本文概述了在Azure Kubernetes 服务 (AKS)上运行和迁移有状态工作负荷:数据库和有状态服务的设计模式、存储选项和迁移渐变。
什么是有状态工作负载?
有状态工作负载是一种应用程序,它使用持久数据存储在多个实例之间保持状态,从而确保无缝且个性化的用户体验。 这种设计对于在线银行、在线购物和电子邮件等服务至关重要,因为这些服务需要保证数据一致性、会话历史记录和可靠性。 有状态工作负载还可以在高性能和准实时处理场景中提高效率,这些场景受益于故障转移和恢复等高级功能,确保业务连续性。
虽然有状态工作负载提供了许多好处,但它们也存在一些挑战。 例如,有状态工作负载通常会引入复杂的处理模式,这可能会导致开销和性能成本增加。 请务必了解并考虑应用程序的特定需求,以帮助确定有状态与无状态之间的适当平衡。
鉴于有状态工作负载的关键作用,Azure 提供了多种有效的运行方法。 本部分概述了在 Azure Kubernetes 服务 (AKS) 上部署有状态工作负载的最佳做法,帮助开发人员和组织选择最适合自己需求的选项。
Kubernetes 有状态框架基础堆栈
Kubernetes 有状态框架始于一个通用基础栈。 在这种情况下,请使用 KATE 堆栈,这是用于许多基础结构项目的常用标准化堆栈。 KATE 堆栈使用以下开放源代码工具:
AKS 指南并未采用 ArgoCD 或 Terraform,因为这些指南是为 Day 1 运维而设计的。 不过,随着部署规模的扩大和需求的变化,将更容易集成 ArgoCD 和 Terraform,因为这些指南使用了部分 KATE 堆栈。
适用于 Azure 的 Kubernetes 有状态框架
建立基础堆栈后,我们现在需要增强框架,以支持 Azure 上的有状态工作负载,特别是通过集成在 Azure Kubernetes 服务 (AKS) 上运行数据基础结构所需的基本资源。
支持复杂的有状态工作负载(如数据库或消息队列)需要比临时选项更高的存储能力。 具体而言,你需要提供增强复原能力和可用性的系统来解决各种事件,例如应用程序故障或工作负荷重新分配给不同的主机。 可以使用 PersistentVolume 子系统来实现此复原能力,该子系统包含三个互连的 Kubernetes 资源:PersistentVolumes、PersistentVolumeClaims 和 StorageClasses。 该子系统提供了一个 API,供用户和管理员从存储的使用方式中提取出提供存储的方式的详细信息。
大多数有状态工作负载都需要机密中的数据,例如连接字符串、用户名、密码和证书。 Azure 密钥保管库 提供了一个安全的机密存储,可用于保存必要的有状态框架机密。
我们还需要一个 Kubernetes 控制器或 Kubernetes 操作员,例如机密存储 CSI 驱动程序或 External Secrets Operator,以将机密存储库中的机密同步为 Kubernetes 机密。
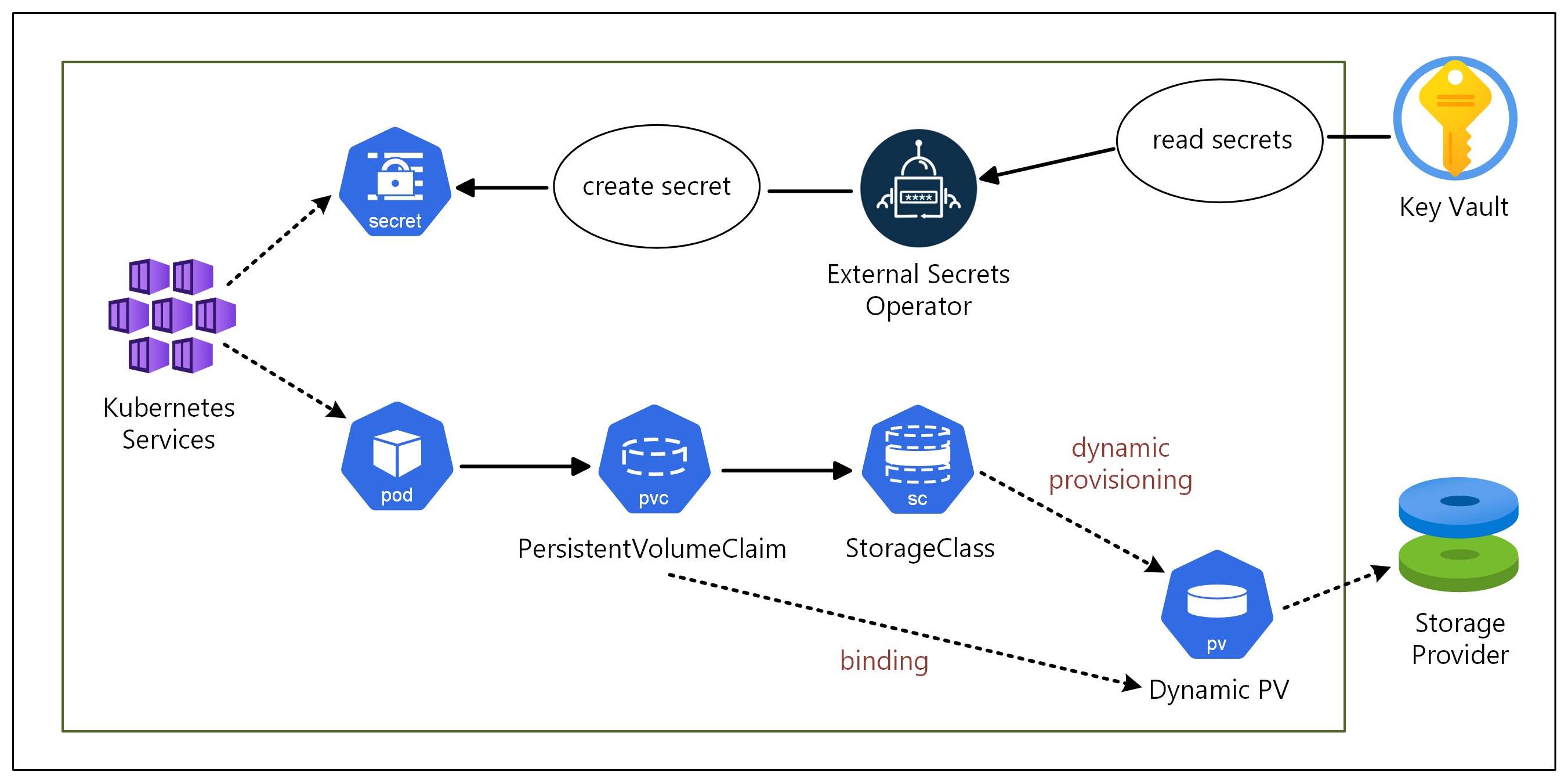
在 Azure 上设计和部署有状态工作负载
如果你要将现有的有状态工作负载迁移到 AKS,请先参阅 将有状态工作负载迁移到 AKS 入门指南,以查看迁移专属的评估和验证步骤。
以下部分提供了有关在 Azure 上设计和部署有状态工作负载场景信息的链接。
MongoDB
- MongoDB 有状态工作负载设计概述
- 创建用于在 Azure Kubernetes 服务 (AKS) 上运行 MongoDB 群集的基础结构
- 在 Azure Kubernetes 服务 (AKS) 上配置和部署 MongoDB 群集
- 部署客户端应用程序以连接到 Azure Kubernetes 服务 (AKS) 上的 MongoDB 群集
- 验证 Azure Kubernetes 服务 (AKS) 上的 MongoDB 群集的复原能力
- 在 Azure Kubernetes 服务 (AKS) 节点池升级期间验证 MongoDB 复原能力
- 为 Azure Kubernetes 服务 (AKS) 上的 MongoDB 群集设置监视
PostgreSQL
- PostgreSQL 有状态工作负载设计概述
- 创建用于在 Azure Kubernetes 服务 (AKS) 上运行高可用性 PostgreSQL 数据库的基础结构
- 在 Azure Kubernetes 服务 (AKS) 上部署高度可用的 PostgreSQL 数据库
Valkey
- Valkey 有状态工作负载设计概述
- 创建用于在 Azure Kubernetes 服务 (AKS) 上运行 Valkey 群集的基础结构
- 在 Azure Kubernetes 服务 (AKS) 上配置和部署 Valkey 群集
- 验证 Azure Kubernetes 服务 (AKS) 上的 Valkey 群集的复原能力
- 在 Azure Kubernetes 服务 (AKS) 节点池升级期间验证 Valkey 复原能力
Apache Airflow
- Apache Airflow 有状态工作负载设计概述
- 创建用于在 Azure Kubernetes 服务 (AKS) 上运行 Apache Airflow 的基础结构
- 在 Azure Kubernetes 服务 (AKS) 上配置和部署 Airflow
Apache Kafka 与 Strimzi
- 使用 Strimzi 概述在 Azure Kubernetes 服务(AKS)上部署 Kafka 群集
- 准备用于在 Azure Kubernetes 服务(AKS)上部署 Kafka 的基础结构
- 在 Azure Kubernetes 服务(AKS)上配置和部署 Strimzi 和 Kafka 组件
- 在 Azure Kubernetes 服务(AKS)上为 Kafka 群集配置监视和网络
将 GitHub Actions 与 Azure 文件配合使用
- 有关在 Azure Kubernetes 服务(AKS)上部署高度可用的 GitHub Actions 的解决方案概述
- 创建用于在 Azure Kubernetes 服务(AKS)上部署高度可用的 GitHub Actions 的基础结构
- 在 Azure Kubernetes 服务(AKS)上部署和测试 GitHub Actions
注释
尽管 StatefulSets 提供持久标识和存储,但不建议将 Azure Spot 节点池用于生产关键型有状态工作负荷。 当 Azure 回收容量时,Spot VM 可能会在几乎没有提前通知的情况下被逐出,从而导致节点突然终止,并可能造成卷恢复或 Pod 重新调度延迟。 对于依赖于持久性数据和高可用性的工作负荷,请使用常规节点池和适当的存储复原机制。 Azure Spot 节点池应保留给可中断且可以容忍意外节点丢失的工作负载。
供稿人
Microsoft 会维护本文。 以下贡献者最初撰写了本文:
- Don High | 首席客户工程师
- Colin Mixon | 产品经理
- Erin Schaffer | 内容开发人员 2