Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Note
Knowledge stores are secondary storage that exists in Azure Storage and contain the outputs of Azure AI Search skillsets. They're separate from knowledge sources and knowledge bases, which are used in agentic retrieval workflows.
Knowledge store is secondary storage for AI-enriched content created by a skillset in Azure AI Search. In Azure AI Search, an indexing job always sends output to a search index, but if you attach a skillset to an indexer, you can optionally also send AI-enriched output to a container or table in Azure Storage. A knowledge store can be used for independent analysis or downstream processing in non-search scenarios like knowledge mining.
The two outputs of indexing, a search index and knowledge store, are mutually exclusive products of the same pipeline. They're derived from the same inputs and contain the same data, but their content is structured, stored, and used in different applications.

Physically, a knowledge store is Azure Storage, either Azure Table Storage, Azure Blob Storage, or both. Any tool or process that can connect to Azure Storage can consume the contents of a knowledge store. There's no query support in Azure AI Search for retrieving content from a knowledge store.
When viewed through Azure portal, a knowledge store looks like any other collection of tables, objects, or files. The following screenshot shows a knowledge store composed of three tables. You can adopt a naming convention, such as a kstore prefix, to keep your content together.
Benefits of knowledge store
The primary benefits of a knowledge store are two-fold: flexible access to content, and the ability to shape data.
Unlike a search index that can only be accessed through queries in Azure AI Search, a knowledge store is accessible to any tool, app, or process that supports connections to Azure Storage. This flexibility opens up new scenarios for consuming the analyzed and enriched content produced by an enrichment pipeline.
The same skillset that enriches data can also be used to shape data. Some tools like Power BI work better with tables, whereas a data science workload might require a complex data structure in a blob format. Adding a Shaper skill to a skillset gives you control over the shape of your data. You can then pass these shapes to projections, either tables or blobs, to create physical data structures that align with the data's intended use.
Knowledge store definition
A knowledge store is defined inside a skillset definition and it has two components:
A connection string to Azure Storage
Projections that determine whether the knowledge store consists of tables, objects or files. The projections element is an array. You can create multiple sets of table-object-file combinations within one knowledge store.
"knowledgeStore": { "storageConnectionString":"<YOUR-AZURE-STORAGE-ACCOUNT-CONNECTION-STRING>", "projections":[ { "tables":[ ], "objects":[ ], "files":[ ] } ] }
The type of projection you specify in this structure determines the type of storage used by knowledge store, but not its structure. Fields in tables, objects, and files are determined by Shaper skill output if you're creating the knowledge store programmatically, or by the Import data wizard if you're using the Azure portal.
tablesproject enriched content into Table Storage. Define a table projection when you need tabular reporting structures for inputs to analytical tools or export as data frames to other data stores. You can specify multipletableswithin the same projection group to get a subset or cross section of enriched documents. Within the same projection group, table relationships are preserved so that you can work with all of them.Projected content isn't aggregated or normalized. The following screenshot shows a table, sorted by key phrase, with the parent document indicated in the adjacent column. In contrast with data ingestion during indexing, there's no linguistic analysis or aggregation of content. Plural forms and differences in casing are considered unique instances.
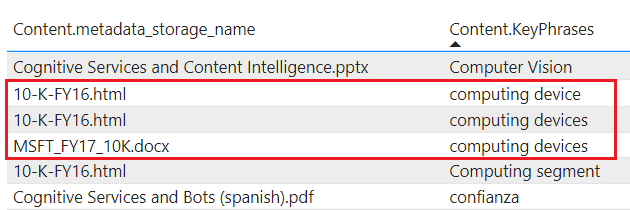
objectsproject JSON document into Blob storage. The physical representation of anobjectis a hierarchical JSON structure that represents an enriched document.filesproject image files into Blob storage. Afileis an image extracted from a document, transferred intact to Blob storage. Although it's named "files", it shows up in Blob Storage, not file storage.
Create a knowledge store
Use the Azure portal, REST APIs, or an Azure SDK package to create a knowledge store. All methods require Azure Storage, a skillset, and an indexer. Because indexers require a search index, you must also provide an index definition.
REST APIs and SDKs provide full control over projections: tables, objects, and files. The Azure portal creates a knowledge store automatically as part of the multimodal RAG workflow, which is limited to file projections for extracted images.
The Import data wizard creates a knowledge store only for the multimodal RAG scenario. To get started, see Quickstart: Multimodal search in the Azure portal.
Connect with apps
Once enriched content exists in storage, any tool or technology that connects to Azure Storage can be used to explore, analyze, or consume the contents. The following list is a start:
Storage Explorer or Storage browser in the Azure portal to view enriched document structure and content. Consider this as your baseline tool for viewing knowledge store contents.
Power BI for reporting and analysis.
Azure Data Factory for further manipulation.
Content lifecycle
Each time you run the indexer and skillset, the knowledge store is updated if the skillset or underlying source data has changed. Any changes picked up by the indexer are propagated through the enrichment process to the projections in the knowledge store, ensuring that your projected data is a current representation of content in the originating data source.
Note
While you can edit the data in the projections, any edits will be overwritten on the next pipeline invocation, assuming the document in source data is updated.
Changes in source data
For data sources that support change tracking, an indexer will process new and changed documents, and bypass existing documents that have already been processed. Timestamp information varies by data source, but in a blob container, the indexer looks at the lastmodified date to determine which blobs need to be ingested.
Changes to a skillset
If you're making changes to a skillset, you should enable caching of enriched documents to reuse existing enrichments where possible.
Without incremental caching, the indexer will always process documents in order of the high water mark, without going backwards. For blobs, the indexer would process blobs sorted by lastModified, regardless of any changes to indexer settings or the skillset. If you change a skillset, previously processed documents aren't updated to reflect the new skillset. Documents processed after the skillset change will use the new skillset, resulting in index documents being a mix of old and new skillsets.
With incremental caching, and after a skillset update, the indexer will reuse any enrichments that are unaffected by the skillset change. Upstream enrichments are pulled from cache, as are any enrichments that are independent and isolated from the skill that was changed.
Deletions
Although an indexer creates and updates structures and content in Azure Storage, it doesn't delete them. Projections continue to exist even when the indexer or skillset is deleted. As the owner of the storage account, you should delete a projection if it's no longer needed.
Next steps
Knowledge store offers persistence of enriched documents, useful when designing a skillset, or the creation of new structures and content for consumption by any client applications capable of accessing an Azure Storage account.
The simplest approach for creating enriched documents programmatically is through REST APIs.