适用于:Azure Stack HCI 版本 22H2 和 21H2;Windows Server 2022、Windows Server 2019
本文提供有关使用 Windows Admin Center 连接到 Azure Stack HCI 群集以及监视群集和存储性能的说明。
Windows Admin Center 是一个本地部署的基于浏览器的应用,用于管理 Azure Stack HCI。 若要安装 Windows Admin Center,最简单的方法是在本地管理 PC 上安装(桌面模式),但也可以在服务器上安装(服务模式)。
备注
要进行 Azure AD 身份验证,请在服务器上安装 Windows Admin Center。
如果在服务器上安装 Windows Admin Center,则那些需要 CredSSP 的任务(例如创建群集以及安装更新和扩展)使用的帐户必须是 Windows Admin Center 服务器上的“网关管理员”组的成员。 有关详细信息,请参阅配置用户访问控制和权限的前两个部分。
完成 Windows Admin Center 的安装之后,可以从“概述”主页添加要管理的群集。
在“所有连接”下,选择“+ 添加”。

在“服务器群集”下,选择“添加”以添加 Azure Stack HCI 群集:
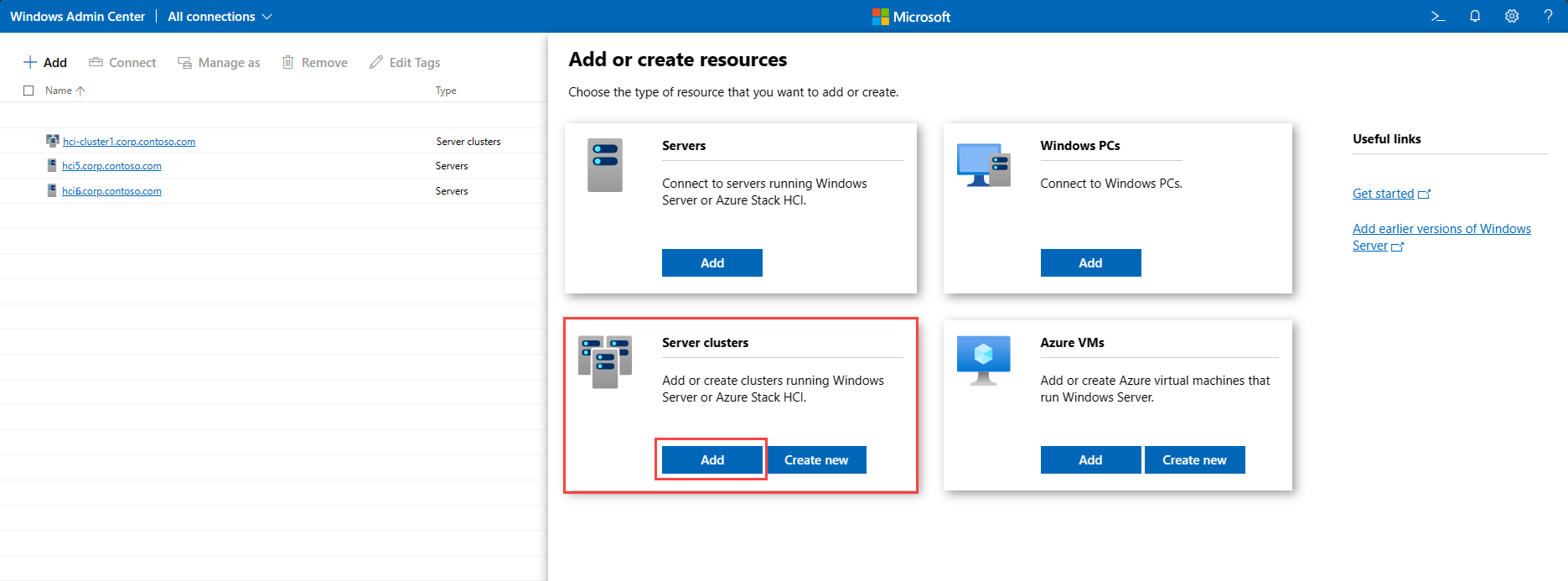
键入要管理的群集名称,然后选择“添加”。 群集将添加到“概述”页上的“连接”列表中。
在“所有连接”下,选择刚添加的群集的名称。 Windows Admin Center 将启动“群集管理器”,并直接转到该群集的 Windows Admin Center 仪表板。


Windows Admin Center 仪表板提供有关服务器、驱动器和卷的警报和运行状况信息,以及有关 CPU、内存和存储使用情况的详细信息。 登录后,Windows Admin Center 仪表板顶部会立即突出显示关键警报。 仪表板底部按小时、日、周、月或年显示群集性能信息,如每秒的读写次数 (IOPS) 和延迟。

了解运行应用程序和数据库的虚拟机 (VM) 的运行状况非常重要。 如果没有为 VM 上运行的工作负载分配足够的 CPU 或内存,性能可能会降低,或者应用程序可能会变得不可用。 如果 VM 在 5 分钟或更长时间内响应的检测信号少于三个,则可能存在问题。
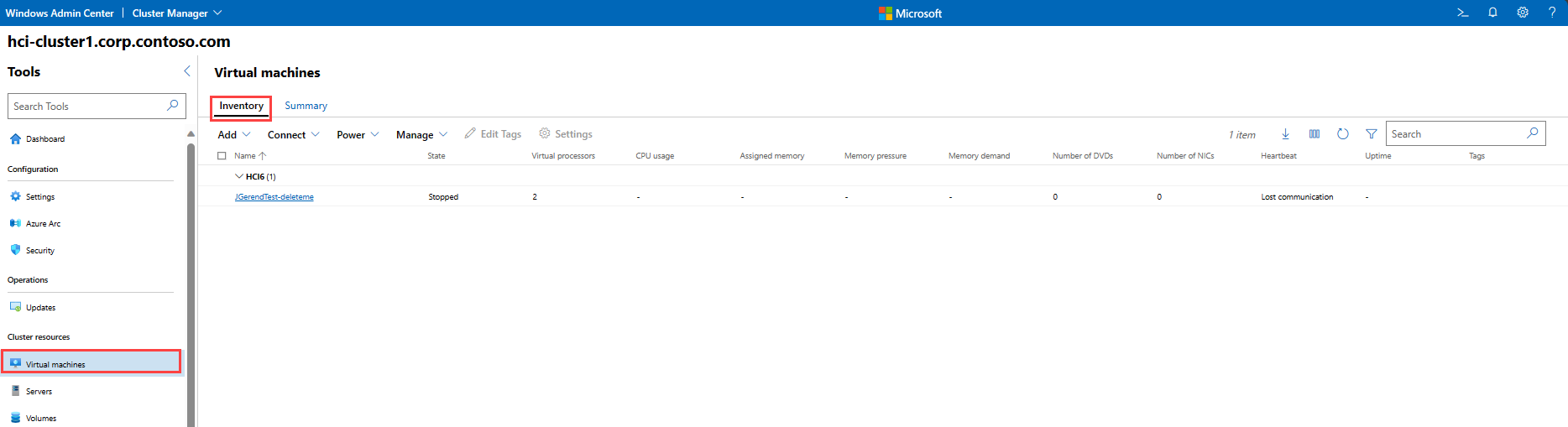
要在 Windows Admin Center 中监视 VM,请从左侧的“工具”菜单中选择“虚拟机”。

要查看群集上运行的 VM 的完整清单,请选择页面顶部的“清单”。 你将看到一个表,其中包含每个 VM 的相关信息,包括:
名称: VM 的名称。
状态: 指示 VM 是在运行还是已停止。
主机服务器: 指示 VM 在群集中的哪个服务器上运行。
CPU 使用率: VM 使用的资源占群集总 CPU 资源量的百分比。
内存压力: VM 使用的资源占可用内存资源的百分比。
内存需求: VM 使用的分配的内存量(GB 或 MB)。
分配的内存: 分配给 VM 的内存总量。
运行时间: VM 已运行多长时间(以“天:小时:分钟:秒”表示)。
检测信号: 指示群集是否可以与 VM 通信。
灾难恢复状态: 显示 VM 是否已登录 Azure Site Recovery。

可以直接通过 Windows Admin Center 监视构成 Azure Stack HCI 群集的主机服务器。 如果没有为主机服务器配置足够的 CPU 或内存来提供 VM 所需的资源,它们可能会导致性能瓶颈。
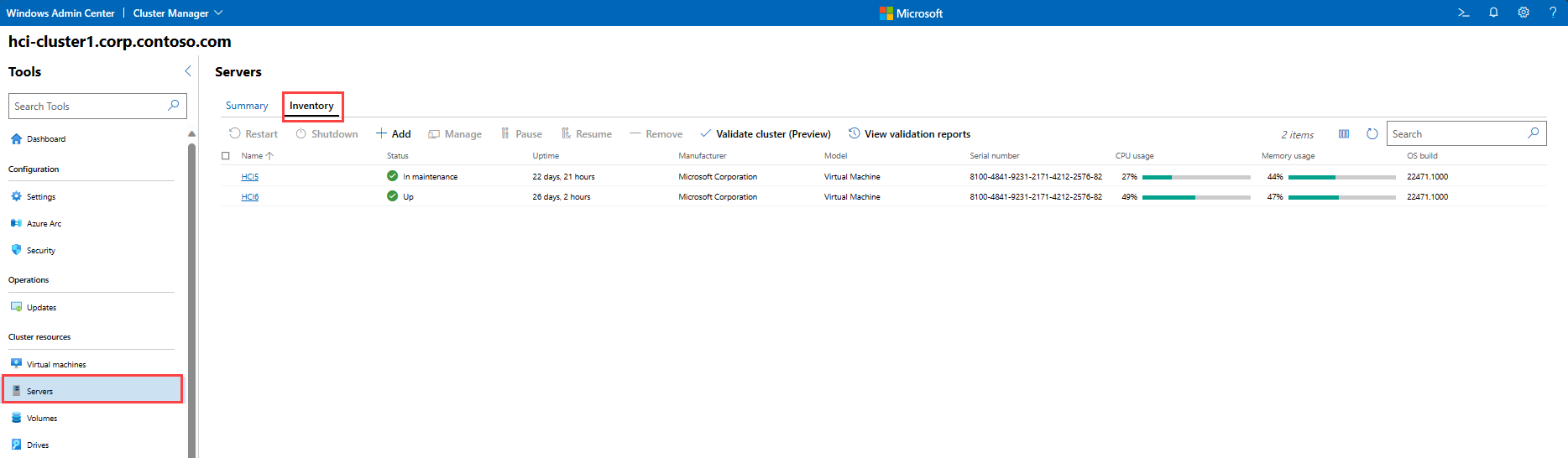
要在 Windows Admin Center 中监视服务器,请从左侧的“工具”菜单中选择“服务器”。

要查看群集中服务器的完整清单,请选择页面顶部的“清单”。 你将看到一个表,其中包含每个服务器的相关信息,包括:
名称: 群集中的主机服务器的名称。
状态: 指示服务器是启动还是关闭状态。
运行时间: 服务器已启动多长时间。
制造商: 服务器的硬件制造商。
型号: 服务器的型号。
序列号: 服务器的序列号。
CPU 使用率: 正在使用的主机服务器 CPU 占比。 群集中任何服务器使用超过 85% 的 CPU 的时间都不应长于 10 分钟。
内存使用率: 正在使用的主机服务器内存占比。 如果服务器可用内存小于 100MB 的时间达 10 分钟或更长时间,请考虑增加内存。

存储卷的填充速度可能会很快,因此应定期监视它们以避免对应用程序造成任何影响,这非常重要。
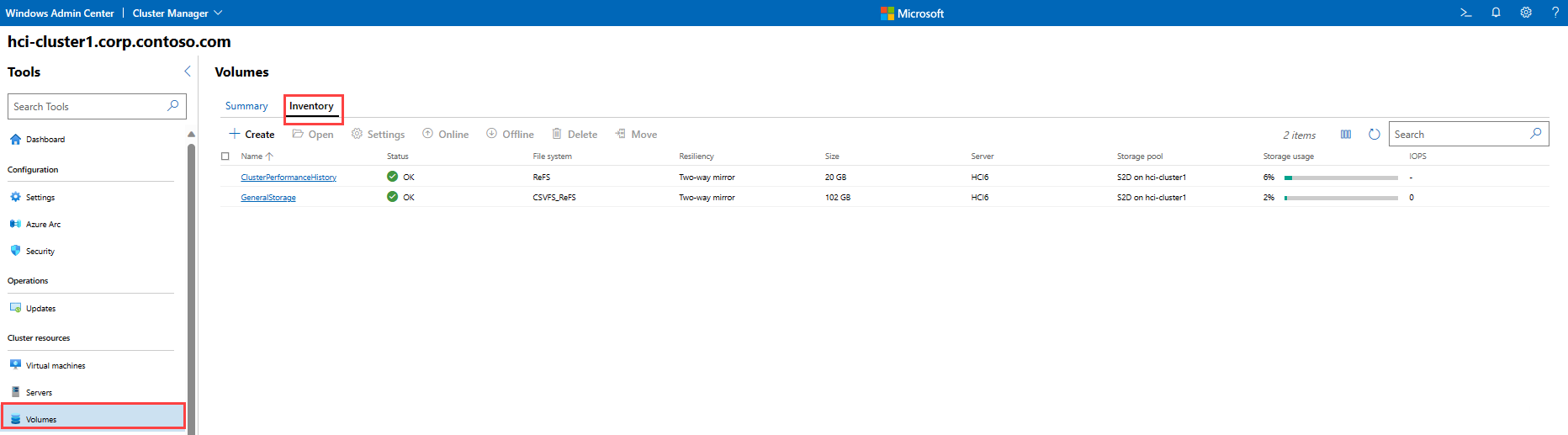
要在 Windows Admin Center 中监视卷,请从左侧的“工具”菜单中选择“卷”。

要查看群集上存储卷的完整清单,请选择页面顶部的“清单”。 你将看到一个表,其中包含每个卷的相关信息,包括:
名称: 卷的名称。
状态: “OK”表示卷正常;否则,将显示警告或错误。
文件系统: 卷(ReFS 和 CSVFS)上的文件系统。
复原能力: 指示卷是双向镜像、三向镜像还是镜像加速奇偶校验。
Size: 卷的大小 (TB/GB)
存储池: 卷所属的存储池。
存储使用率: 已使用的卷存储容量占比。
IOPS: 每秒输入/输出操作数。

Azure Stack HCI 的存储虚拟化方式使得丢失一个单独的驱动器不会对集群造成重大影响。 但是,需要替换故障驱动器,并且驱动器有可能因填充或引入延迟而影响性能。 如果操作系统无法与驱动器通信,则驱动器可能会变得松散或断开连接,其连接器可能出现故障或驱动器本身可能出现故障。 在通信中断 15 分钟后,Windows 将自动停用驱动器。
要在 Windows Admin Center 中监视驱动器,请从左侧的“工具”菜单中选择“驱动器”。

要查看群集上驱动器的完整清单,请选择页面顶部的“清单”。 你将看到一个表,其中包含每个驱动器的相关信息,包括:
序列号: 驱动器的序列号。
状态: “OK”表示驱动器正常;否则,将显示警告或错误。
型号: 驱动器的型号。
Size: 驱动器的总容量 (TB/GB)。
类型: 驱动器类型(SSD、HDD)。
用途: 指示驱动器是用于缓存还是容量。
位置: 驱动器连接到的存储适配器和端口。
服务器: 驱动器连接到的服务器的名称。
存储池: 驱动器所属的存储池。
存储使用率: 已使用的驱动器存储容量占比。


要查看群集中虚拟交换机的设置,请从左侧的“工具”菜单中选择“虚拟交换机”,然后选择要显示其设置的虚拟交换机的名称。 Windows Admin Center 将显示与虚拟交换机关联的网络适配器,包括其 IP 地址、连接状态、链接速度和 MAC 地址。

使用 Windows Admin Center 中的性能监视器工具可实时查看和比较 Windows、应用或设备的性能计数器。
从左侧的“工具”菜单中选择“性能监视器”。
选择“空白工作区”以启动新工作区,或选择“还原以前的工作区以还原以前的工作区。

如果正在新建工作区,请选择“添加计数器”按钮,然后选择一个或多个要监视的源服务器,或者选择整个群集。
选择要监视的对象和实例以及计数器和图形类型,以查看动态性能信息。
选择顶部菜单中的“保存”>“另存为”,保存工作区。

例如,下面的屏幕截图显示了名为“内存使用率”的性能计数器,它显示了跨二节点群集的内存的相关信息。
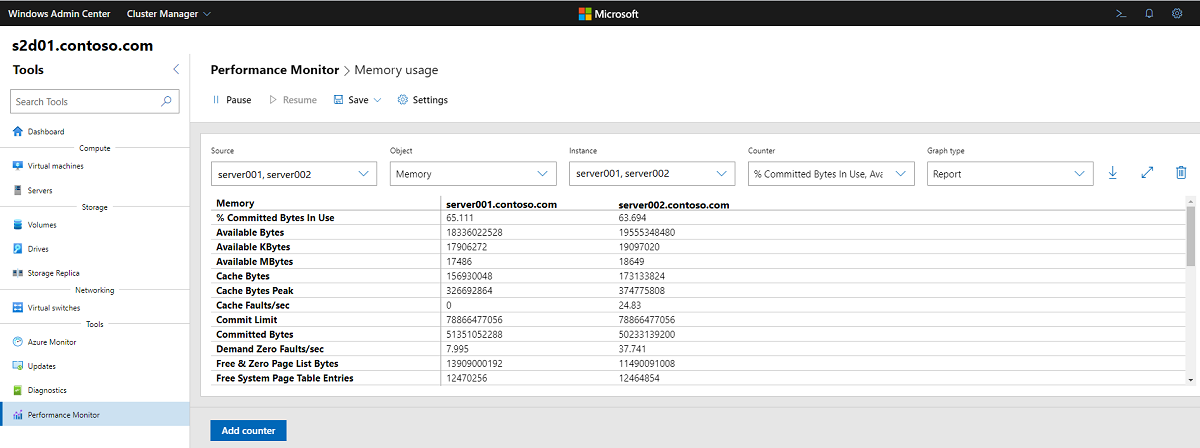 -->
-->
还可以使用 PowerShell cmdlet 监视 Azure Stack HCI 群集,这些 cmdlet 返回有关群集及其组件的信息。 请参阅存储空间直通的性能历史记录。
应调查群集上的任何运行状况服务错误。 请参阅 Windows Server 中的运行状况服务,了解如何运行报告和确定故障。
若要了解存储池、虚拟磁盘和驱动器的运行状况和操作状态,请参阅对存储空间和存储空间直通运行状况和操作状态进行故障排除。
存储服务质量 (QoS) 提供了一种集中监视和管理 VM 的存储 I/O 的方法,以减少邻近干扰问题并提供一致的性能。 请参阅存储服务质量。
可以从 Azure 门户监视 Azure Stack HCI 群集,并使用 Azure Stack HCI Insights 监视群集运行状况、性能和使用情况。
如需相关信息,另请参阅: