批处理分析 API 允许使用一个请求批量处理多达 10,000 个文档。 可以同时分析发票、贷款文件或自定义文档等文档集合,而不是逐个分析文档并跟踪其各自的请求 ID。 输入文档必须存储在 Azure Blob 存储容器中。 处理文档后,API 会将结果写入指定的存储容器。
批处理分析限制
- 单个批处理请求中的文档文件的最大数目为 10,000。
- 批处理作结果在完成后保留 24 小时。 批处理完成 24 小时后,批作状态不再可用。 输入文档和相应的结果文件保留在提供的存储容器中。
先决条件
有效的 Azure 订阅。 如果没有 Azure 订阅,可以 创建一个用于试用的订阅。
文档智能 Azure 资源:拥有 Azure 订阅后,在 Azure 门户中创建文档智能资源。 可以使用免费定价层(F0)试用该服务。 部署资源后,选择 “转到资源” 以检索 密钥 和 终结点。 需要资源密钥和终结点才能将应用程序连接到文档智能服务。 还可以在 Azure 门户中的 “密钥和终结点 ”页上找到这些值。
Azure Blob 存储帐户。 在 Azure Blob 存储帐户中为源文件和结果文件创建两个容器:
- 源容器:此容器用于上传文档文件进行分析。
- 结果容器:此容器是存储批处理分析 API 的结果的位置。
存储容器授权
若要允许 API 在 Azure 存储容器中处理文档和写入结果,必须使用以下两个选项之一进行授权:
✔️ 托管标识。 托管标识是一个服务主体,用于为 Azure 托管资源创建 Microsoft Entra 标识和特定权限。 托管标识使你无需在代码中嵌入凭据即可运行文档智能应用程序,这是一种更安全的方法,用于授予对存储数据的访问权限,而无需在代码中包含访问签名令牌(SAS)。
查看 文档智能的托管标识 ,了解如何为资源启用托管标识并向其授予对存储容器的访问权限。
重要
使用托管标识时,请勿在 HTTP 请求中包含 SAS 令牌 URL。 使用托管标识替代了包含共享访问签名令牌 (SAS) 的要求。
✔️ 共享访问签名 (SAS)。 共享访问签名是授予对存储容器的受限访问权限的 URL。 若要使用此方法,请为源容器和结果容器创建共享访问签名 (SAS) 令牌。 转到 Azure 门户中的存储容器,选择 “共享访问令牌” 以生成 SAS 令牌和 URL。
- 源容器或 Blob 必须指定读取、写入、列出和删除权限。
- 结果容器或 Blob 必须指定写入、列出、删除权限。
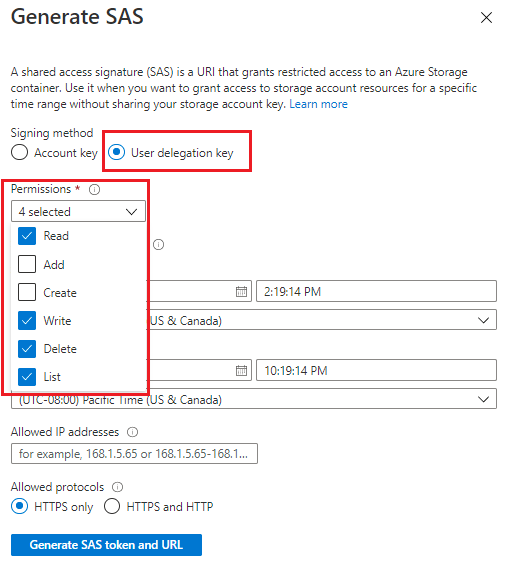
查看 “创建 SAS 令牌 ”,详细了解如何生成 SAS 令牌及其工作原理。
调用批处理分析 API
1.指定输入文件
批处理 API 支持两个选项,用于指定要处理的文件。
如果要处理容器或文件夹中的所有文件,并且文件数小于 10000 限制,请使用
azureBlobSource请求中的对象。POST {endpoint}/documentintelligence/documentModels/{modelId}:analyzeBatch?api-version=2024-11-30 { "azureBlobSource": { "containerUrl": "https://myStorageAccount.blob.core.chinacloudapi.cn/myContainer?mySasToken" }, { "resultContainerUrl": "https://myStorageAccount.blob.core.chinacloudapi.cn/myOutputContainer?mySasToken", "resultPrefix": "trainingDocsResult/" }如果不想处理容器或文件夹中的所有文件,而是该容器或文件夹中的特定文件,请使用该
azureBlobFileListSource对象。 此作需要文件列表 JSONL 文件,该文件列出要处理的文件。 将 JSONL 文件存储在容器的根文件夹中。 下面是列出两个文件的示例 JSONL 文件:{"file": "Adatum Corporation.pdf"} {"file": "Best For You Organics Company.pdf"}
使用以下条件的文件列表 JSONL 文件:
- 需要处理特定文件而不是容器中的所有文件时;
- 当输入容器或文件夹中的文件总数超过 10,000 个文件批处理限制时:
- 如果希望更好地控制每个批处理请求中处理的文件;
POST {endpoint}/documentintelligence/documentModels/{modelId}:analyzeBatch?api-version=2024-11-30
{
"azureBlobFileListSource": {
"containerUrl": "https://myStorageAccount.blob.core.chinacloudapi.cn/myContainer?mySasToken",
"fileList": "myFileList.jsonl"
...
},
...
}
这两个选项都需要容器 URL 或容器 SAS URL。 如果使用托管标识访问存储容器,请使用容器 URL。 如果使用共享访问签名(SAS),请使用 SAS URL。
2. 指定结果位置
指定希望使用
resultContainerURL参数存储结果的位置的 Azure Blob 存储容器 URL(或容器 SAS URL)。 建议将单独的容器用于源和结果,以防止意外覆盖。将
overwriteExisting布尔属性设置为False并阻止覆盖同一文档的任何现有结果。 如果要覆盖任何现有结果,请将布尔值设置为True。 即使未覆盖任何现有结果,仍会向你收取处理文档费用。用于
resultPrefix将结果分组并存储在特定的容器文件夹中。
3.生成并运行 POST 请求
请记住,将以下示例容器 URL 值替换为 Azure Blob 存储容器中的实际值。
此示例显示了具有输入的 azureBlobSource POST 请求
POST {endpoint}/documentintelligence/documentModels/{modelId}:analyzeBatch?api-version=2024-11-30
{
"azureBlobSource": {
"containerUrl": "https://myStorageAccount.blob.core.chinacloudapi.cn/myContainer?mySasToken",
"prefix": "inputDocs/"
},
{
"resultContainerUrl": "https://myStorageAccount.blob.core.chinacloudapi.cn/myOutputContainer?mySasToken",
"resultPrefix": "batchResults/",
"overwriteExisting": true
}
此示例显示 POST 请求和 azureBlobFileListSource 文件列表输入
POST {endpoint}/documentintelligence/documentModels/{modelId}:analyzeBatch?api-version=2024-11-30
{
"azureBlobFileListSource": {
"containerUrl": "https://myStorageAccount.blob.core.chinacloudapi.cn/myContainer?mySasToken",
"fileList": "myFileList.jsonl"
},
{
"resultContainerUrl": "https://myStorageAccount.blob.core.chinacloudapi.cn/myOutputContainer?mySasToken",
"resultPrefix": "batchResults/",
"overwriteExisting": true
}
下面是 成功 响应的示例
202 Accepted
Operation-Location: /documentintelligence/documentModels/{modelId}/analyzeBatchResults/{resultId}?api-version=2024-11-30
4.检索 API 结果
执行 POST作后,使用该 GET 作检索批处理分析结果。 GET作提取状态信息、批处理完成百分比以及作创建和更新日期/时间。 此信息仅在批处理分析完成后 保留 24 小时 。
GET {endpoint}/documentintelligence/documentModels/{modelId}/analyzeBatchResults/{resultId}?api-version=2024-11-30
200 OK
{
"status": "running", // notStarted, running, completed, failed
"percentCompleted": 67, // Estimated based on the number of processed documents
"createdDateTime": "2021-09-24T13:00:46Z",
"lastUpdatedDateTime": "2021-09-24T13:00:49Z"
...
}
5. 解释状态消息
对于处理的每个文档,都会分配状态,即succeeded、failed、running或notStartedskipped。 提供了源 URL,该 URL 是输入文档的源 Blob 存储容器。
状态
notStarted或running。 批处理分析操作未启动或未完成。 等待所有文档的操作完成。状态
completed。 批处理分析操作已完成。状态
succeeded。 批处理作成功,并处理了输入文档。 可通过组合、resultUrl扩展和resultContainerUrl扩展创建结果resultPrefix。input filename.ocr.json只有成功的文件具有该属性resultUrl。succeeded状态响应的示例:{ "resultId": "myresultId-", "status": "succeeded", "percentCompleted": 100, "createdDateTime": "2025-01-01T00:00:000", "lastUpdatedDateTime": "2025-01-01T00:00:000", "result": { "succeededCount": 10,000, "failedCount": 0, "skippedCount": 0, "details": [ { "sourceUrl": "https://{your-source-container}/inputFolder/document1.pdf", "resultUrl": "https://{your-result-container}/resultsFolder/document1.pdf.ocr.json", "status": "succeeded" }, ... { "sourceUrl": "https://{your-source-container}/inputFolder/document10000.pdf", "resultUrl": "https://{your-result-container}/resultsFolder/document10000.pdf.ocr.json", "status": "succeeded" } ] } }状态
failed。 仅当整个批处理请求中出现错误时,才会返回此错误。 批处理分析作启动后,单个文档作状态不会影响整个批处理作业的状态,即使所有文件都具有状态failed。failed状态响应的示例:[ "result": { "succeededCount": 0, "failedCount": 2, "skippedCount": 0, "details": [ "sourceUrl": "https://{your-source-container}/inputFolder/document1.jpg", "status": "failed", "error": { "code": "InvalidArgument", "message": "Invalid argument.", "innererror": { "code": "InvalidSasToken", "message": "The shared access signature (SAS) is invalid: {details}" } } ] } ] ...状态
skipped:通常,当文档的输出已存在于指定的输出文件夹中并且overwriteExisting布尔属性设置为false时,会出现此状态。skipped状态响应的示例:[ "result": { "succeededCount": 3, "failedCount": 0, "skippedCount": 2, "details": [ ... "sourceUrl": "https://{your-source-container}/inputFolder/document1.pdf", "status": "skipped", "error": { "code": "OutputExists", "message": "Analysis skipped because result file https://{your-result-container}/resultsFolder/document1.pdf.ocr.json already exists." } ] } ] ...注释
在完成整个批处理的分析之前,不会为单个文件返回分析结果。 若要跟踪超出
percentCompleted详细进度,可以在文件写入*.ocr.json文件时监视resultContainerUrl文件。