errors. You can download the log files.
The Metrics tab provides a link to the metrics for the run.
The Trace tab shows detailed information such as number of Tokens and duration for each test case. Expand and select any step to see the Overview and Inputs for that step.
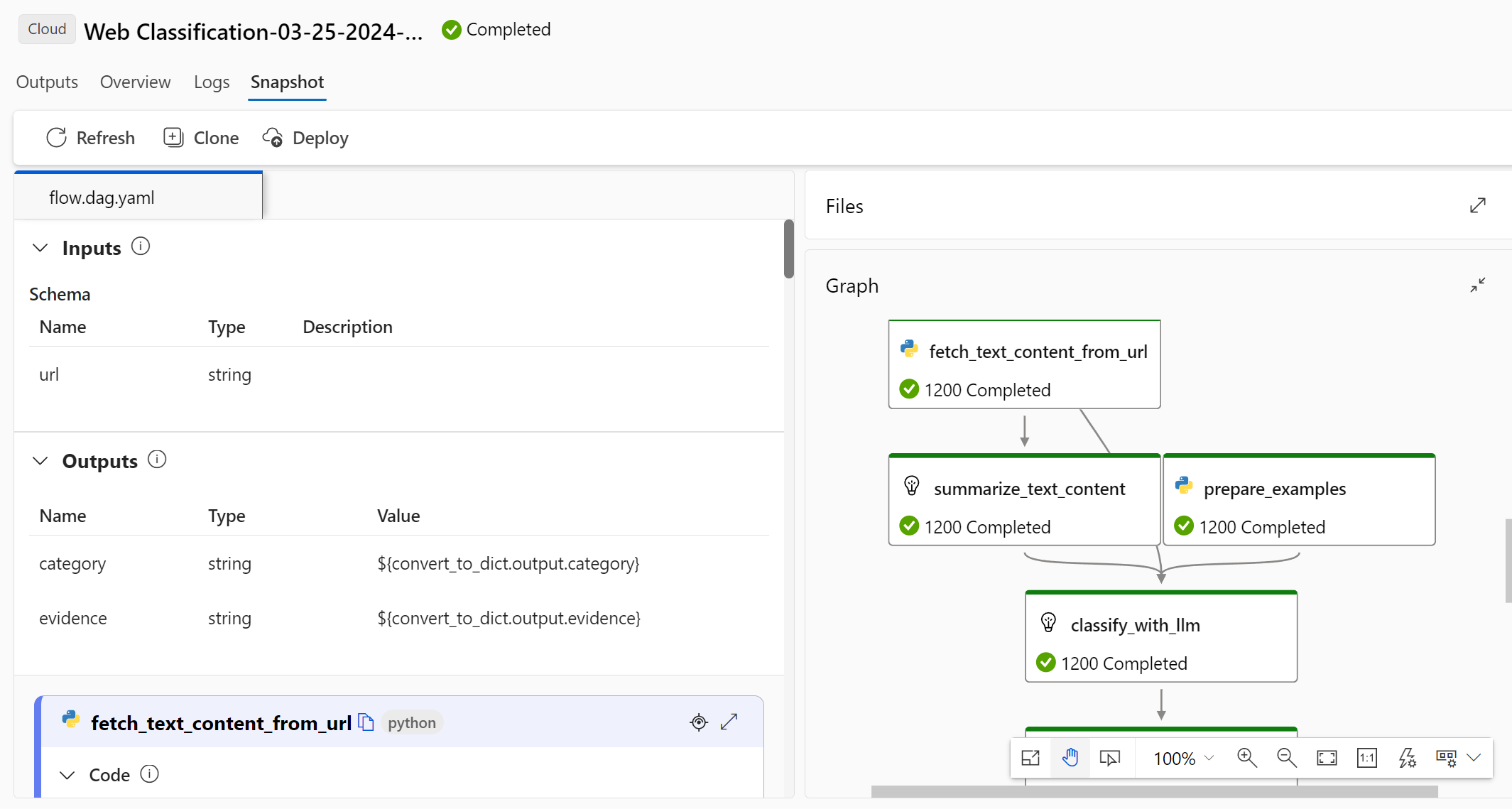
The Snapshot tab shows the files and code from the run. You can see the flow.dag.yaml flow definition and download any of the files.


Start a new evaluation round for the same run
You can run a new evaluation round to calculate metrics for a completed batch run without running the flow again. This process saves the cost of rerunning your flow and is helpful in the following scenarios:
- You didn't select an evaluation method when you submitted a batch run, and now want to evaluate run performance.
- You used an evaluation method to calculate a certain metric, and now want to calculate a different metric.
- Your previous evaluation run failed, but the batch run successfully generated outputs and you want to try the evaluation again.
To start another round of evaluation, select Evaluate at the top of the batch run flow page. The New evaluation wizard opens to the Select evaluation screen. Complete the setup and submit the new evaluation run.
The new run appears in the prompt flow Run list, and you can select more than one row in the list and then select Visualize outputs to compare the outputs and metrics.
Compare evaluation run history and metrics
If you modify your flow to improve its performance, you can submit multiple batch runs to compare the performance of the different flow versions. You can also compare the metrics calculated by different evaluation methods to see which method is more suitable for your flow.
To check your flow batch run history, select View batch runs at the top of your flow page. You can select each run to check the details. You can also select multiple runs and select Visualize outputs to compare the metrics and the outputs of those runs.

Understand built-in evaluation metrics
Azure Machine Learning prompt flow provides several built-in evaluation methods to help you measure the performance of your flow output. Each evaluation method calculates different metrics. The following table describes the available built-in evaluation methods.
| Evaluation method | Metric | Description | Connection required? | Required input | Score values |
|---|---|---|---|---|---|
| Classification Accuracy Evaluation | Accuracy | Measures the performance of a classification system by comparing its outputs to ground truth | No | prediction, ground truth | In the range [0, 1] |
| QnA Groundedness Evaluation | Groundedness | Measures how grounded the model's predicted answers are in the input source. Even if the LLM responses are accurate, they're ungrounded if they're not verifiable against source. | Yes | question, answer, context (no ground truth) | 1 to 5, with 1 = worst and 5 = best |
| QnA GPT Similarity Evaluation | GPT Similarity | Measures similarity between user-provided ground truth answers and the model predicted answer using a GPT model | Yes | question, answer, ground truth (context not needed) | 1 to 5, with 1 = worst and 5 = best |
| QnA Relevance Evaluation | Relevance | Measures how relevant the model's predicted answers are to the questions asked | Yes | question, answer, context (no ground truth) | 1 to 5, with 1 = worst and 5 = best |
| QnA Coherence Evaluation | Coherence | Measures the quality of all sentences in a model's predicted answer and how they fit together naturally | Yes | question, answer (no ground truth or context) | 1 to 5, with 1 = worst and 5 = best |
| QnA Fluency Evaluation | Fluency | Measures the grammatical and linguistic correctness of the model's predicted answer | Yes | question, answer (no ground truth or context) | 1 to 5, with 1 = worst and 5 = best |
| QnA F1 Scores Evaluation | F1 score | Measures the ratio of the number of shared words between the model prediction and the ground truth | No | question, answer, ground truth (context not needed) | In the range [0, 1] |
| QnA Ada Similarity Evaluation | Ada Similarity | Computes sentence (document) level embeddings using Ada embeddings API for both ground truth and prediction, then computes cosine similarity between them (one floating point number) | Yes | question, answer, ground truth (context not needed) | In the range [0, 1] |
Improve flow performance
If your run fails, check the output and log data and debug any flow failure. To fix the flow or improve performance, try modifying the flow prompt, system message, flow parameters, or flow logic.