Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
重要
新项目不再支持 Synapse Link for Cosmos DB。 请勿使用此功能。
请使用现已正式发布的 Microsoft Fabric 的 Azure Cosmos DB 镜像。 镜像提供相同的零 ETL 优势,并与 Microsoft Fabric 完全集成。
使用 Azure Cosmos DB 分析存储中的变更数据捕获 (CDC) 作为 Azure 数据工厂或 Azure Synapse Analytics 的源,以捕获对数据所做的特定更改。
先决条件
启用分析存储
首先,在帐户级别启用 Azure Synapse Link,然后为适合工作负载的容器启用分析存储。
启用 Azure Synapse Link:为 Azure Cosmos DB 帐户启用 Azure Synapse Link
为容器启用分析存储。 有关详细信息和具体说明,请参阅 为新容器启用 Azure Synapse Link。
使用数据流创建目标 Azure 资源
分析存储的变更数据捕获功能可通过 Azure 数据工厂或 Azure Synapse Analytics 的数据流功能获得。 对于本指南,请使用 Azure 数据工厂。
重要
也可以使用 Azure Synapse Analytics。 首先,创建 Azure Synapse 工作区(如果还没有)。 在新创建的工作区中,依次选择“开发”选项卡、“添加新资源”和“数据流”。
创建 Azure 数据工厂(如果还没有)。
提示
如果可能,请在 Azure Cosmos DB 帐户所在的同一区域中创建数据工厂。
启动新创建的数据工厂。
在数据工厂中,选择“数据流”选项卡,然后选择“新建数据流”。
为新创建的数据流指定唯一名称。 在此示例中,数据流命名为
cosmoscdc。

配置分析存储容器的源设置
现在,创建并配置一个源以从 Azure Cosmos DB 帐户的分析存储中传输数据。
注意
Azure Cosmos DB 的 Synapse Link Spark 连接器不支持托管标识。
选择“添加源”。
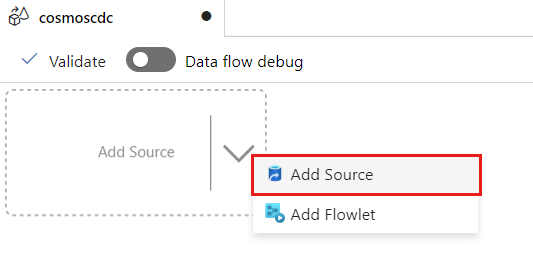
在“输出流名称”字段中,输入 cosmos。
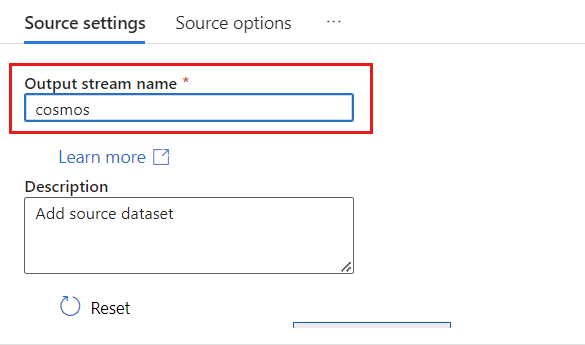
在“源类型”部分,选择“内联”。
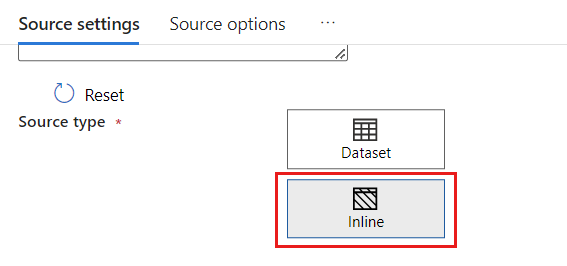
在“数据集”字段中,选择“Azure - Azure Cosmos DB for NoSQL”。
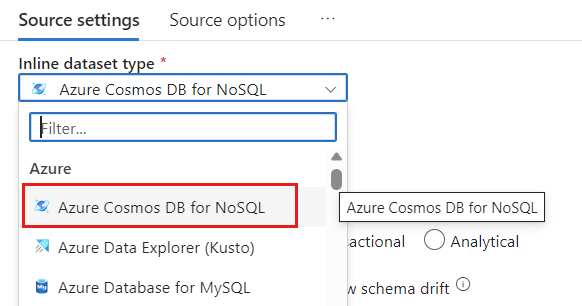
为名为 cosmoslinkedservice 的帐户创建新的链接服务。 在“新建链接服务”弹出对话框中,选择现有的 Azure Cosmos DB for NoSQL 帐户,然后选择“确定”。 在此示例中,我们选择一个预先存在的 Azure Cosmos DB for NoSQL 帐户
msdocs-cosmos-source,并指定了一个数据库cosmicworks。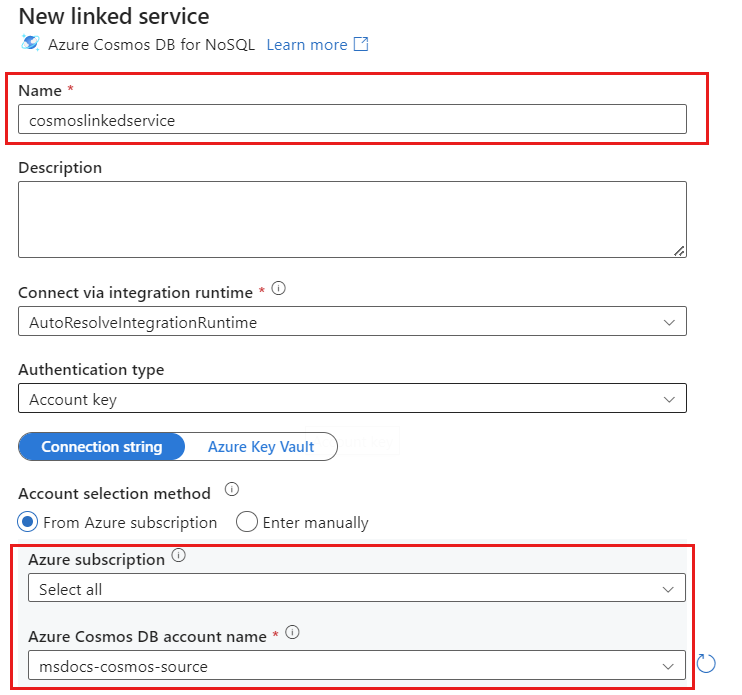
为存储类型选择“分析”。
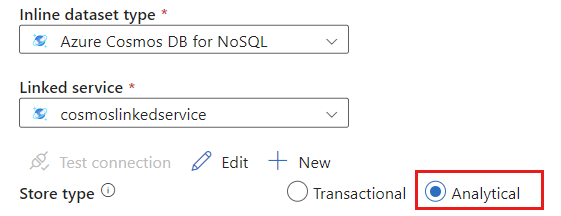
选择“源选项”选项卡。
在“源选项”中,选择目标容器并启用“数据流调试”。 在此示例中,容器命名为
products。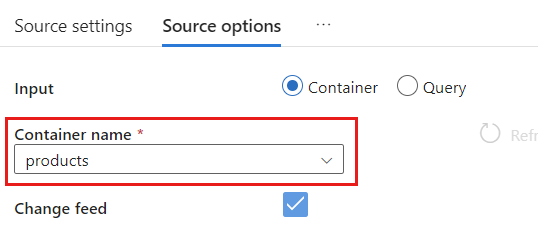
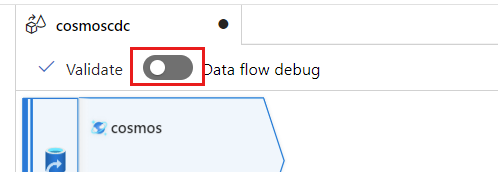
选择“数据流调试”。 在“启用数据流调试”弹出对话框中,保留默认选项,然后选择“确定”。
“源选项”选项卡还包含你可能希望启用的其他选项。 下表描述了这些选项:
| 选项 | 说明 |
|---|---|
| 捕获中间更新 | 如果要捕获项目的更改历史记录,包括变更数据捕获读取之间的中间更改,请启用此选项。 |
| 记录删除 | 激活此选项可捕获用户所删除的记录并将其应用于汇聚点。 不能在 Azure 数据资源管理器和 Azure Cosmos DB 的汇聚点上应用删除操作。 |
| 捕获事务存储 TTL | 启用此选项可捕获 Azure Cosmos DB 事务存储中设定了 TTL(生存时间)并已删除的记录,并将其应用于 Sink。 不能在 Azure 数据资源管理器和 Azure Cosmos DB 接收器上应用 TTL 删除。 |
| 批大小(以字节为单位) | 此设置实际上是千兆字节 (GB)。 如果您希望对变更数据捕获流进行批处理,请指定大小(以GB为单位) |
| 额外配置 | 额外的 Azure Cosmos DB 分析存储配置及其值。 (例如:spark.cosmos.allowWhiteSpaceInFieldNames -> true) |
使用源选项
当您选中 Capture intermediate updates、Capture Deletes 和 Capture Transactional store TTLs 选项中的任何一个时,CDC 进程将在接收器中创建 __usr_opType 字段,并填入以下值:
| 值 | 说明 | 选项 |
|---|---|---|
| 1 | 更新 | 捕获中间更新 |
| 2 | INSERT | 没有插入选项,其默认处于打开状态 |
| 3 | 用户删除 | 记录删除 |
| 4 | TTL_DELETE | 捕获事务存储 TTL |
如果需要区分 TTL 已删除记录与用户或应用程序删除的文档,可以同时检查 Capture intermediate updates 和 Capture Transactional store TTLs 选项。 然后,必须根据业务需求调整 CDC 进程、应用程序或查询以使用 __usr_opType。
提示
如果下游使用者需要还原已选中“捕获中间更新”选项的更新顺序,则可以将系统时间戳 _ts 字段用作排序字段。
创建和配置用于更新和删除操作的接收器设置
首先,创建一个简单的 Azure Blob 存储接收器,然后将该接收器配置为仅筛选特定操作的数据。
创建 Azure Blob 存储帐户和容器(如果还没有)。 在接下来的示例中,我们将使用名为
msdocsblobstorage的帐户和名为output的容器。提示
如果可能,请在 Azure Cosmos DB 帐户所在的同一区域中创建存储帐户。
返回 Azure 数据工厂,为从
cosmos源捕获的变更数据创建新的接收器。屏幕截图显示添加一个新接收端,该接收端与现有源相连接。
为接收器提供唯一名称。 在此示例中,汇聚器命名为
storage。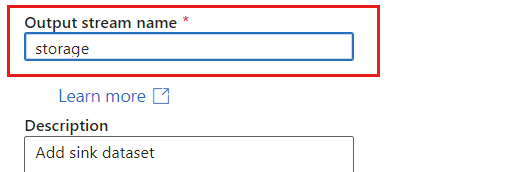
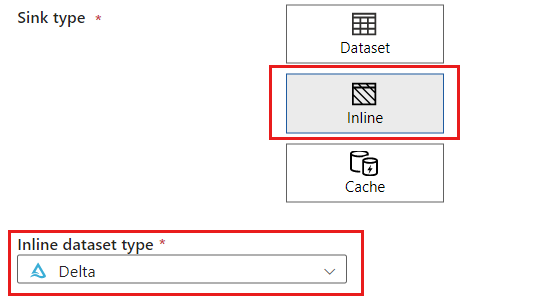
在“接收器类型”部分,选择“内联”。 在“数据集”字段中,选择“Delta”。
使用名为 storagelinkedservice 的 Azure Blob 存储为帐户创建新的链接服务。 在“新建链接服务”弹出对话框中,选择现有的 Azure Blob 存储帐户,然后选择“确定”。 在此示例中,我们将选择一个名为
msdocsblobstorage的 Azure Blob 存储帐户。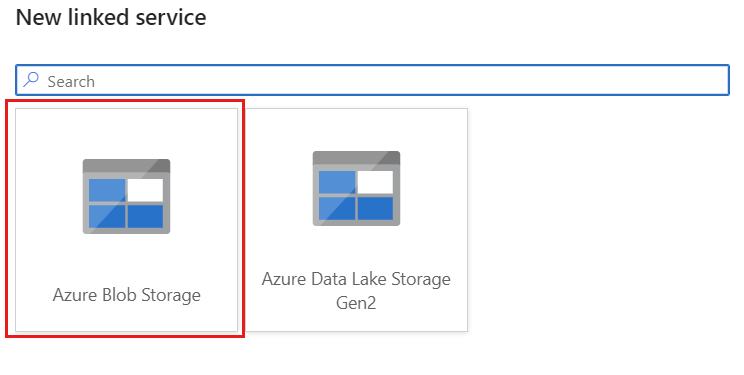
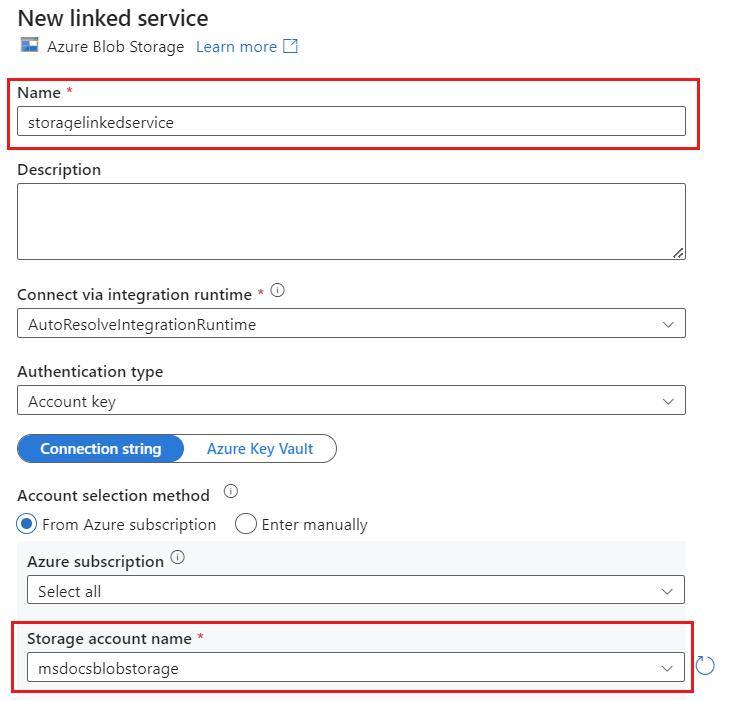
选择“设置”选项卡。
在“设置”中,将“文件夹路径”设置为 Blob 容器的名称。 在此示例中,容器的名称为
output。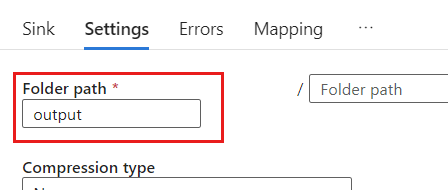
找到“更新方法”部分,并将选择更改为仅允许“删除”和“更新”操作。 此外,使用字段 作为唯一标识符时,请将“键列”指定为“
{_rid}”。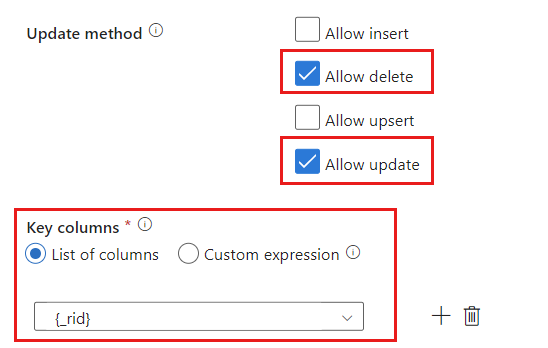
选择“验证”以确保未出现任何错误或遗漏。 然后,选择“发布”以发布数据流。
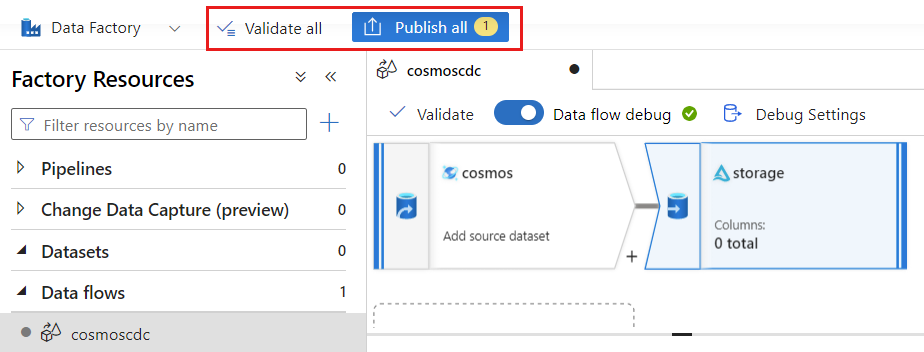
时间表变更数据捕捉执行
发布数据流后,可以添加新管道来移动和转换数据。
创建新管道。 为管道指定唯一名称。 在此示例中,管道名称为
cosmoscdcpipeline。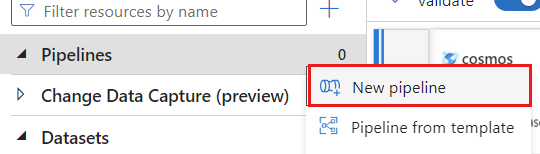
在“活动”部分中,展开“移动和转换”选项,然后选择“数据流”。
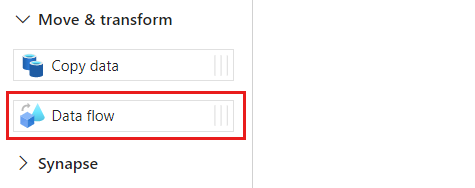
为数据流活动指定唯一名称。 在此示例中,活动命名为
cosmoscdcactivity。在“设置”选项卡中,选择之前在本指南中创建的名为
cosmoscdc的数据流。 然后,根据数据量和工作负载所需的延迟选择计算大小。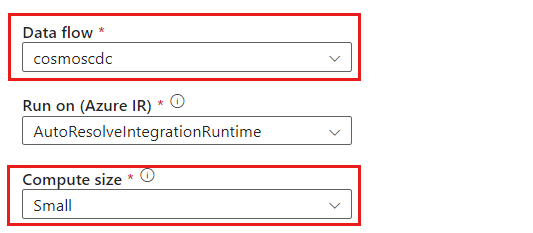
提示
对于大于 100 GB 的增量数据大小,建议使用核心数为 32(+16 个驱动程序核心)的自定义大小。
选择“添加触发器”。 计划此管道,使其按对工作负载有意义的节奏执行。 在此示例中,管道配置为每五分钟执行一次。
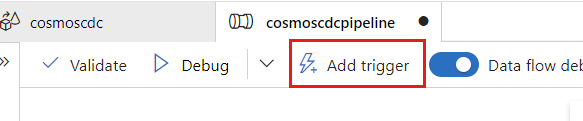
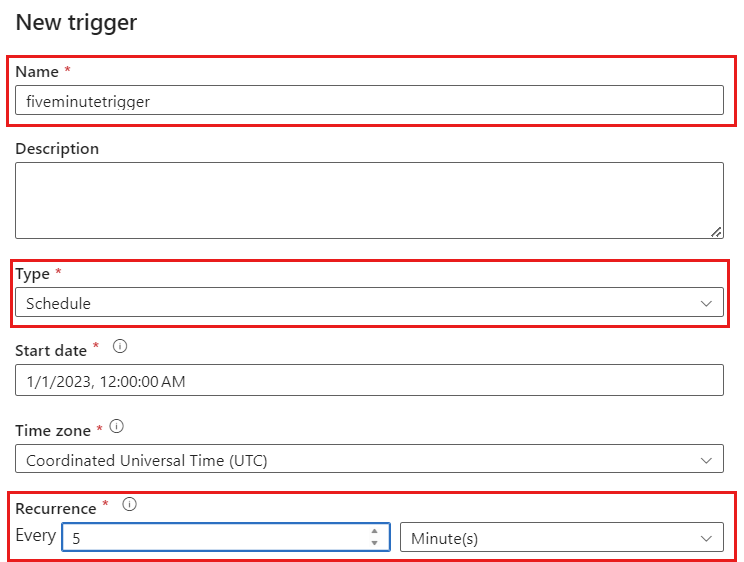
注意
执行变更数据捕获操作的最小时间窗口为一分钟。
选择“验证”以确保未出现任何错误或遗漏。 然后,选择“发布”以发布管道。
通过 Azure Cosmos DB 分析存储的变更数据捕获,观察作为数据流输出的数据被置于 Azure Blob 存储容器中。
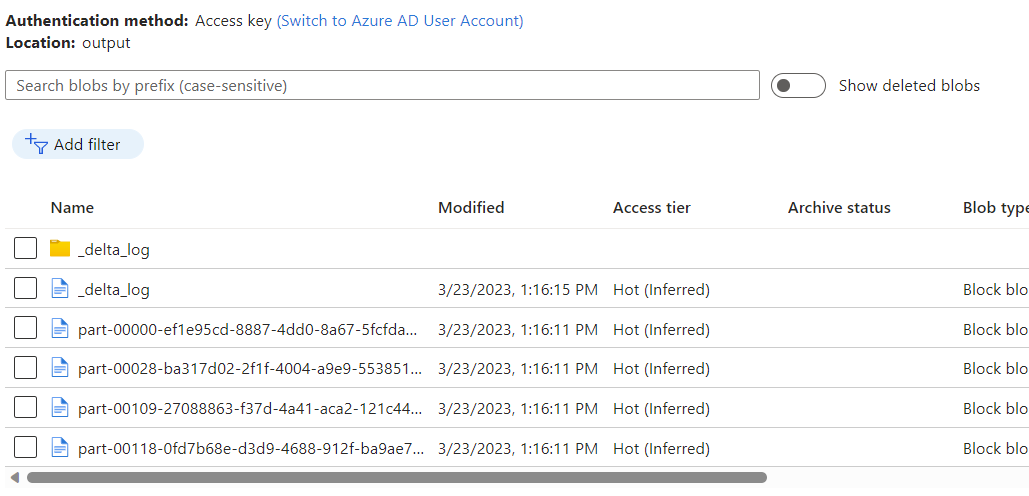
注意
初始群集启动时间最长可能需要三分钟。 若要在后续的变更数据捕获执行中避免群集启动时间,请配置数据流群集的生存时间值。 有关集成运行时和 TTL 的详细信息,请参阅 Azure 数据工厂中的集成运行时。
并发作业
源选项中的批大小,或者当接收端对更改流的引入速度较慢时,可能会导致同时执行多个任务。 为了避免这种情况,请在管道设置中将 并发 选项设置为 1,以确保在当前执行完成之前不会触发新执行。