Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
适用范围:![]() NoSQL
NoSQL
“请求速率过大”异常(也称为“错误代码 429”)表示,针对 Azure Cosmos DB 提出请求时,请求速率受限。
本文包含 API for NoSQL 的各种 429 状态代码错误的已知原因和解决方案。 如果使用的是用于 MongoDB 的 API,请参阅 用于 MongoDB 的 API 中的常见问题疑难解答。
若要使用预配吞吐量,可以工作负载所需的每秒请求单位 (RU/s) 为单位设置吞吐量。 针对服务的数据库操作(如读取、写入和查询)会消耗一定数量的请求单元 (RU)。 详细了解请求单元。
在某一秒内,如果操作的消耗量超过预配的请求单位,Azure Cosmos DB 将返回 429 错误。 每秒重置可用的请求单位数。
在采取措施更改 RU/s 之前,必须了解速率限制的根本原因并解决基础问题。
提示
本文中的指导适用于使用预配置吞吐量(自动缩放和手动吞吐量)的数据库和容器。
存在对应不同类型的 429 异常的不同错误消息:
请求速率太大
这是最常见的情况。 当对数据进行操作消耗的 RU 超过配置的 RU 数时,会发生此情况。 当您使用手动配置的吞吐量时,如果您消耗的 RU/秒超过了手动配置的吞吐量,将会出现此情况。 如果您使用自动扩展,当您使用量超过预配的最大 RU/秒时,会发生这种情况。 例如,如果资源被配置为手动吞吐量为 400 RU/秒,那么当在一秒内消耗超过 400 个请求单位时,将会收到 429 状态码。 如果一个资源被预配为具有最大 4000 RU/秒的自动扩展功能(在 400 RU/秒到 4000 RU/秒之间扩展),当在某一秒内消耗超过 4000 请求单位时,您将看到 429 响应。
提示
所有作都根据消耗的资源数收费。 这些费用以请求单位为单位进行度量。 这些费用包括由于应用程序错误(如 400、412 和 449)而未成功完成的请求。 在查看限制或使用情况时,最好调查某些使用模式是否发生了更改,从而导致这些操作的增加。 具体而言,检查标记 412 或 449 (实际冲突)。
有关预配吞吐量的详细信息,请参阅 Azure Cosmos DB 中预配的吞吐量简介。
第 1 步:检查指标,确定出现 429 错误的请求百分比
看到 429 错误消息并不一定意味着数据库或容器出现问题。 无论是使用手动还是自动缩放的吞吐能力,429 个响应的一小部分都是正常的,这表明你正在最大程度地提高预配的每秒请求单元 (RU/s)。
调查方式
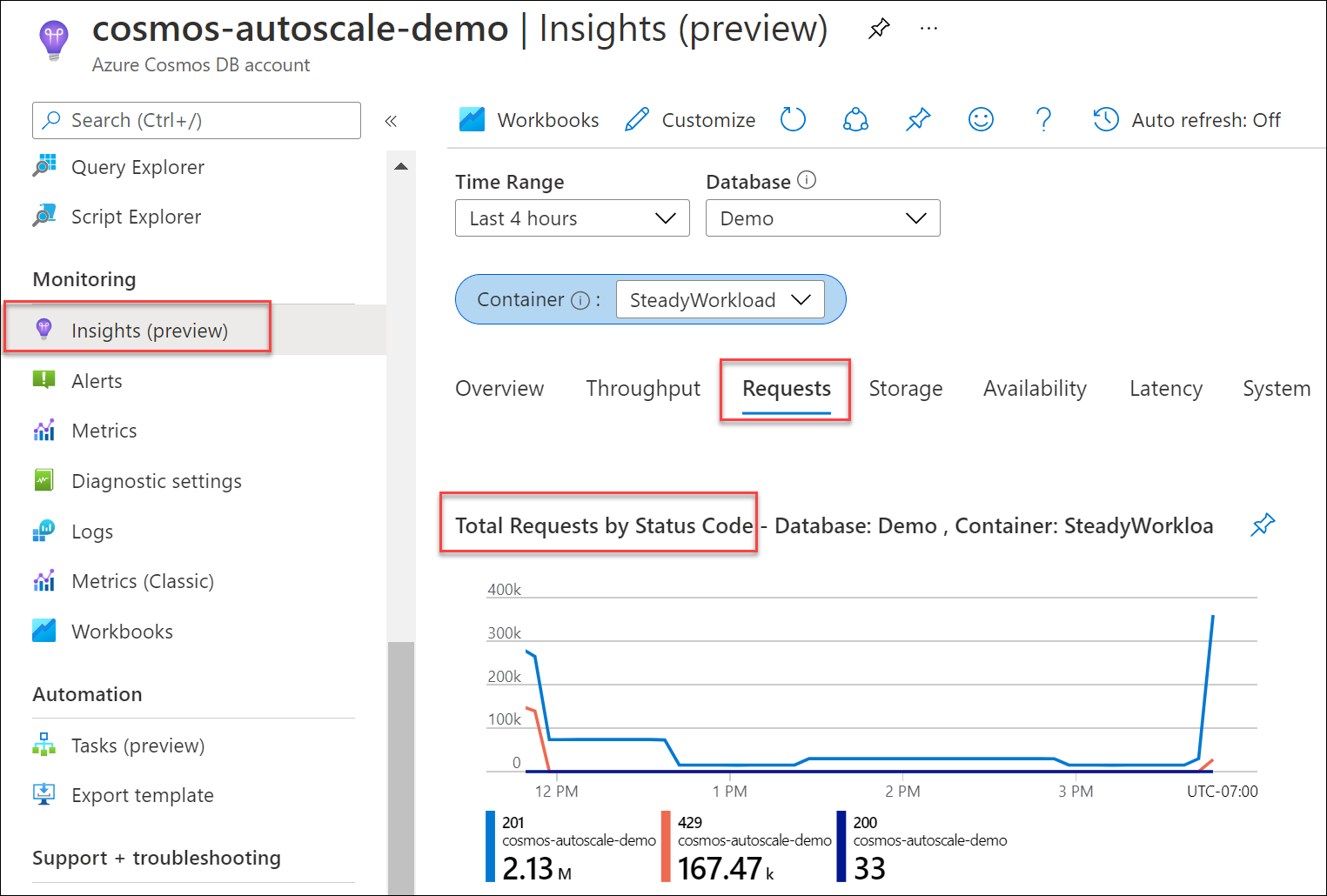
与成功请求的总计数进行比较,确定出现 429 响应错误的数据库或容器请求所占的百分比。 从“Azure Cosmos DB 帐户”中,导航到“见解”“请求”>“按状态代码显示的请求总数”。 筛选到特定数据库和容器。
默认情况下,Azure Cosmos DB 客户端 SDK 和数据导入工具(如 Azure 数据工厂和批量执行工具库)会自动重试提交出现 429 错误的请求。 重试次数通常最多为九次。 因此,虽然可以在指标中看到 429 个响应,但这些错误甚至可能尚未返回到应用程序。
建议的解决方案
通常,对于生产工作负荷,如果您观察到 1-5% 的请求返回 429 响应状态码,并且端到端延迟是可以接受的,则这表明 RU/s 正在被充分利用。 不需要执行任何操作。 否则,请继续执行接下来的故障排除步骤。
重要
此 1-5% 范围假定帐户分区均匀分布。 如果分区未均匀分布,则问题分区可能会返回大量 429 错误,而总体速率可能较低。
如果使用自动缩放,即使 RU/秒值未扩展到最大 RU/秒,也可能会在数据库或容器上看到 429 响应错误。 有关说明,请参阅 “请求速率较大并且自动缩放”部分。
客户提出的一个常见问题是,“为何我在 Azure Monitor 指标中看到了 429 响应错误,但在我自己的应用程序监视中却没有看到?”如果 Azure Monitor 指标显示了 429 响应错误,但你在自己的应用程序中未看到这种错误,则原因是默认情况下,Azure Cosmos DB 客户端 SDK 和请求在后续的重试中已成功。 因此,不会向应用程序返回 429 状态代码。 在这种情况下,429 响应错误的总体比率通常最小(假设总体比率为 1-5%),可以放心地忽略,并且端到端延迟对于应用程序是可接受的。
步骤 2:确定是否存在热分区
当一个或几个逻辑分区键由于请求量较高而消耗了过多的总 RU/s 时,即会出现热分区。 而造成这一情况的原因可能是分区键设计导致请求未能均匀分布。 这会导致许多请求被定向到几个逻辑分区(也就是物理分区)的小子集,这些分区会变成热点。 由于逻辑分区的所有数据都驻留在一个物理分区上,RU/s 总数均匀分布在物理分区之间,因此热分区可能会导致 429 个响应和低效的吞吐量使用。
下面是导致热分区的一些分区策略示例:
你有一个容器,用于存储通过
date分区的写入密集型工作负载的 IoT 设备数据。 单个日期的所有数据都驻留在同一逻辑分区和物理分区上。 由于每天写入的所有数据都具有相同的日期,因此每天都会生成热分区。- 相反,在这种情况下,使用类似
id(例如 GUID 或设备 ID)作为分区键,或者使用合成分区键(通过组合id和date),可以得到更高的值基数,并更好地分配请求量。
- 相反,在这种情况下,使用类似
你有一个多租户场景,其中的容器是按
tenantId分区的。 如果一个租户的活跃性明显高于其他租户,则会导致热分区。 举例来说,如果最大租户有 100,000 名用户,但大多数租户的用户数少于 10 人,则按tenantID分区时,将会产生热分区。- 对于上述方案,应考虑为最大租户创建专用容器,并按更精细的属性(如
UserId)进行分区。
- 对于上述方案,应考虑为最大租户创建专用容器,并按更精细的属性(如
如何识别热分区
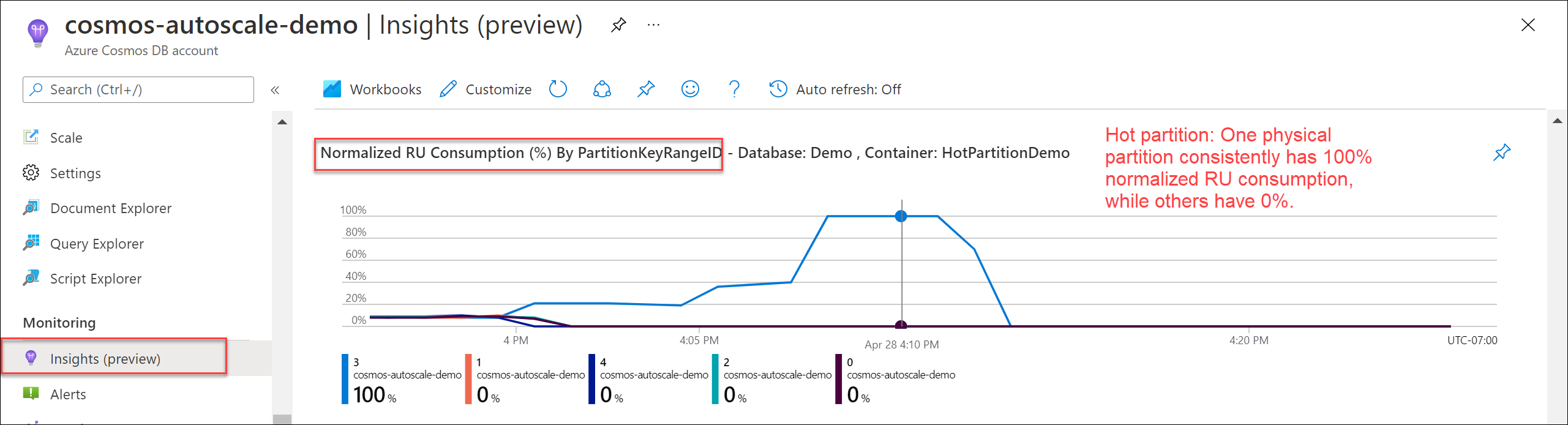
若要验证是否存在热分区,请导航到“见解”“吞吐量”>“按 PartitionKeyRangeID 列出的规范化 RU 消耗量(%)”。 筛选到特定数据库和容器。
每个分区键范围 ID 映射到一个物理分区。 如果有一个 PartitionKeyRangeId 比其他分区高得多的 规范化 RU 消耗 (例如,一个始终在 100%,但其他分区为 30% 或更少),则可以是热分区的标志。 若要详细了解规范化 RU 消耗指标,请参阅 如何监视 Azure Cosmos DB 容器或帐户的规范化 RU/s。
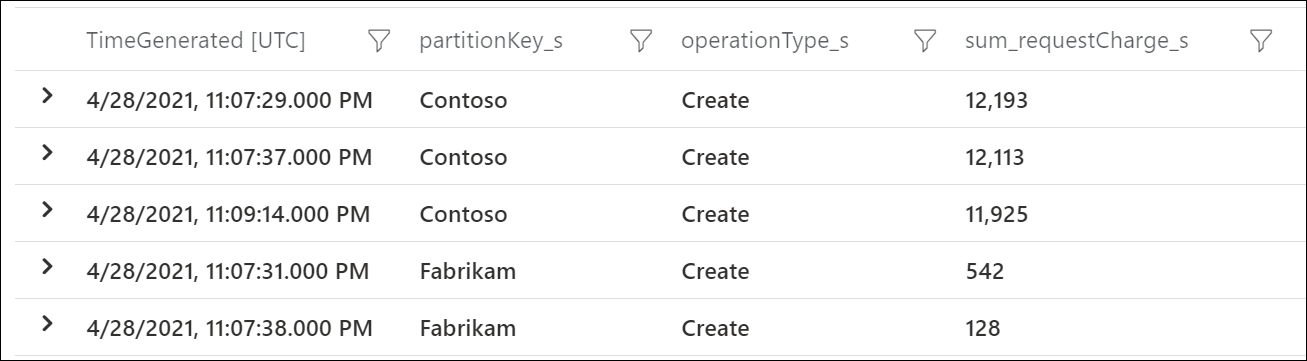
若要查看哪些逻辑分区键使用最多的 RU/秒,请使用 Azure 诊断日志。 此示例查询汇总了每个逻辑分区键每秒消耗的请求单位总数。
重要
启用诊断日志将单独产生 Log Analytics 服务费(按引入的数据量计费)。 建议出于调试目的启用诊断日志有限的一段时间,在不需要诊断日志时将其禁用。 若要了解详细信息,请参阅Azure Monitor 定价。
CDBPartitionKeyRUConsumption
| where TimeGenerated >= ago(24hour)
| where CollectionName == "CollectionName"
| where isnotempty(PartitionKey)
// Sum total request units consumed by logical partition key for each second
| summarize sum(RequestCharge) by PartitionKey, OperationName, bin(TimeGenerated, 1s)
| order by sum_RequestCharge desc
此示例输出显示,在特定分钟内,值为 Contoso 的逻辑分区键消耗了大约 12,000 RU/秒,而值为 Fabrikam 的逻辑分区键消耗了小于 600 RU/秒。 如果此模式在速率受限发生期间一直存在,则表明存在热分区。
提示
在任何工作负荷中,请求数量在逻辑分区之间自然变化。 你应当确定导致产生热分区的原因是因分区键选择造成的基本偏斜(可能需要更改分区键)还是因工作负荷模式的自然变化而暂时出现峰值。
建议的解决方案
查看有关如何选择良好分区键的指导。
如果受到速率限制的请求百分比较高,但未出现热分区:
- 可以使用客户端 SDK、Azure 门户、PowerShell、CLI 或 ARM 模板增加数据库或容器的 RU/s。 按照缩放预配吞吐量(RU/秒)的最佳做法,确定要设置的正确 RU/秒。
如果受到速率限制的请求百分比较高,并出现了根本性的热分区:
- 从长远来看,为了获得最佳成本和性能,请考虑 更改分区键。 无法就地更新分区键,因此,这需要将数据迁移到具有不同分区键的新容器。 Azure Cosmos DB 支持使用实时数据迁移工具来实现此目的。
- 短期内,可以暂时提高资源的总体 RU/秒,以便让热分区拥有更多的吞吐能力。 不建议将此用作长期策略,因为它会导致每秒 RU 数过度预配和增加成本。
提示
增加吞吐量时,横向扩展操作可以即时完成,或者需要长达 5-6 小时才能完成,具体取决于您要扩展到的 RU/s 数量。 若要了解在不触发异步纵向扩展操作(需要使用 Azure Cosmos DB 预配更多物理分区)的情况下,可以设置的最高 RU/s 数,请将不同的分区键范围 ID 乘以 100,000 RU/s。 例如,如果预配了 30,000 RU/s 和 5 个物理分区(每个物理分区分配 6000 RU/秒),则可以在即时纵向扩展作中增加到 50,000 RU/秒(每物理分区 10,000 RU/秒)。 但若要将 RU/s 数增至 50,000 RU/s 以上,则需要执行异步纵向扩展操作。 若要了解详细信息,请参阅 有关缩放预配吞吐量(RU/s)的最佳做法。
步骤 3:确定返回 429 响应错误的请求
如何调查出现 429 响应错误的请求
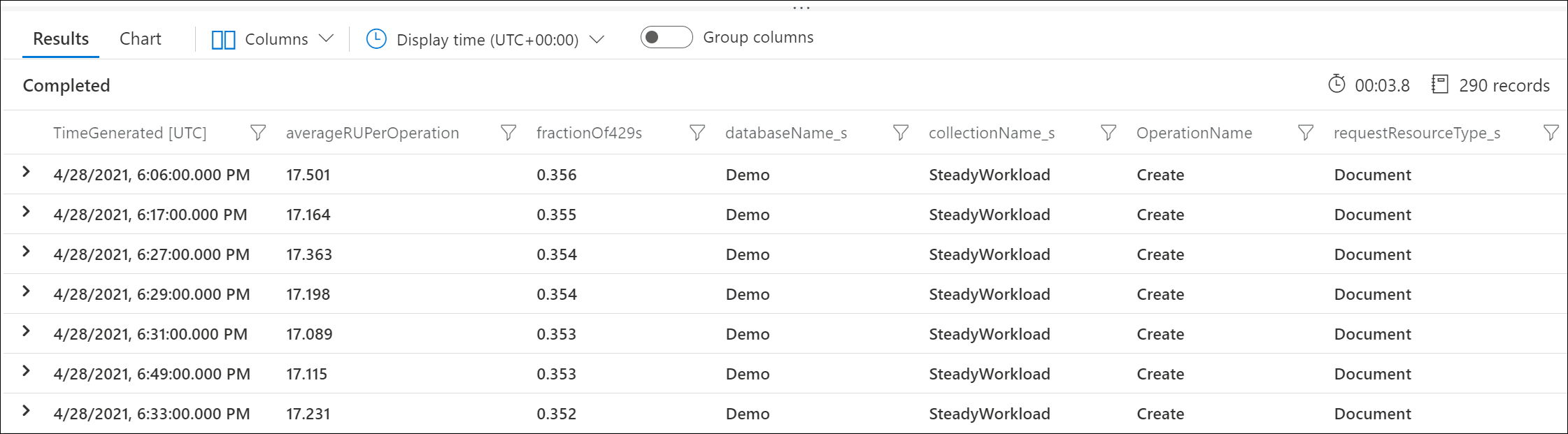
使用 Azure 诊断日志来确定返回 429 响应错误的请求,以及这些请求消耗的 RU 数。 此示例查询按分钟聚合。
重要
启用诊断日志将单独产生 Log Analytics 服务费(按引入的数据量计费)。 建议出于调试目的启用诊断日志有限的一段时间,在不需要诊断日志时将其禁用。 若要了解详细信息,请参阅Azure Monitor 定价。
CDBDataPlaneRequests
| where TimeGenerated >= ago(24h)
| summarize throttledOperations = dcountif(ActivityId, StatusCode == 429), totalOperations = dcount(ActivityId), totalConsumedRUPerMinute = sum(RequestCharge) by DatabaseName, CollectionName, OperationName, RequestResourceType, bin(TimeGenerated, 1min)
| extend averageRUPerOperation = 1.0 * totalConsumedRUPerMinute / totalOperations
| extend fractionOf429s = 1.0 * throttledOperations / totalOperations
| order by fractionOf429s desc
例如,此示例输出显示,每分钟有 30% 的创建文档请求受到速率限制,而每个请求平均消耗 17 个请求单位(RU)。
建议的解决方案
使用 Azure Cosmos DB 容量规划器
可以使用 Azure Cosmos DB 容量规划器,了解什么是基于工作负载(操作量和类型以及文档大小)的最佳预配吞吐量。 可以通过提供示例数据来进一步自定义计算,以获得更准确的估计。
创建、替换或更新插入文档请求时出现 429 响应错误
默认情况下,API for NoSQL 会默认对所有属性都编制索引。 你可以调整索引策略,以仅对所需属性编制索引。 这会降低每个创建文档操作所需的 RU,从而减少出现 429 响应的可能性,或者允许你在相同预配的 RU/秒下实现更高的每秒操作次数。
查询文档请求时出现 429 响应错误
按照指南 排查 RU 费用过高的查询问题。
执行存储过程时出现 429 响应错误
存储过程适用于需要跨分区键值写入事务的操作。 不建议将存储过程用于大量的读取或查询操作。 要获得最佳性能,应在客户端使用 Azure Cosmos DB SDK 完成这些读取或查询操作。
使用自动缩放时请求速率过大
本文中的所有指导适用于手动吞吐量和自动缩放吞吐量。
使用自动缩放时,出现的一个常见问题是 “是否可以使用自动缩放查看 429 个响应?”
答案是 肯定的。 有两种主要方案可以发生这种情况:
方案 1:当消耗的总 RU/秒超过数据库或容器的最大 RU/秒时,服务会相应地限制请求。 这类似于超过了数据库或容器的总体手动预配吞吐量。
方案 2:如果有热分区(即逻辑分区键值)与其他分区键值相比请求量不成比例地高,则基础物理分区可能超出其 RU/秒预算。 为避免出现热分区,最佳做法是选择良好的分区键,从而实现存储和吞吐量的均匀分布。 这类似于使用手动吞吐量时存在热分区的情况。
例如,如果选择“20,000 RU/秒最大吞吐量”选项,并且 200 GB 的存储空间包含 4 个物理分区,则每个物理分区最多可以自动扩展到 5000 RU/秒。 如果某个特定逻辑分区键上存在热分区,则当它所在的基础物理分区超过 5000 RU/秒(即超出了 100% 的标准化利用率)时,将会出现 429 响应错误。
按照步骤 1、步骤 2 和步骤 3 中的指导针对这些场景进行调试。
另一个常见问题是,“为何规范化 RU 消耗量 100%,但自动缩放未扩展到最大 RU/秒?”
这种情况通常发生在临时或间歇性达到使用量高峰的工作负载上。 使用自动缩放时,仅当规范化 RU 消耗量在 5 秒间隔内持续稳定地保持 100% 时,Azure Cosmos DB 才会将 RU/秒扩展到最大吞吐量。 这是为了确保缩放逻辑的成本对用户可接受,避免单次短暂性的高峰导致不必要的扩展和提高成本。 在出现短暂性的高峰时,系统通常会扩展到一个比上次所扩展到的 RU/秒更高,但比最大 RU/秒更低的值。 如需了解更多信息,请参阅 规范化 RU 消耗和自动缩放。
元数据请求速率受限
对数据库和/或容器执行大量元数据操作时,可能会发生元数据速率受限问题。 元数据操作包括:
- 创建、读取、更新或删除容器或数据库
- 列出 Azure Cosmos DB 帐户中的数据库或容器
- 查询产品/服务,以查看当前预配的吞吐量
对于这些操作,系统有保留的 RU 限制,因此增加数据库或容器的预配的 RU/s 并不起作用,不建议这样做。 请参阅控制平面服务限制。
调查方式
导航到“见解”“系统”>“按状态代码显示的元数据请求”。 根据需要,筛选到特定数据库和容器。
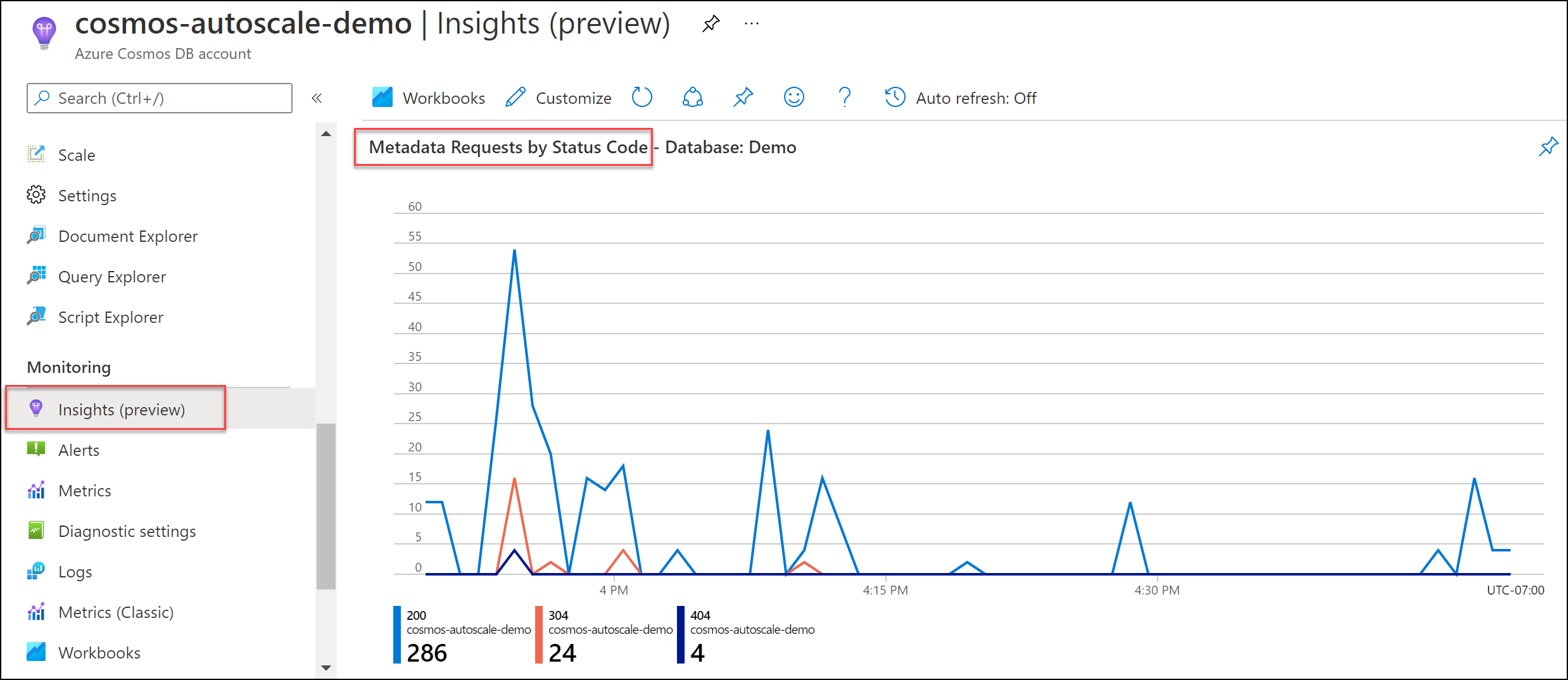
建议的解决方案
如果应用程序需要执行元数据操作,请考虑实施回退策略以降低该等请求的发送速率。
使用静态 Azure Cosmos DB 客户端实例。 初始化 DocumentClient 或 CosmosClient 时,Azure Cosmos DB SDK 将提取有关该帐户的元数据,包括与一致性级别、数据库、容器、分区以及产品/服务相关的信息。 此初始化可能会消耗大量 RU,并且不经常执行。 在应用程序的生存期内使用单个 DocumentClient 实例。
缓存数据库和容器名称。 从配置中检索数据库和容器的名称,或者一开始就将其缓存。 调用(如 ReadDatabaseAsync/ReadDocumentCollectionAsync 或 CreateDatabaseQuery/CreateDocumentCollectionQuery)会导致对服务进行元数据调用,这会消耗系统预留的 RU 限额。 因此,你应该避免频繁执行此类操作。
因暂时性服务错误而导致速率受限
当请求遇到暂时性服务错误时,系统将返回此 429 错误。 增加数据库或容器上的 RU/s 不起作用,不建议这样做。
建议的解决方案
重试请求。 如果数分钟后错误仍然存在,请从 Azure 门户提交支持票证。