Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Windows Server 故障转移群集与 Azure 虚拟机 (VM) 上的 SQL Server 配合使用,可实现 高可用性和灾难恢复 (HADR)。
本文为与 Azure 虚拟机 (VM) 上的 SQL Server 一起使用的故障转移群集实例 (FCI) 和可用性组提供群集配置最佳做法。
有关详细信息,请参阅本系列教程中的其他文章:清单、VM 大小、存储、安全性、HADR 配置和收集基线。
清单
请查看以下清单,以大致了解本文其余部分详细介绍的 HADR 最佳做法。
高可用性和灾难恢复 (HADR) 功能,如 Always On 可用性组和故障转移群集实例依赖于基础的Windows Server 故障转移群集技术。 查看修改 HADR 设置以更好地支持云环境的最佳做法。
对于 Windows 群集,请考虑以下最佳做法:
- 尽可能将 SQL Server VM 部署到多个子网,以避免依赖于 Azure 负载均衡器或分布式网络名称 (DNN) 来将流量路由到 HADR 解决方案。
- 将群集更改为主动性较低的参数,以避免暂时性网络故障或 Azure 平台维护带来的意外中断。 要了解详细信息,请参阅心跳和阈值设置。 对于 Windows Server 2012 及更高版本,请使用以下建议值:
- SameSubnetDelay:1 秒
- SameSubnetThreshold:40 个检测信号
- CrossSubnetDelay:1 秒
- CrossSubnetThreshold:40 个检测信号
- 将 VM 放置在可用性集或不同的可用性区域中。 要了解详细信息,请参阅 VM 可用性设置。
- 每个群集节点使用单个 NIC。
- 将群集仲裁投票配置为使用 3 个或更多奇数投票。 不要将投票分配给 DR 区域。
- 仔细监视资源限制,避免因资源限制出现意外重启或故障转移。
- 确保 OS、驱动程序和 SQL Server 都是最新版本。
- 针对 Azure VM 上的 SQL Server 优化性能。 查看本文中的其他部分了解详细信息。
- 减少或分散工作负荷,避免资源限制。
- 移动到具有更高限制的 VM 或磁盘,以避免约束。
对于 SQL Server 可用性组或故障转移群集实例,请考虑以下最佳做法:
- 如果经常出现意外失败,请遵循本文其余部分中概述的最佳性能做法。
- 如果优化 SQL Server VM 性能无法解决意外的故障转移,请考虑放宽对可用性组或故障转移群集实例的监视。 但这样做可能无法解决根本问题,同时可能会降低失败可能性而掩盖症状。 你可能仍需要调查并解决根本原因。 对于 Windows Server 2012 或更高版本,请使用以下建议值:
-
租用超时:使用此公式计算最大租用超时值:
Lease timeout < (2 * SameSubnetThreshold * SameSubnetDelay)。
首先从 40 秒开始。 如果使用之前建议的宽松SameSubnetThreshold和SameSubnetDelay值,则租用超时值不要超过 80 秒。 - 指定时间段内的最大失败数:将此值设置为 6。
-
租用超时:使用此公式计算最大租用超时值:
- 使用虚拟网络名称 (VNN) 和 Azure 负载均衡器连接 HADR 解决方案时,即使群集只跨越一个子网,也请在连接字符串中指定
MultiSubnetFailover = true。- 如果客户端不支持
MultiSubnetFailover = True,你可能需要设置RegisterAllProvidersIP = 0和HostRecordTTL = 300来缓存较短持续时间内的客户端凭据。 但这样做可能会导致对 DNS 服务器进行其他查询。
- 如果客户端不支持
- 要使用分布式网络名称 (DNN) 连接到 HADR 解决方案,请考虑以下事项:
- 必须使用支持
MultiSubnetFailover = True的客户端驱动程序,而且此参数必须位于连接字符串中。 - 连接可用性组的 DNN 侦听器时,请在连接字符串中使用唯一的 DNN 端口。
- 必须使用支持
- 对基本可用性组使用数据库镜像连接字符串,免去负载均衡器或 DNN 需求。
- 在部署高可用性解决方案之前,请验证 VHD 的扇区大小,以避免 I/O 未对齐的情况。 有关详细信息,请参阅 KB3009974。
- 如果将 SQL Server 数据库引擎、Always On 可用性组侦听程序或故障转移群集实例运行状况探测配置为使用 49,152 到 65,536 之间的端口(TCP/IP 的默认动态端口范围),请为每个端口添加一个排除项。 这样做可以防止其他系统被动态地分配到相同的端口。 下面的示例为端口 59999 创建一个排除项:
netsh int ipv4 add excludedportrange tcp startport=59999 numberofports=1 store=persistent
若要将 HADR 清单与其他最佳做法进行比较,请参阅全面的性能最佳做法清单。
VM 可用性设置
为了减轻停机造成的影响,请考虑以下 VM 最佳可用性设置:
- 将邻近放置组与加速网络一起使用以实现最低的延迟。
- 将虚拟机群集节点放置在不同的可用性区域中,以防止数据中心级故障,或放置在单个可用性集中,以实现同一数据中心内的低延迟冗余。
- 为可用性集中的 VM 使用高级托管 OS 和数据磁盘。
- 将每个应用程序层配置为单独的可用性集。
法定人数
尽管双节点群集即使没有仲裁资源也能正常工作,但我们严格要求客户使用仲裁资源来获得生产支持。 没有仲裁资源,群集验证不会通过任何群集。
从技术上说,如果没有仲裁资源,三节点群集可以在单个节点丢失(减少到两个节点)的情况下幸存下来,但在群集减少到两个节点后,如果出现另一个节点丢失或通信故障,则群集资源可能会脱机,以防止出现脑裂情况。 配置仲裁资源,将使群集在只有一个节点联机时可以继续联机。
磁盘见证是最具弹性的仲裁选项,但要在 Azure VM 上的 SQL Server 中使用磁盘见证,必须使用 Azure 共享磁盘,这会对高可用性解决方案施加一些限制。 因此,在使用 Azure 共享磁盘配置故障转移群集实例时请使用磁盘见证,否则尽量使用云见证。
下表列出了 Azure VM 上的 SQL Server 可用的仲裁选项:
| 云见证 | 磁盘见证 | 文件共享见证 | |
|---|---|---|---|
| 支持的 OS | Windows Server 2016 及更高版本 | 全部 | 全部 |
- 在多个站点、多个区域和多个地区中进行部署时,云见证是理想的选择。 除非使用的是共享存储群集解决方案,否则请尽量使用云见证。
- 磁盘见证是最具弹性的仲裁选项,并且对于使用 Azure 共享磁盘(或任何共享磁盘解决方案,例如共享 SCSI、iSCSI 或光纤通道 SAN)的任何群集,它都是首选的仲裁选项。 群集共享卷不能用作磁盘见证。
- 当磁盘见证和云见证选项不可用时,适合使用文件共享见证。
若要开始,请参阅配置群集仲裁。
法定人数投票
可以更改参与 Windows Server 故障转移群集的节点的仲裁投票。
修改节点投票设置时,请遵循以下指导原则:
| 法定人数投票准则 |
|---|
| 默认从没有投票的每个节点开始。 每个节点的投票都应附带明确的理由。 |
| 为托管可用性组主副本的群集节点或者为故障转移群集实例的首选所有者启用投票。 |
| 为自动故障转移所有者启用投票。 在自动故障转移后可以托管主副本或 FCI 的每个节点应具有一个投票。 |
| 如果某个可用性组具有多个次要副本,则仅为具有自动故障转移的副本启用投票。 |
| 为辅助灾难恢复站点中的节点禁用投票。 如果主站点没有任何问题,则辅助站点中的节点不应该影响群集脱机决策。 |
| 具有奇数个投票,至少有三个仲裁投票。 根据需要,在双节点群集中添加一个仲裁见证,以额外增加一个投票。 |
| 故障转移后重新评估投票分配。 你不希望故障转移到不支持运行状况仲裁的群集配置。 |
连接
若要匹配连接到可用性组侦听器或故障转移群集实例的本地体验,请将 SQL Server VM 部署到同一虚拟网络中的多个子网。 拥有多个子网可以免除对 Azure 负载均衡器或分布式网络名称的额外依赖,从而将流量路由到您的侦听器。
若要简化 HADR 解决方案,请尽可能将 SQL Server VM 部署到多个子网。 有关详细信息,请参阅多子网 AG 和多子网 FCI。
如果 SQL Server VM 位于单个子网中,则可为故障转移群集实例和可用性组侦听器配置虚拟网络名称 (VNN) 和 Azure 负载均衡器,或者为分布式网络名称 (DNN)。
分布式网络名称是建议的连接选项(如果可用):
- 端到端解决方案更加可靠,因为不再需要维护负载均衡器资源。
- 消除负载均衡器探测可最大程度地缩短故障转移时间。
- DNN 使用 Azure VM 上的 SQL Server 简化故障转移群集实例或可用性组侦听程序的配置和管理。
请考虑以下限制:
- 客户端驱动程序必须支持
MultiSubnetFailover=True参数。 - 在 Windows Server 2016 和更高版本上,从 SQL Server 2016 SP3SQL Server 2017 CU25、SQL Server 2019 CU8 开始提供 DNN 功能。
有关详细信息,请参阅 Windows Server 故障转移群集概述。
若要配置连接,请参阅以下文章:
使用 DNN 时,大多数 SQL Server 功能透明地适用于 FCI 和可用性组,但是某些功能可能需要特殊考虑。 请参阅 FCI 和 DNN 互操作性 以及 AG 和 DNN 互操作性了解详细信息。
提示
即使是跨越单个子网的 HADR 解决方案,也可以在连接字符串中将 MultiSubnetFailover 参数设置为 true,以支持将来的跨越子网而无需更新连接字符串的功能。
心跳和阈值
将群集检测信号和阈值设置更改为宽松设置。 默认检测信号和阈值群集设置适用于高度优化的本地网络,不考虑云环境中延迟增大的可能性。 心跳网络是通过 UDP 3343 维护的,传统上该协议的可靠性远低于 TCP,更容易导致通信不完整。
因此,在为 Azure VM 上的 SQL Server 高可用性解决方案运行群集节点时,请将群集设置更改为更宽松的监视状态,以避免由于更有可能发生网络延迟或故障、Azure 维护或资源瓶颈而导致的暂时性故障。
延迟和阈值设置对总体健康检测产生累积影响。 例如,在执行恢复之前将 CrossSubnetDelay 设置为每隔 2 秒发送检测信号并将 CrossSubnetThreshold 设置为 10 个丢失的检测信号意味着,在执行恢复操作之前,群集总共可以容许 20 秒网络延迟。 一般而言,最好是继续发送频繁的心跳信号,但使用更高的阈值。
为了确保在合法的服务中断期间能够恢复,同时为暂时性问题提供更高的容许度,请将延迟和阈值设置放宽为下表中详述的建议值:
| 设置 | Windows Server 2012 或更高版本 | Windows Server 2008 R2 |
|---|---|---|
| 相同子网延迟 | 1 秒 | 2 秒 |
| 同一子网阈值 | 40 次心跳 | 10 个检测信号(最大值) |
| 跨子网延迟 | 1 秒 | 2 秒 |
| CrossSubnetThreshold | 40 次心跳 | 20 次心跳(最大) |
使用 PowerShell 更改群集参数:
(get-cluster).SameSubnetThreshold = 40
(get-cluster).CrossSubnetThreshold = 40
使用 PowerShell 验证更改:
get-cluster | fl *subnet*
考虑以下情况:
- 此项更改会立即生效,无需重启群集或任何资源。
- 相同的子网值不应大于跨子网值。
- SameSubnetThreshold <= CrossSubnetThreshold
- 同子网延迟 <= 跨子网延迟
根据应用程序、业务需求和环境,基于可容许的停机时间以及在采取纠正措施之前问题可持续的时间选择宽松值。 如果无法超过默认的 Windows Server 2019 值,在可能的情况下,请至少尝试匹配这些值:
下表详细说明了默认值供用户参考:
| 设置 | Windows Server 2019 | Windows Server 2016 | Windows Server 2008 - 2012 R2 |
|---|---|---|---|
| 同子网延迟 (SameSubnetDelay) | 1 秒 | 1 秒 | 1 秒 |
| 同一子网阈值 | 20 个检测信号 | 10 个检测信号 | 5 个检测信号 |
| 跨子网延迟 | 1 秒 | 1 秒 | 1 秒 |
| 跨子网阈值 | 20 个检测信号 | 10 个检测信号 | 5 个检测信号 |
有关详细信息,请参阅优化故障转移群集网络阈值。
放松监控
如果根据建议优化群集检测信号和阈值设置不能实现足够的容许度,并且仍然发现暂时性问题(而不是真正的服务中断)导致故障转移,则可以将 AG 或 FCI 监视配置为更宽松的设置。 在某些场景中,在活动级别一定的情况下,将监视暂时放宽一段时间可能很有利。 例如,在执行数据库备份、索引维护、DBCC CHECKDB 等 IO 密集型工作负载时,你可能想要放宽监视。活动完成后,将监视设置为不太宽松的值。
警告
更改这些设置可能会掩盖根本性问题,应将此做法用作临时性的解决方法来减少而不是消除发生故障的可能性。 仍应调查并解决根本性问题。
首先,将以下参数在其默认值的基础上增大以放宽监视,并根据需要进行调整:
| 参数 | 默认值 | 宽松值 | 说明 |
|---|---|---|---|
| Healthcheck 超时 | 30000 | 60000 | 确定主副本或节点的健康状况。 群集资源 DLL sp_server_diagnostics 以相当于运行状况检查超时阈值的 1/3 的间隔返回结果。 如果 sp_server_diagnostics 的运行速度较慢或未返回信息,则资源 DLL 会等待运行状况检查超时阈值的完整间隔,然后确定该资源无响应,并启动自动故障转移(如果已配置为执行此操作)。 |
| 故障条件级别 | 3 | 2 | 触发自动故障转移的条件。 有 5 个故障条件级别,其范围从最低限制(级别 1)到最高限制(级别 5)。 |
使用 Transact-SQL (T-SQL) 修改 AG 和 FCI 的运行状况检查和故障条件。
对于可用性组:
ALTER AVAILABILITY GROUP AG1 SET (HEALTH_CHECK_TIMEOUT =60000);
ALTER AVAILABILITY GROUP AG1 SET (FAILURE_CONDITION_LEVEL = 2);
对于故障转移群集实例:
ALTER SERVER CONFIGURATION SET FAILOVER CLUSTER PROPERTY HealthCheckTimeout = 60000;
ALTER SERVER CONFIGURATION SET FAILOVER CLUSTER PROPERTY FailureConditionLevel = 2;
具体对于可用性组而言,请从以下建议的参数开始,并根据需要进行调整:
| 参数 | 默认值 | 宽松值 | 说明 |
|---|---|---|---|
| 租约超时 | 20000 | 40000 | 防止脑分裂现象。 |
| 会话超时 | 1万 | 20000 | 检查副本之间的通信问题。 会话超时期限是一个副本属性,用于控制可用性副本等待已连接副本的 ping 响应的时间(秒数),超过该期限即认为连接失败。 默认情况下,副本等待 ping 响应的时长为 10 秒钟。 此副本属性仅适用于可用性组的给定次要副本与主副本之间的连接。 |
| 指定时段内的最大故障次数 | 2 | 6 | 用于避免在多次发生节点故障期间无限期地移动群集资源。 值太小可能会导致可用性组处于故障状态。 由于值太小可能会导致 AG 处于故障状态,因此请增大该值,以防止性能问题造成短暂的中断。 |
在更改之前请注意以下事项:
- 不要将任何超时值降低到默认值以下。
- 使用以下公式计算最大租用超时值:
Lease timeout < (2 * SameSubnetThreshold * SameSubnetDelay)。
首先从 40 秒开始。 如果使用之前建议的宽松SameSubnetThreshold和SameSubnetDelay值,则租用超时值不要超过 80 秒。 - 对于同步提交副本,将会话超时更改为较大值可以增大 HADR_sync_commit 等待时间。
租约超时
使用故障转移群集管理器修改可用性组的租用超时设置。 有关详细步骤,请参阅 SQL Server 可用性组租用运行状况检查文档。
会话超时
使用 Transact-SQL (T-SQL) 修改可用性组的会话超时:
ALTER AVAILABILITY GROUP AG1
MODIFY REPLICA ON 'INSTANCE01' WITH (SESSION_TIMEOUT = 20);
指定时段内的最大故障次数
使用故障转移群集管理器修改“指定时段内的最大故障次数”值:
- 在导航窗格中选择“角色”。
- 在“角色”下,右键单击群集资源并选择“属性” 。
- 选择“故障转移”选项卡,并根据需要增大“指定时段内的最大故障次数”值。
资源限制
VM 或磁盘限制可能导致资源瓶颈,影响群集的运行状况并妨碍运行状况检查。 如果资源限制造成了问题,请考虑采取以下措施:
- 确保 OS、驱动程序和 SQL Server 都是最新版本。
- 根据 Azure 虚拟机上的 SQL Server 的性能指导原则中所述,优化 Azure VM 上的 SQL Server 环境
- 减少或分散工作负载,以便在不超过资源限制的情况下降低利用率
- 抓住任何机会优化 SQL Server 工作负载,例如
- 添加/优化索引
- 根据需要更新统计信息,并在可能的情况下使用完全扫描
- 在运行备份或索引维护等特定工作负载期间,使用资源调控器(从 SQL Server 2014 开始,仅适用于企业)等功能限制资源利用率。
- 迁移到限制更高的 VM 或磁盘,以满足甚至超过工作负载的需求。
网络
尽可能将 SQL Server VM 部署到多个子网,以避免依赖于 Azure 负载均衡器或分布式网络名称 (DNN) 来将流量路由到 HADR 解决方案。
每个服务器(群集节点)使用单个 NIC。 Azure 网络具有物理冗余,因此在 Azure 虚拟机来宾群集上不需要额外的 NIC。 群集验证报告上有警告,提示你只能在一个网络上访问节点。 在 Azure 虚拟机来宾故障转移群集上,可以忽略此警告。
特定 VM 的带宽限制在各个 NIC 之间分摊,添加其他 NIC 并不能提高 Azure VM 上的 SQL Server 的可用性组性能。 因此,无需添加第二个 NIC。
Azure 中不符合 RFC 的 DHCP 服务可能会导致某些故障转移群集配置创建失败。 失败的原因是为群集网络名称分配了重复的 IP 地址,例如与某个群集节点相同的 IP 地址。 使用可用性组时会出现一个问题,因为这些组依赖 Windows 故障转移群集功能。
创建两节点群集并使其联机时,请考虑此应用场景:
- 群集联机,NODE1 随后会为群集网络名称请求一个动态分配的 IP 地址。
- DHCP 服务除了 NODE1 自身的 IP 地址以外不提供任何 IP 地址,因为 DHCP 服务可以识别请求是否来自 NODE1 自身。
- Windows 检测到同时向 NODE1 和故障转移群集网络名称分配了一个重复的地址,并且默认群集组未能联机。
- 默认群集组会移动到 NODE2。 NODE2 将 NODE1 的 IP 地址作为群集 IP 地址,并使默认群集组联机。
- 当 NODE2 尝试与 NODE1 建立连接时,针对 NODE1 的数据包从不离开 NODE2,因为后者将 NODE1 的 IP 地址解析为其自身。 NODE2 无法与 NODE1 建立连接,它会丢失仲裁并关闭群集。
- NODE1 可向 NODE2 发送数据包,但 NODE2 无法回复。 NODE1 丢失仲裁并关闭群集。
可通过将未使用的静态 IP 地址分配给群集网络名称,让群集网络名称联机,并将该 IP 地址添加到 Azure 负载均衡器,从而避免这种情况发生。
配置探测端口
使用 Azure 负载均衡器支持虚拟网络名称(VNN)资源时,您必须将群集配置为能够响应 AlwaysOn 可用性组侦听器或故障转移群集实例的运行状况探测请求。 如果运行状况探测无法从后端实例获取响应,则在 运行状况探测再次成功之前,不会向该后端实例发送新连接。
配置排除端口
如果使用虚拟网络名称(VNN)资源与 Azure 负载均衡器,则当使用运行状况探测端口介于 49,152 和 65,536( TCP/IP 的默认动态端口范围)时,必须为 AlwaysOn 可用性组侦听器或 故障转移群集实例配置端口排除。
设置端口排除可防止事件发生,例如 事件 ID:1069,状态为 10048,这可能是由于内部进程占用了定义为探测端口的端口而导致的。
以下示例显示了群集日志中状态为 10048 的事件 ID 1069:
Cluster resource '<IP name in AG role>' of type 'IP Address' in cluster role '<AG Name>' failed.
An Event ID: 1069 with status 10048 can be identified from cluster logs with events like:
Resource IP Address 10.0.1.0 called SetResourceStatusEx: checkpoint 5. Old state OnlinePending, new state OnlinePending, AppSpErrorCode 0, Flags 0, nores=false
IP Address <IP Address 10.0.1.0>: IpaOnlineThread: **Listening on probe port 59999** failed with status **10048**
如果应用程序尝试将套接字绑定到已用于现有套接字的 IP 地址/端口,则会出现状态 10048。
已知问题
查看一些常见已知问题和错误的解决方法。
资源争用(特别是 IO)会导致故障转移
VM 的 I/O 或 CPU 容量耗尽可能会导致可用性组进行故障转移。 确定在故障转移之前所发生的争用是确定导致自动故障转移的原因的最可靠方法。
按照以下步骤查看 Azure VM 整体 IO 耗尽事件:
在 Azure 门户中导航到虚拟机,而不是 SQL 虚拟机。
选择“监视”下的 “指标”以打开“指标”页。
选择“本地时间”以指定你感兴趣的时间范围和时区(VM 本地时间或 UTC/GMT)。
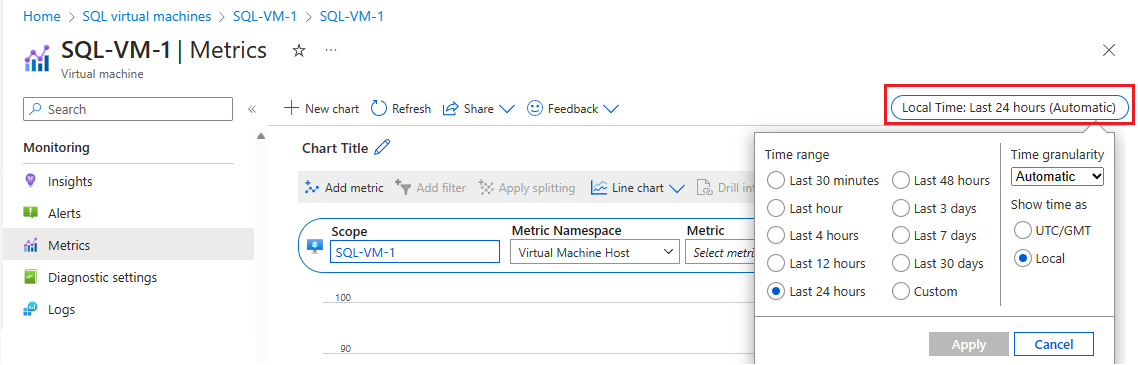
选择“添加指标”,添加以下两个指标以查看图形:
- 已使用的 VM 缓存带宽百分比
- 已使用的 VM 未缓存带宽百分比
Azure VM HostEvents 导致故障转移
Azure VM HostEvent 可能会导致可用性组进行故障转移。 如果认为 Azure VM HostEvent 导致了故障转移,可以检查 Azure Monitor 活动日志和 Azure VM 资源运行状况概述。
Azure Monitor 活动日志是 Azure 中的一种平台日志,它提供订阅级事件的见解。 该活动日志包括何时修改了资源或启动了虚拟机等信息。 可以在 Azure 门户中查看活动日志,或使用 PowerShell 和 Azure CLI 检索条目。
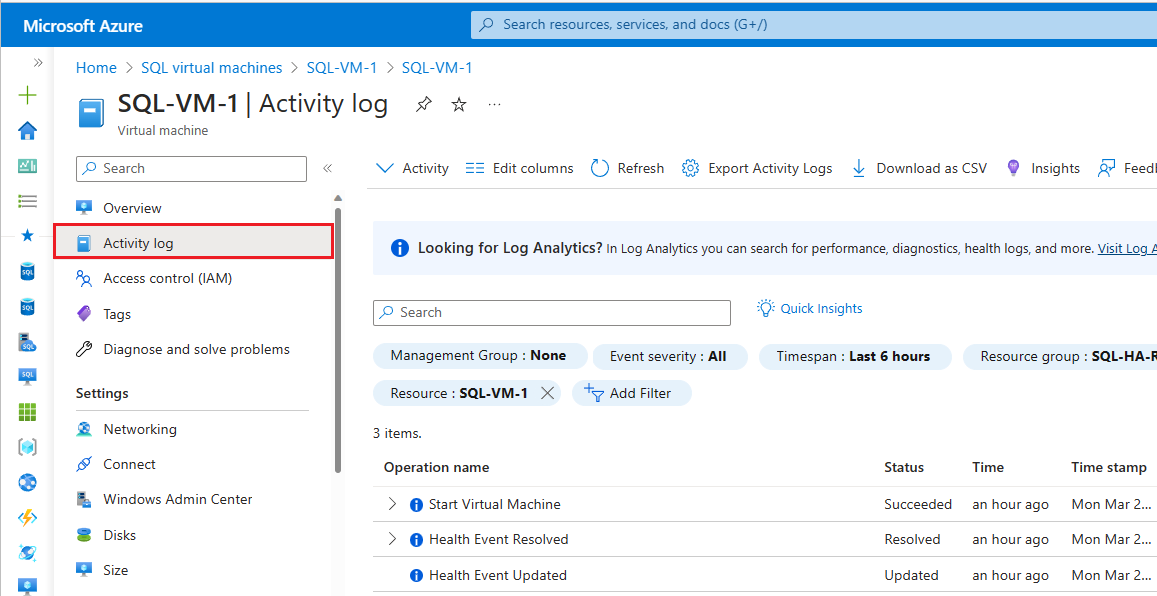
若要检查 Azure Monitor 活动日志,请执行以下步骤:
在 Azure 门户中导航到你的虚拟机
在“虚拟机”窗格上选择“活动日志”
选择“时间跨度”,然后选择可用性组故障转移的时间范围。 选择应用。
如果 Azure 具有关于平台启动不可用性根本原因的进一步信息,则该信息可能会在最初不可用后 72 小时内发布到 Azure VM - 资源运行状况概述页。 此信息目前仅适用于虚拟机。
- 在 Azure 门户中导航到你的虚拟机
- 在“运行状况”窗格中选择“资源运行状况”。
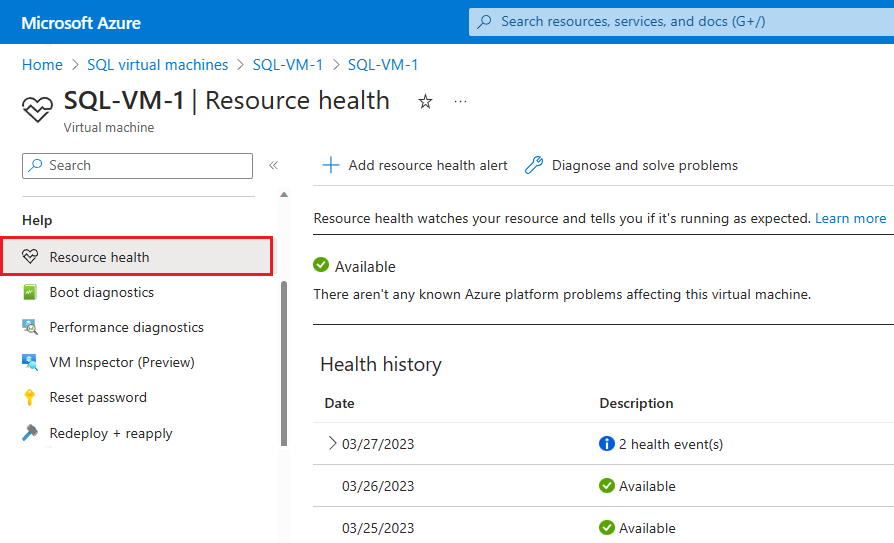
您还可以根据此页面的健康事件配置警报。
从成员身份中删除了群集节点
如果 Windows 群集检测信号和阈值设置对于环境而言过于严格,则系统事件日志中可能会经常出现以下消息。
Error 1135
Cluster node 'Node1' was removed from the active failover cluster membership.
The Cluster service on this node may have stopped. This could also be due to the node having
lost communication with other active nodes in the failover cluster. Run the Validate a
Configuration Wizard to check your network configuration. If the condition persists, check
for hardware or software errors related to the network adapters on this node. Also check for
failures in any other network components to which the node is connected such as hubs, switches, or bridges.
有关详细信息,请查看排查事件 ID 为 1135 的群集问题。
租约已过期/租约不再有效
如果监视对环境过于严格,则可能会看到频繁的可用性组或 FCI 重启、故障或故障转移。 此外,对于可用性组,SQL Server 错误日志中可能会出现以下消息:
Error 19407: The lease between availability group 'PRODAG' and the Windows Server Failover Cluster has expired.
A connectivity issue occurred between the instance of SQL Server and the Windows Server Failover Cluster.
To determine whether the availability group is failing over correctly, check the corresponding availability group
resource in the Windows Server Failover Cluster
Error 19419: The renewal of the lease between availability group '%.*ls' and the Windows Server Failover Cluster
failed because the existing lease is no longer valid.
连接超时
如果会话超时对于可用性组环境而言过于严格,可能会经常出现以下消息:
Error 35201: A connection timeout has occurred while attempting to establish a connection to availability
replica 'replicaname' with ID [availability_group_id]. Either a networking or firewall issue exists,
or the endpoint address provided for the replica is not the database mirroring endpoint of the host server instance.
Error 35206
A connection timeout has occurred on a previously established connection to availability
replica 'replicaname' with ID [availability_group_id]. Either a networking or a firewall issue
exists, or the availability replica has transitioned to the resolving role.
未故障转移的组
如果“指定时段内的最大故障次数”值太小,并且暂时性问题导致了间歇性故障,则可用性组最终可能会进入故障状态。 请增大此值以容许更多的暂时性故障。
Not failing over group <Resource name>, failoverCount 3, failoverThresholdSetting <Number>, computedFailoverThreshold 2.
事件 1196 - 网络名称资源未能注册关联的 DNS 名称
- 检查每个群集节点的 NIC 设置,确保不存在外部 DNS 记录
- 确保群集的 A 记录存在于内部 DNS 服务器上。 如果没有,请在 DNS 服务器中为“群集访问控制”对象手动创建新的 A 记录,并选中“允许所有经过身份验证的用户用相同的所有者名称来更新 DNS 记录”。
- 将带有 IP 资源的资源“群集名称”脱机并修复它。
事件 157 - 磁盘已意外删除。
如果 AG 环境的“存储空间”属性 AutomaticClusteringEnabled 设置为 True,则可能会发生这种情况。 将其更改为 False。 而且,使用“存储”选项运行验证报告可能会触发磁盘重置或事件意外删除。 存储系统限流还可以触发磁盘意外移除事件。
事件 1206 - 群集网络名称资源无法联机。
与资源相关联的计算机对象无法在域中更新。 请确保拥有适当的域权限
Windows 群集错误
如果没有为通信打开群集服务端口,则在设置 Windows 故障转移群集或其连接时可能会遇到问题。
如果你在 Windows Server 2019 上未看到 Windows 群集 IP,则说明你配置了分布式网络名称,它仅在 SQL Server 2019 上受支持。 如果你有 SQL Server 的早期版本,则可以使用网络名称删除并重新创建群集。
查看其他 Windows 故障转移在此处查看群集事件错误及其解决方案
后续步骤
若要了解更多信息,请参阅以下文章: