Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
If you're building a query for full text search, this article provides steps for setting up the request. It also introduces a query structure, and explains how field attributes and linguistic analyzers can affect query outcomes.
Prerequisites
An Azure AI Search service (any tier). Create a service or find an existing one.
A search index with string fields attributed as searchable. You can also use an index alias as the endpoint of your query request.
Permissions to query the index:
- Key-based authentication: A query API key for your search service.
- Role-based authentication: Search Index Data Reader role.
For SDK development, install the Azure Search client library:
- Python: azure-search-documents
- .NET: Azure.Search.Documents
- JavaScript: @azure/search-documents
- Java: azure-search-documents
Tip
For a quick code example, skip to Example of a full text query request.
Example of a full text query request
In Azure AI Search, a query is a read-only request against the docs collection of a single search index, with parameters that both inform query execution and shape the response coming back.
A full text query is specified in a search parameter and consists of terms, quote-enclosed phrases, and operators. Other parameters add more definition to the request.
The following Search POST REST API call illustrates a query request using search and other parameters.
POST https://[service name].search.azure.cn/indexes/hotels-sample/docs/search?api-version=2026-04-01
{
"search": "NY +view",
"queryType": "simple",
"searchMode": "all",
"searchFields": "HotelName, Description, Address/City, Address/StateProvince, Tags",
"select": "HotelName, Description, Address/City, Address/StateProvince, Tags",
"top": 10,
"count": true
}
Reference: Search POST
Key points
searchprovides the match criteria, usually whole terms or phrases, with or without operators. Any field that is attributed as searchable in the index schema is within scope for a search operation.queryTypesets the parser: simple, full. The default simple query parser is optimal for full text search. The full Lucene query parser is for advanced query constructs like regular expressions, proximity search, fuzzy and wildcard search. This parameter can also be set to semantic for semantic ranking for advanced semantic modeling on the query response.searchModespecifies whether matches are based on all criteria (favors precision) or any criteria (favors recall) in the expression. The default is any. If you anticipate heavy use of Boolean operators, which is more likely in indexes that contain large text blocks (a content field or long descriptions), be sure to test queries with thesearchMode=Any|Allparameter to evaluate the impact of that setting on Boolean search.searchFieldsconstrains query execution to specific searchable fields. During development, it's helpful to use the same field list for select and search. Otherwise a match might be based on field values that you can't see in the results, creating uncertainty as to why the document was returned.
Parameters used to shape the response:
selectspecifies which fields to return in the response. Only fields marked as retrievable in the index can be used in a select statement.topreturns the specified number of best-matching documents. In this example, only 10 hits are returned. You can use top and skip (not shown) to page the results.counttells you how many documents in the entire index match overall, which can be more than what are returned. Valid values are "true" or "false". Defaults to "false". Count is accurate if the index is stable, but will under or over-report any documents that are actively added, updated, or deleted. If you'd like to get only the count without any documents, you can use $top=0.orderbyis used if you want to sort results by a value, such as a rating or location. Otherwise, the default is to use the relevance score to rank results. A field must be attributed as sortable to be a candidate for this parameter.
Choose a client
For early development and proof-of-concept testing, start with the Azure portal or a REST client or a Jupyter notebook. These approaches are interactive, useful for targeted testing, and help you assess the effects of different properties without having to write any code.
To call search from within an app, use the Azure.Document.Search client libraries in the Azure SDKs for .NET, Java, JavaScript, and Python.
In the Azure portal, when you open an index, you can work with Search Explorer alongside the index JSON definition in side-by-side tabs for easy access to field attributes. Check the Fields table to see which ones are searchable, sortable, filterable, and facetable while testing queries.
Sign in to the Azure portal and find your search service.
In your service, select Indexes and choose an index.
An index opens to the Search explorer tab so that you can query right away. Switch to JSON view to specify query syntax.
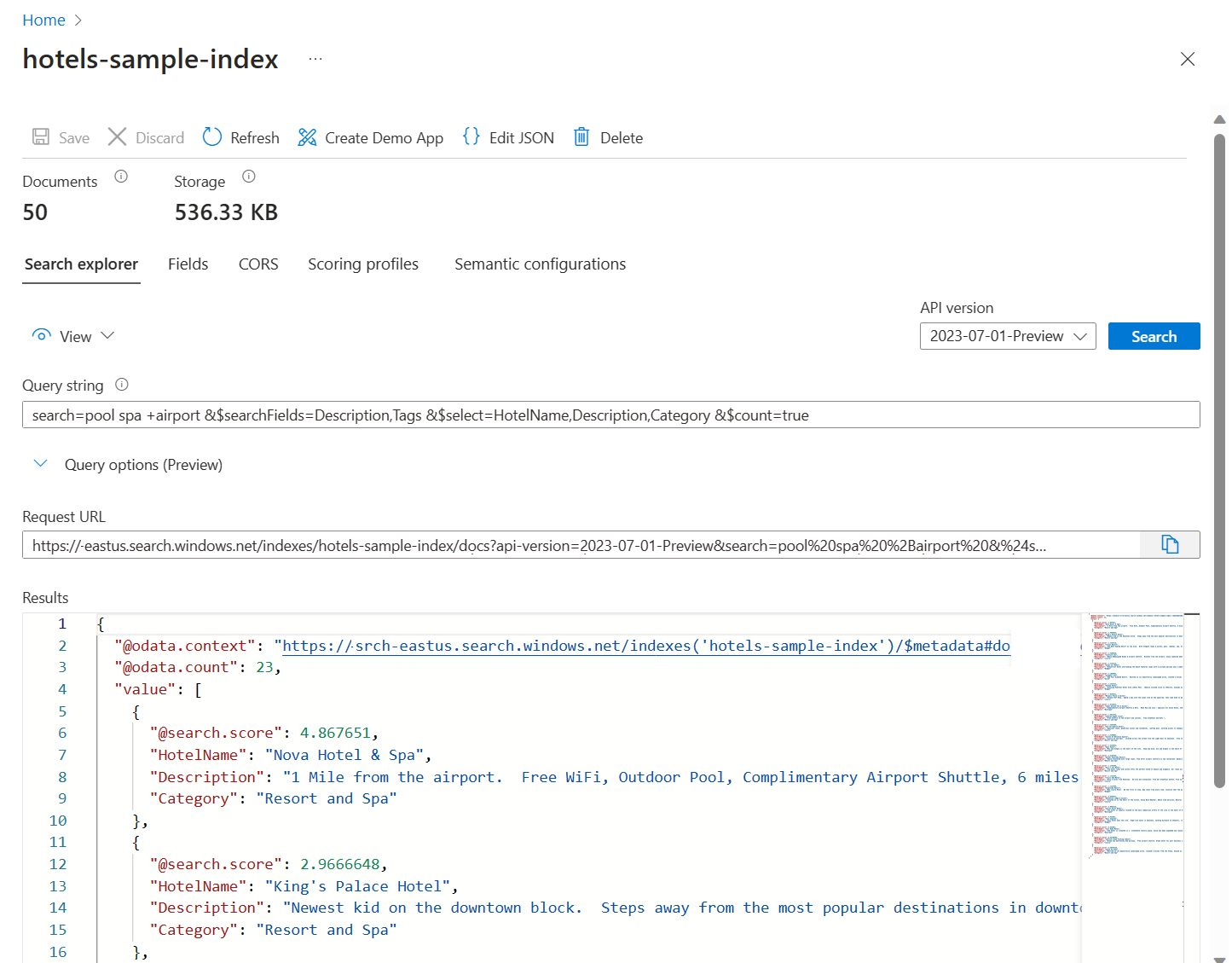
Here's a full text search query expression that works for the hotels-sample index:
{ "search": "pool spa +airport", "queryType": "simple", "searchMode": "any", "searchFields": "Description, Tags", "select": "HotelName, Description, Tags", "top": 10, "count": true }Reference: Search POST
The following screenshot illustrates the query and response:
Choose a query type: simple | full
If your query is full text search, a query parser is used to process any text that's passed as search terms and phrases. Azure AI Search offers two query parsers.
The simple parser understands the simple query syntax. This parser was selected as the default for its speed and effectiveness in free form text queries. The syntax supports common search operators (AND, OR, NOT) for term and phrase searches, and prefix (
*) search (as insea*for Seattle and Seaside). A general recommendation is to try the simple parser first, and then move on to full parser if application requirements call for more powerful queries.The full Lucene query syntax, enabled when you add
queryType=fullto the request, is based on the Apache Lucene Parser.
Full syntax and simple syntax overlap to the extent that both support the same prefix and Boolean operations, but the full syntax provides more operators. In full, there are more operators for Boolean expressions, and more operators for advanced queries such as fuzzy search, wildcard search, proximity search, and regular expressions.
Choose query methods
Search is fundamentally a user-driven exercise, where terms or phrases are collected from a search box, or from click events on a page. The following table summarizes the mechanisms by which you can collect user input, along with the expected search experience.
| Input | Experience |
|---|---|
| Search method | A user types the terms or phrases into a search box, with or without operators, and selects Search to send the request. Search can be used with filters on the same request, but not with autocomplete or suggestions. |
| Autocomplete method | A user types a few characters, and queries are initiated after each new character is typed. The response is a completed string from the index. If the string provided is valid, the user selects Search to send that query to the service. |
| Suggestions method | As with autocomplete, a user types a few characters and incremental queries are generated. The response is a dropdown list of matching documents, typically represented by a few unique or descriptive fields. If any of the selections are valid, the user selects one and the matching document is returned. |
| Faceted navigation | A page shows clickable navigation links or breadcrumbs that narrow the scope of the search. A faceted navigation structure is composed dynamically based on an initial query. For example, search=* to populate a faceted navigation tree composed of every possible category. A faceted navigation structure is created from a query response, but it's also a mechanism for expressing the next query. n REST API reference, facets is documented as a query parameter of a Search Documents operation, but it can be used without the search parameter. |
| Filter method | Filters are used with facets to narrow results. You can also implement a filter behind the page, for example to initialize the page with language-specific fields. In REST API reference, $filter is documented as a query parameter of a Search Documents operation, but it can be used without the search parameter. |
Effect of field attributes on queries
If you're familiar with query types and composition, you might remember that the parameters on a query request depend on field attributes in an index. For example, only fields marked as searchable and retrievable can be used in queries and search results. When setting the search, filter, and orderby parameters in your request, you should check attributes to avoid unexpected results.
In the following screenshot of the hotels-sample index, only the last two fields LastRenovationDate and Rating are sortable, a requirement for use in an "$orderby" only clause.
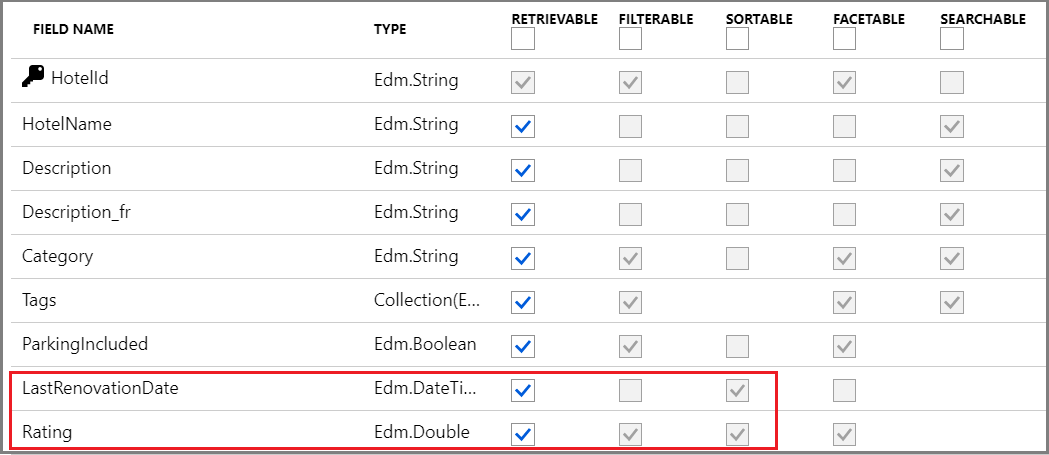
For field attribute definitions, see Create Index (REST API).
Effect of tokens on queries
During indexing, the search engine uses a text analyzer on strings to maximize the potential for finding a match at query time. At a minimum, strings are lower-cased, but depending on the analyzer, might also undergo lemmatization and stop word removal. Larger strings or compound words are typically broken up by whitespace, hyphens, or dashes, and indexed as separate tokens.
The key point is that what you think your index contains, and what's actually in it, can be different. If queries don't return expected results, you can inspect the tokens created by the analyzer through the Analyze Text (REST API). For more information about tokenization and the effect on queries, see Partial term search and patterns with special characters.
Troubleshoot queries
The following table lists common query issues and how to resolve them.
| Issue | Cause | Resolution |
|---|---|---|
| Empty results | No documents match query terms. | Verify field is marked searchable in schema. Use Analyze Text API to check tokenization. |
| Unexpected results | Query matches unintended fields. | Use searchFields to limit which fields are searched. |
| Too many results | Query is too broad. | Add filters, use searchMode=all, or add required terms with + operator. |
| Results not ranked as expected | Relevance scoring doesn't match expectations. | Consider scoring profiles or semantic ranking. |
| Partial matches missing | Analyzer tokenized differently than expected. | Use wildcard (*) suffix or check analyzer behavior with Analyze Text API. |
| Filter not working | Field isn't marked filterable. | Update index schema to set filterable: true on the field. |
Related content
Now that you have a better understanding of how query requests work, try the following quickstarts for hands-on experience.