本文介绍支持 Azure Monitor 平台指标和自定义指标的时序数据库中指标的聚合。 本文还适用于标准 Application Insights 指标。
本文中的信息很复杂,适用于想要深入了解指标系统的用户。 无需了解它即可有效地使用 Azure Monitor 指标。
概述和术语
将指标添加到图表时,指标资源管理器会自动预先选择其默认聚合。 默认值在基本方案中适用,但可以使用不同的聚合来获得有关指标的更多见解。 查看图表上的不同聚合时需要了解指标资源管理器处理它们的方式。
首先明确定义几个术语:
- 指标值 - 为特定资源收集的单个度量值。
- 时序数据库 - 针对存储和检索数据点而优化的数据库,所有这些数据点都包含一个值和与之对应的时间戳。
- 时间段 - 一段普通时间。
- 时间间隔 - 收集两个指标值之间的时间段。
- 时间范围 - 图表上显示的时间段。 典型默认值为 24 小时。 只有特定范围可用。
- 时间粒度 - 用于将值聚合在一起以便在图表上显示的时间段。 只有特定范围可用。 当前最小值为 1 分钟。 时间粒度值应小于所选时间范围才有用,否则整个图表仅显示一个值。
- 聚合类型 - 通过多个指标值计算得出的一种统计信息。
- 聚合 - 获取多个输入值,然后使用这些值通过聚合类型定义的规则生成单个输出值的过程。 例如,获取多个值的平均值。
进程摘要
指标是一系列带时间戳存储的值。 在 Azure 中,大多数指标存储在 Azure 指标时序数据库中。 在绘制图表时,系统可从数据库中检索所选指标的值,然后根据所选的时间粒度(亦称“粒度”)单独聚合这些值。 可使用指标资源管理器时间选取器选择时间粒度的大小。 如果未进行显式选择,则根据当前选择的时间范围自动选择时间粒度。 选择后,在每个时间粒度间隔期间捕获的指标值将聚合并放置在图表上 - 每个间隔一个数据点。
聚合类型
指标资源管理器中提供了五种基本的聚合类型。 指标浏览器会隐藏那些与给定指标不相关或无法使用的聚合。
- Sum - 在聚合间隔内捕获的所有值的总和。 有时称为总聚合。
- Count - 在聚合间隔内捕获的度量的数目。 Count 不会查看度量值,而只会查看记录数。
- Average - 在聚合间隔内捕获的指标值的平均值。 对于大多数指标,此值为 Sum/Count。
- Min - 在聚合间隔内捕获的最小值。
- Max - 在聚合间隔内捕获的最大值。
例如,假设一个图表显示了在过去 24 小时的时间范围内使用 SUM 聚合的 VM 的“网络输出总量”指标 。 如以下屏幕截图所示,可以从图表的右上方更改时间范围和粒度。
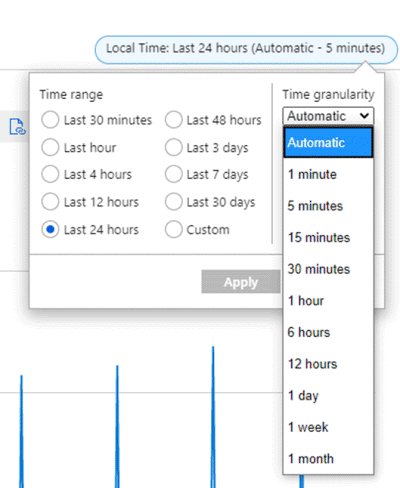
如果时间粒度为 30 分钟,时间范围为 24 小时:
- 通过 48 个数据点绘制图表。 即 24 小时 x 每小时 2 个数据点(60 分钟/30 分钟)聚合 1 分钟数据点。
- 折线图在图表绘图区域中连接 48 个点。
- 每个数据点表示在每个相关的 30 分钟时间段内发出的所有网络输出字节数的总和。

单击此部分中的图像可查看大图。
如果将时间粒度切换成 15 分钟,则将通过 96 个聚合数据点绘制图表。 也就是说,60 分钟/15 分钟 = 每小时 4 个数据点 x 24 小时。

如果时间粒度为 5 分钟,你将获得 24 x (60/5) = 288 个点。
如果时间粒度为 1 分钟(图表上可能的最小值),你将获得 24 x 60/1 = 1440 个点。

如前面的屏幕截图所示,图表的这些汇总看起来有所不同。 请注意此 VM 如何在一个较小的时间段内(相对于时间窗口的其余部分)提供许多输出。
使用时间粒度,你可以调整图表上的“信噪比”。 更高的聚合可消除噪点并使尖峰趋于平滑。 注意底部 1 分钟图表的变化,以及它们如何随着使用更高粒度值而趋于平滑。
在将此数据发送到其他系统(例如警报)时,此平滑行为非常重要。 通常,你不希望当 CPU 在短时间内达到超过 90% 的尖峰时收到警报。 但是,如果 CPU 在 5 分钟内保持为 90%,这可能很重要。 如果在 CPU(或任何指标)上设置警报规则,则将时间粒度设置为更大的值可减少收到的错误警报数。
请务必确定工作负载的正常值以了解最佳时间间隔。 这是动态警报的优势之一,这里不对此主题进行介绍。
系统如何收集指标
数据收集因指标而异。
注释
下面的示例为了便于说明进行了简化,每个聚合中包含的实际指标数据受计算时可用的数据的影响。
度量值收集频率
有两种类型的收集周期。
定期 - 以不会发生变化的一致时间间隔收集指标。
基于活动 - 根据特定类型的事务发生的时间收集指标。 每个事务都有一个指标条目和一个时间戳。 由于收集并非定期进行,因此,在给定的时间段内存在不同的记录数。
粒度
最小时间粒度为 1 分钟,但基础系统可能会根据指标更快地捕获数据。 例如,按 15 秒的时间间隔捕获 Azure VM 的 CPU 百分比。 由于 HTTP 失败作为事务进行跟踪,因此它们很容易超过一分钟一次以上。 其他指标(例如 SQL 存储)按 20 分钟的时间间隔进行捕获。 此选择取决于具体资源提供商和资源类型。 大多数都尽量提供最小时间间隔。
维度、拆分和筛选
为每个资源收集指标。 但是,收集、存储和用图表绘制指标的级别可能会有所不同。 此级别由“指标维度”中提供的其他指标表示。 每个单独的资源提供程序都可以定义其收集的数据的详细程度。 Azure Monitor 仅定义应如何显示和存储此类详细信息。
在指标资源管理器中绘制指标图表时,可以选择按维度“拆分”图表。 拆分图表意味着查看基础数据以获取更多详细信息,并在指标资源管理器中查看绘制成图表或筛选的数据。
例如,Microsoft.ApiManagement/service 将“位置”作为多种指标的维度。
“容量”就是一个这样的指标。 具有“位置”维度意味着,基础系统将存储每个位置的容量的指标记录,而不是总量的一个指标记录。 然后,你可以在指标图表中检索或拆分该信息。
查看“网关请求的总持续时间”,有 2 个维度“位置”和“主机名”,再次让你了解持续时间的位置以及它所来自的主机名。
“请求”是一个更灵活的指标,具有 7 个不同的维度。
有关每个指标和可用维度的详细信息,请查看 Azure Monitor 文章中支持的指标 。 另外,每个资源提供程序和类型的相关文档可能会提供有关维度及其度量内容的其他信息。
可以结合使用拆分和筛选来深入了解问题。 下面是一个图形示例,其中显示了资源组中一组 VM 的平均磁盘写入字节数。 我们汇总了具有此指标的所有 VM,但我们可能想要深入了解是哪些 VM 造成了早上 6 点左右的高峰。 它们是否是相同的计算机? 涉及多少台计算机?

单击此部分中的图像可查看大图。
应用拆分时,可以看到基础数据,但这些数据有点混乱。 原来有 20 个 VM 被聚合到上面的图表中。 在这种情况下,我们将鼠标悬停在早上 6 点的大高峰上,此高峰告知我们原因为 CH-DCVM11。 但是,由于其他 VM 打乱了图表,因此很难看到与该 VM 相关的其余数据。

使用筛选可以清理图表,帮助我们更好地了解实际情况。 您可以选择或取消选择要查看的虚拟机。 请注意虚线。 后面部分将介绍这些内容。

有关如何在指标资源管理器图表上显示拆分维度数据的详细信息,请参阅 “使用维度筛选器和拆分”。
NULL 值和零值
当系统需要来自资源的指标数据但未收到该数据时,它将记录一个 NULL 值。 NULL 值不同于零值,它在计算聚合和绘制图表时非常重要。 NULL 值不计为有效度量值。
NULL 值在不同图表上以不同方式显示。 散点图跳过在图表上显示点。 条形图跳过显示条形。 在折线图中,NULL 值可显示为点或虚线,如上一部分屏幕截图中所示。 计算包含 NULL 值的平均值时,要用于计算平均值的数据点较少。 此行为有时会导致图表上的数值意外下降,不过比将数值转换为零后作为有效数据点使用时的下降程度要轻微。
未收到任何数据时,自定义指标始终使用 null。 使用平台指标,每个资源提供程序都可以根据最适合给定指标的情况决定是使用零值还是 NULL 值。
Azure Monitor 警报使用资源提供程序写入指标数据库的值,因此先查看数据,了解资源提供程序如何处理 NULL 值非常重要。
聚合的工作方式
前面系统中的指标图表显示了不同类型的聚合数据。 系统对数据进行预先聚合,以便请求的图表可以更快地显示,而无需多次重复计算。
在本示例中:
- 我们正在收集一个名为“HTTP 失败”的虚构事务指标
- “服务器”是“HTTP 失败”指标的一个维度。
- 我们有 3 个服务器 - 服务器 A、B 和 C。
为了简化说明,我们将仅从 SUM 聚合类型开始。
亚分钟到 1 分钟聚合
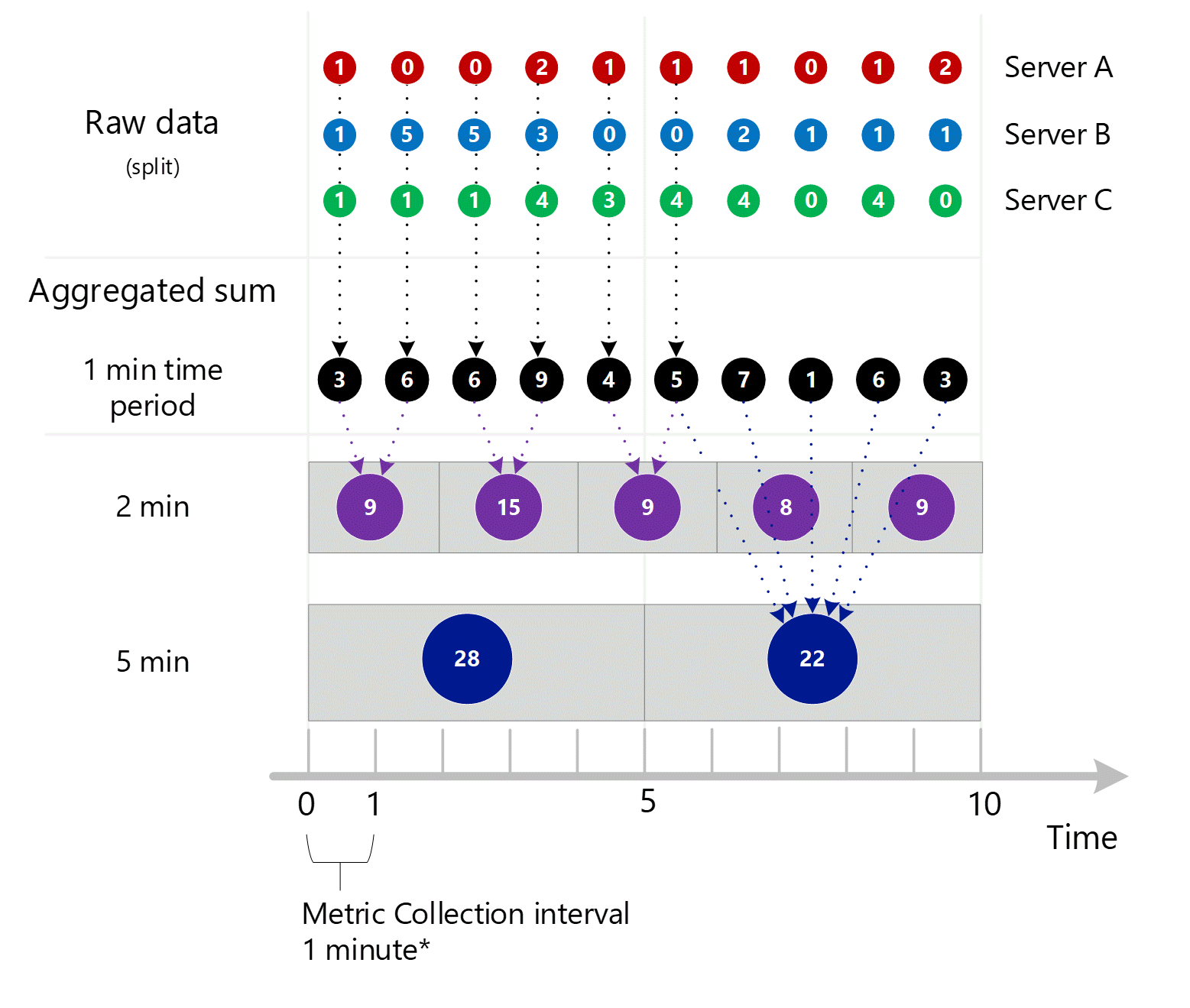
首先收集原始指标数据并将其存储在 Azure Monitor 指标数据库中。 在此用例中,由于“服务器”是一个维度,因此每个服务器都存储了带时间戳的事务记录。 假设你作为客户可以查看的最小时间段为 1 分钟,则这些时间戳将首先聚合为每个单独服务器的 1 分钟指标值。 服务器 B 的聚合过程如下图所示。 服务器 A 和 C 以相同的方式完成,但其数据不同。
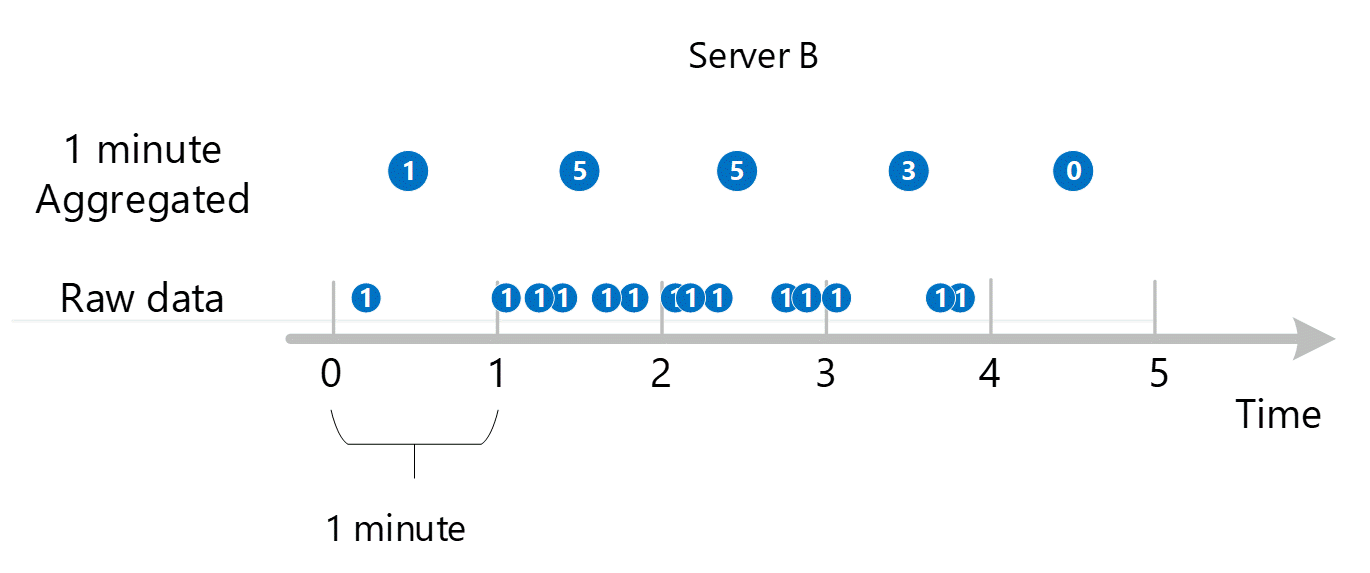
生成的 1 分钟聚合值作为新条目存储在指标数据库中,以便可以收集这些值以供后续计算。
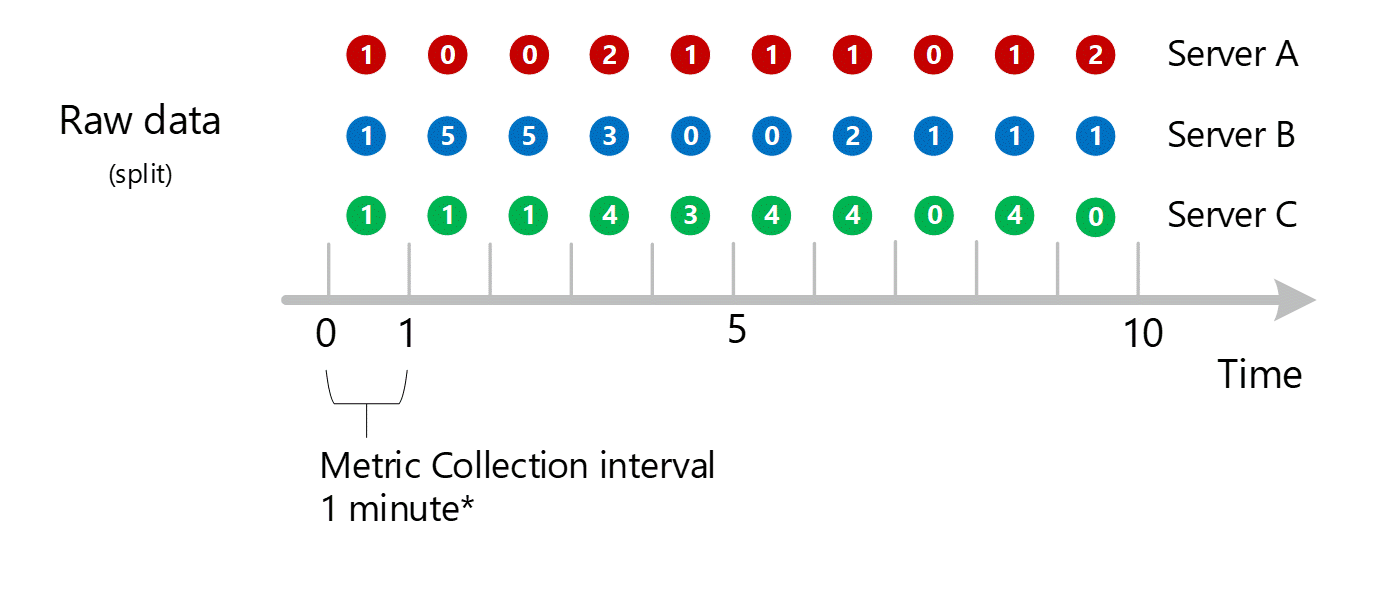
维度聚合
对 1 分钟的计算按维度进行汇总,然后作为单个记录再次存储。 在此示例中,所有单个服务器的所有数据都聚合为 1 分钟间隔指标,并存储在指标数据库中,以供在之后的聚合中使用。
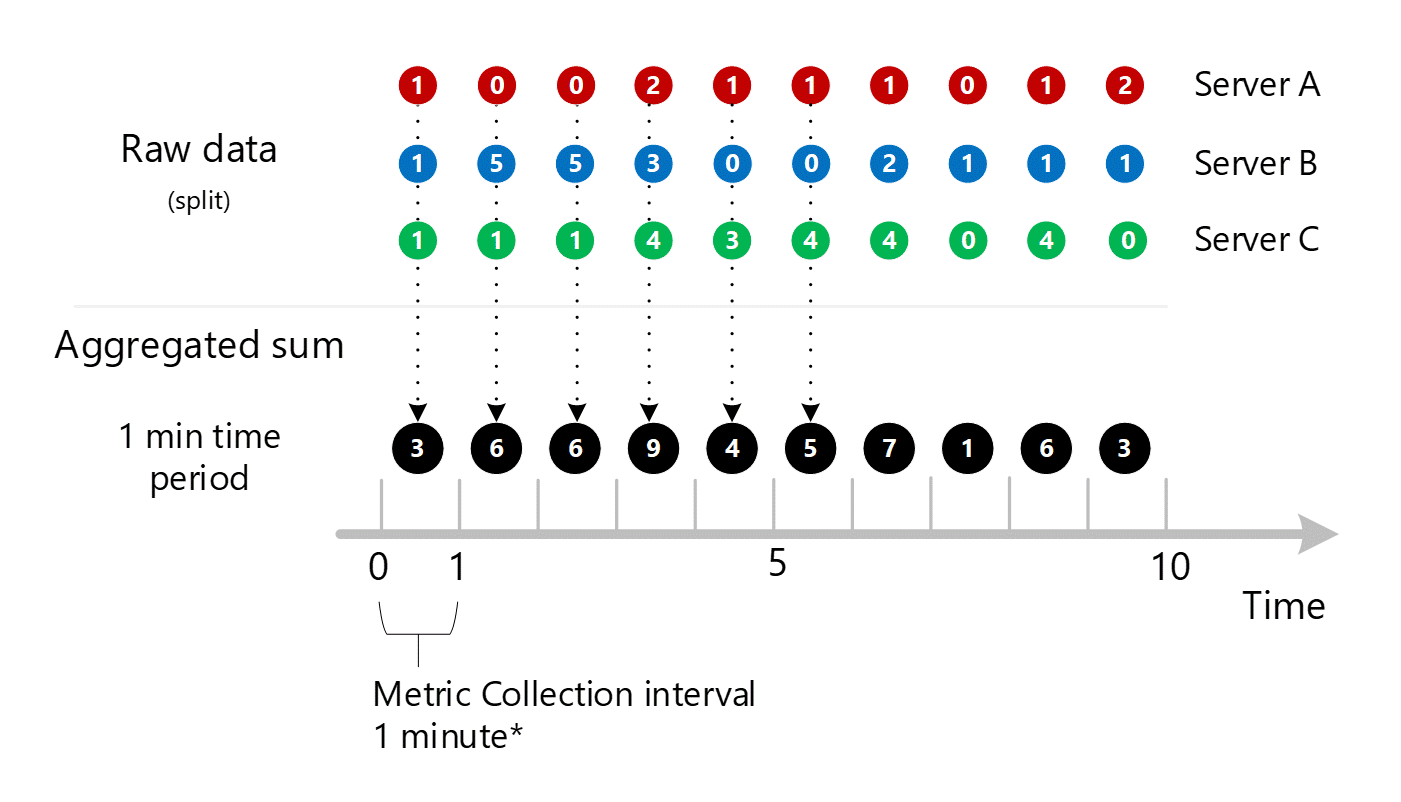
为清楚起见,下表显示了聚合方法。
| 期限 | 服务器 A | 服务器 B | 服务器 C | 总和 (A+B+C) |
|---|---|---|---|---|
| 第 1 分钟 | 1 | 1 | 1 | 3 |
| 第 2 分钟 | 0 | 5 | 1 | 6 |
| 第 3 分钟 | 0 | 5 | 1 | 6 |
| 第 4 分钟 | 2 | 3 | 4 | 9 |
| 第 5 分钟 | 1 | 0 | 3 | 4 |
| 第 6 分钟 | 1 | 0 | 4 | 5 |
| 第 7 分钟 | 1 | 2 | 4 | 7 |
| 第 8 分钟 | 0 | 1 | 0 | 1 |
| 第 9 分钟 | 1 | 1 | 4 | 6 |
| 第 10 分钟 | 2 | 1 | 0 | 3 |
上面仅显示了一个维度,但此相同的聚合和存储过程适用于指标支持的所有维度。
- 将值收集到该维度的 1 分钟聚合集中。 存储这些值。
- 将维度折叠为 1 分钟聚合 SUM。 存储这些值。
接下来介绍称为 NetworkAdapter 的 HTTP 失败的另一个维度。 假设每个服务器的适配器数各不相同。
- 服务器 A 具有 1 个适配器
- 服务器 B 具有 2 个适配器
- 服务器 C 具有 3 个适配器
我们将分别收集以下交易的数据。 它们将被标记为:
- 时间
- 值
- 交易来源的服务器
- 事务来自的适配器
然后,将每个亚分钟流聚合为 1 分钟时序值,并存储在 Azure Monitor 指标数据库中:
- 服务器 A,适配器 1
- 服务器 B,适配器 1
- 服务器 B,适配器 2
- 服务器 C,适配器 1
- 服务器 C,适配器 2
- 服务器 C,适配器 3
此外,还将存储以下折叠的聚合:
- 服务器 A,适配器 1(由于没有要折叠的内容,它将再次存储)
- 服务器 B,适配器 1+2
- 服务器 C,适配器 1+2+3
- 所有服务器,所有适配器
这表明具有大量维度的指标具有更多的聚合。 了解所有排列并不重要,只需了解推理即可。 系统需要同时存储单独的数据和聚合数据,以便快速检索以访问任何图表。 系统会根据你选择要显示的内容选择最相关的存储聚合或基础原始数据。
无维度的聚合
由于此指标具有“服务器”维度,因此,你可以通过拆分和筛选来访问上述服务器 A、B 和 C 的基础数据,如本文前面所述。 如果指标没有“服务器”维度,则你作为客户只能访问图表上以黑色显示的聚合 1 分钟总和。 即 3、6、6、9 等数值。系统也不会进行底层工作来聚合拆分的值,它绝不会在指标浏览器中使用这些值或通过指标 REST API 发送出去。
查看超过 1 分钟的时间粒度
如果你需要更大粒度的指标,系统将使用 1 分钟聚合总和来计算更大时间粒度的总和。 下面的虚线显示了 2 分钟和 5 分钟时间粒度的求和方法。 同样,为了简单起见,我们只显示 SUM 聚合类型。
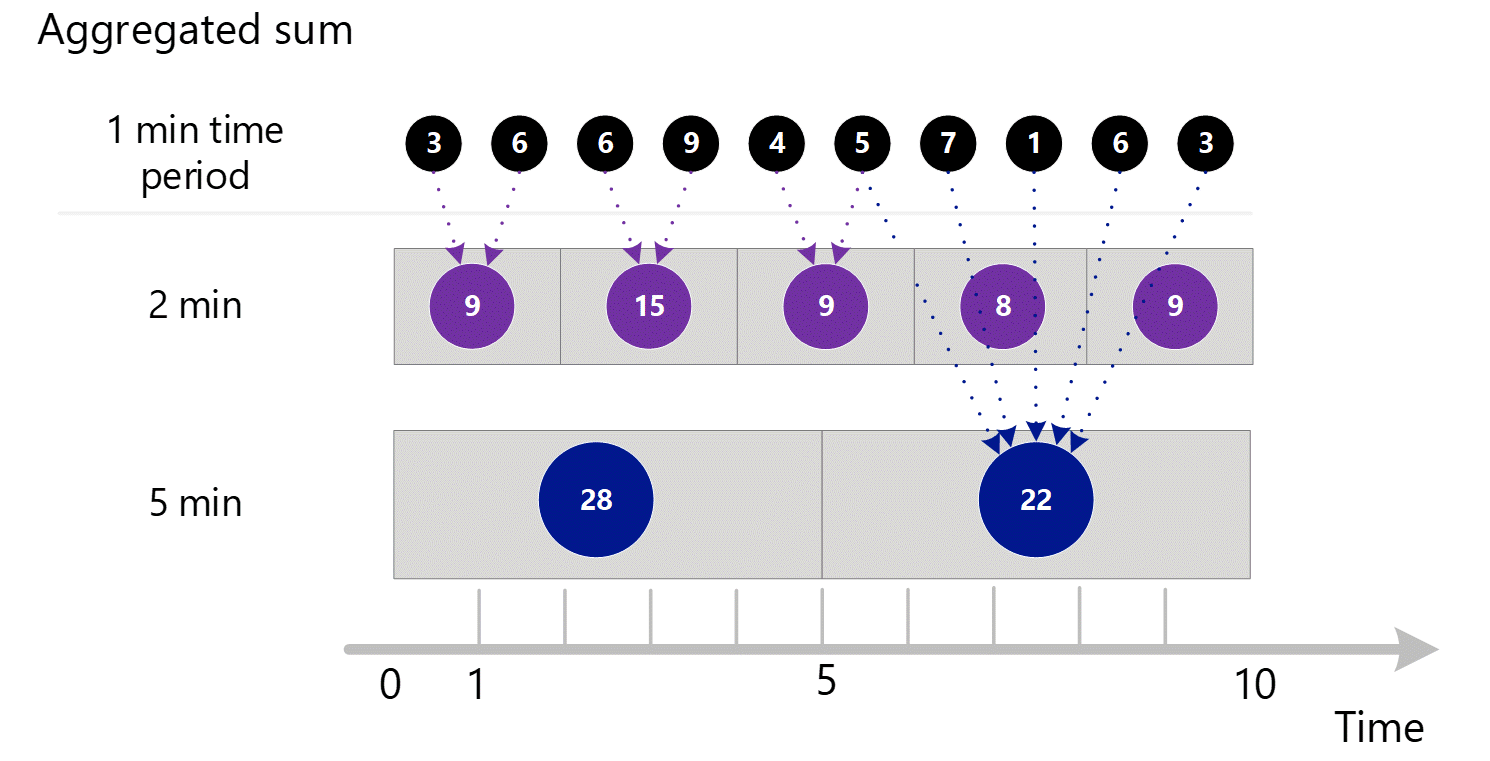
对于 2 分钟时间粒度。
| 期限 | 总和 |
|---|---|
| 第 1 分钟和第 2 分钟 | (3 + 6) = 9 |
| 第 3 分钟和第 4 分钟 | (6 + 9) = 15 |
| 第 4 分钟和第 5 分钟 | (4 + 5) = 9 |
| 第 6 分钟和第 7 分钟 | (7 + 1) = 8 |
| 第 8 分钟和第 9 分钟 | (6 + 3) = 9 |
对于 5 分钟时间粒度。
| 期限 | 总和 |
|---|---|
| 第 1 分钟到第 5 分钟 | 3 + 6 + 6 + 9 + 4 = 28 |
| 第 6 分钟到第 10 分钟 | 5 + 7 + 1 + 6 + 3 = 22 |
系统使用存储的聚合数据,从而获得最佳性能。
下面是上述 1 分钟聚合过程的大图,其中,为提高可读性,略去了一些箭头。
更复杂的示例
下面是一个更大的示例,它使用了称为 HTTP 响应时间(以毫秒为单位)的虚构指标值。 在这里,我们引入了其他级别的复杂性。
- 我们展示求和、计数、最小值和最大值的聚合,以及平均值的计算。
- 我们将展示 NULL 值以及它们对计算的影响。
请考虑以下示例。 框和箭头显示了一些示例,说明如何聚合和计算这些值。
上一部分中所述的相同的 1 分钟预聚合过程用于求和、计数、最小值和最大值。 但是,Average 不是预先聚合的。 系统将使用聚合数据对该值重新进行计算,以避免计算错误。

考虑上面突出显示的 1 分钟聚合的第 6 分钟。 这一分钟是服务器 B 脱机并停止报告数据(可能因为重启)的时间点。
从上面的第 6 分钟开始,计算的 1 分钟聚合类型为:
| 聚合类型 | 价值 | 注释 |
|---|---|---|
| 总和 | 53+20=73 | |
| 计数 | 2 | 显示 NULL 的效果。 如果服务器已联机,则值为 3。 |
| 最小值 | 20 | |
| 最大值 | 53 | |
| 平均值 | 73/2 | 始终是总和除以计数。 该值从不存储,而是始终使用针对每个时间粒度的聚合数字进行重新计算。 请注意上面突出显示的 5 分钟和 10 分钟时间粒度的重新计算。 |
红色字体表示可能被视为超出正常范围的值,并显示它们如何(或未能)随着时间粒度的增加而传播。 请注意,Min 和 Max 指示存在潜在异常,而 Average 和 Sums 则随着时间粒度的增加而丢失该信息 。
你还可以看到,计算平均值时,使用 NULL 值比使用零值要好。
注释
虽然在此示例中并非是这样,但在捕获的指标值始终为 1 的情况下,Count 等同于 Sum 。 当指标跟踪事务事件的出现次数时,这种情况很常见 - 例如,本文前面的示例中提到的 HTTP 失败数。