Azure 语音通过 Azure 语音资源提供语音转文本、文本转语音和其他功能。 你可以将语音转录为准确度较高的文本、生成自然语音转语音、翻译语音和进行实时 AI 语音对话。

在云中或容器边缘的任意位置运行 Azure 语音。 使用 语音 CLI、语音 SDK 和 REST API 为您的应用程序、工具和设备启用语音功能。
Azure 语音提供多种语言服务,覆盖多个区域,并支持不同的价位。
场景
常见的语音场景包括:
- 字幕:了解如何将字幕与输入音频同步、应用亵渎内容过滤器、获得部分结果、应用自定义以及识别多语言场景的口语。
- 音频内容创建:使用神经语音使与聊天机器人和语音代理的交互更加自然和引人入胜,将电子书等数字文本转换为音频手册,以及增强汽车内导航系统。
- 呼叫中心:实时转录呼叫或处理一批呼叫、编辑个人信息,并提取见解(如情绪),以帮助处理呼叫中心用例。
- 语言学习:向语言学习者提供发音评估反馈,支持远程学习对话的实时听录,并使用神经语音大声朗读教材。
- 语音直播:为应用程序和体验创建自然而人性化的对话界面。 语音直播功能在人与代理实现之间提供快速、可靠的交互。
Microsoft将 Azure 语音用于许多方案,例如Microsoft Teams 中的字幕、Microsoft Office 365 中的听写,以及在 Microsoft Edge 浏览器中大声朗读。
Capabilities
以下部分总结了 Azure 语音功能,并提供详细信息的链接。
语音转文本
使用 语音转文本 将音频转换为文本。 从以下项中进行选择:
如果音频包含环境噪音或包括行业和特定于域的行话,则基本模型可能不够。 在这些情况下,可以使用声学、语言和发音数据创建和训练自定义语音识别模型。 自定义语音识别模型是专用的,具有竞争优势。
文本转语音
使用 文本转语音,可以将输入文本转换为类似人工合成的语音。 使用由深度神经网络驱动的类人语音。 使用 语音合成标记语言(SSML) 微调音调、发音、说话速率、音量等。
语音选项包括:
- 标准语音:可以在非常自然的开箱即用语音中进行选择。 检查 语音库中 的标准语音示例,并确定适合业务需求的语音。
语音翻译
使用语音翻译可在应用程序、工具和设备中实现实时的多语言语音翻译。 使用此功能进行语音转语音和语音转文本翻译。
语言识别
语言识别 通过将语言与 支持的语言列表进行比较,帮助识别音频中口语的语言。 单独使用语言识别、语音转文本识别或语音翻译。
发音评估
发音评估可以评估语音发音,并为说话人提供有关讲话音频准确度和流利度的反馈。 通过使用发音评估,语言学习者可以练习、获取即时反馈并改进发音,以便他们可以自信地说话和呈现。
交付和存在
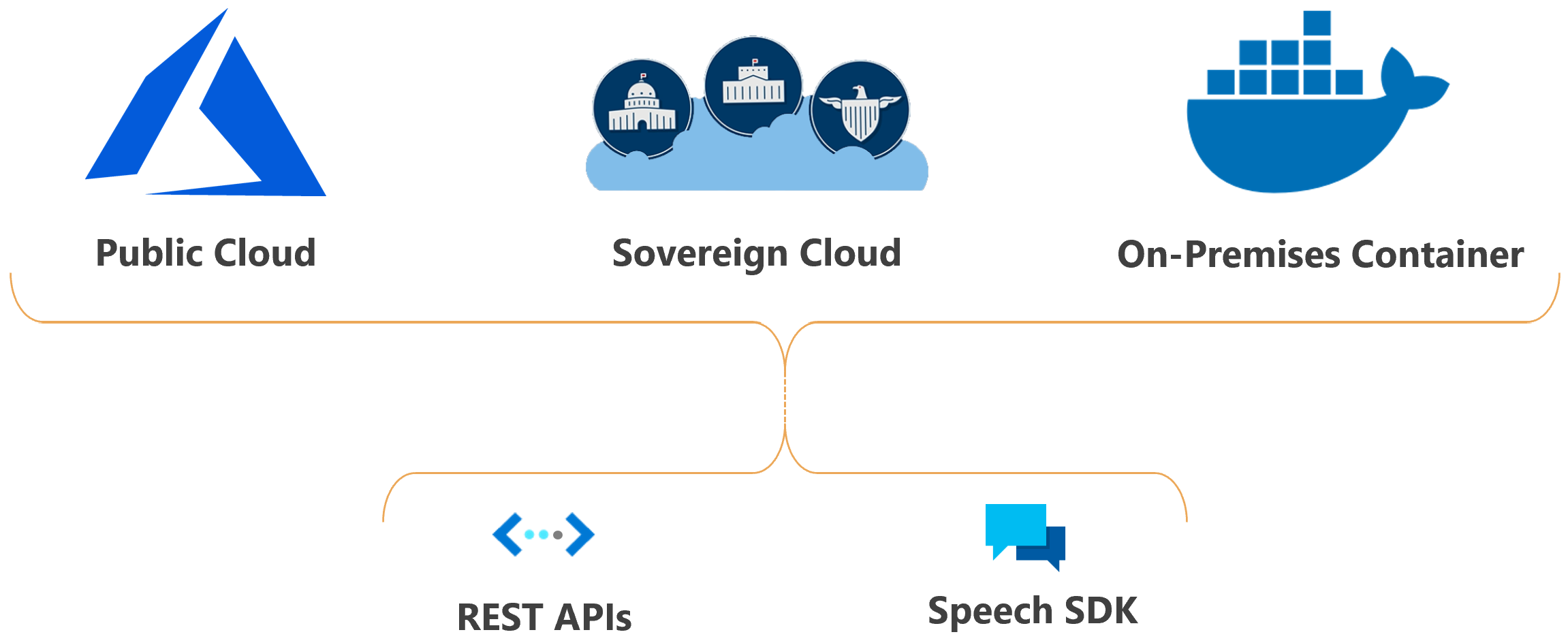
可以在云中部署 Azure 语音功能。
主权云中的 Azure 语音部署适用于某些政府实体及其合作伙伴。 例如,由世纪互联运营的 Microsoft Azure 可供在中国有业务存在的组织使用。 有关详细信息,请参阅 主权云中的语音服务。
在应用程序中集成 Azure 语音
Speech Studio 是一组基于 UI 的工具,用于在应用程序中生成和集成 Azure Speech 中的功能。 使用无代码方法在 Speech Studio 中创建项目。 然后,可以使用以下方法在应用程序中引用这些资产:
语音 SDK。 此 SDK 公开了许多可用于开发支持语音的应用程序的 Azure 语音功能。 语音 SDK 可以在许多编程语言中和所有平台中使用。
语音命令行界面 (CLI)。 使用此命令行工具,无需编写任何代码即可使用 Azure 语音。 语音 SDK 中的大部分功能都可在语音 CLI 中使用,一些高级功能和自定义设置在语音 CLI 中进行了简化。
REST API。 在某些情况下,不能或不应使用语音 SDK。 在这些情况下,可以使用 REST API 访问 Azure 语音。 例如,使用 REST API 进行批量听录。
代码示例
GitHub 上提供了 Azure 语音的示例代码。 这些示例涵盖了常见方案,例如,从文件或流中读取音频、连续和单次识别,以及使用自定义模型。 使用以下链接查看 SDK 和 REST 示例:
相关内容
以下快速入门适用于 Azure 语音功能。 每个快速入门介绍了许多常用编程语言中的基本设计模式,并在不到 10 分钟内运行代码。