使用 Azure Batch 在 Azure 中高效运行大规模并行和高性能计算 (HPC) 批处理作业。 本教程通过一个 Python 示例演示了如何使用 Batch 运行并行工作负荷。 你可以学习常用的 Batch 应用程序工作流,以及如何以编程方式与 Batch 和存储资源交互。
- 通过 Batch 和存储帐户进行身份验证。
- 将输入文件上传到存储。
- 创建运行应用程序所需的计算节点池。
- 创建用于处理输入文件的作业和任务。
- 监视任务执行情况。
- 检索输出文件。
在本教程中,你会使用 ffmpeg 开放源代码工具将 MP4 媒体文件并行转换为 MP3 格式。
如果没有 Azure 帐户,请在开始前创建一个试用帐户。
先决条件
授权访问你的批处理和存储账户
本教程展示了如何通过使用 Microsoft Entra ID 搭配 DefaultAzureCredential 认证 Azure Batch 和 Azure 存储。 这个应用不使用账户密钥。 在运行应用之前,确保你使用的身份在两个账户上都具备所需的角色。
通过使用 Azure CLI 登录。
DefaultAzureCredential会自动检测到此登录信息:az login为你的用户帐户分配一个允许对 Batch 帐户执行数据平面操作的角色,例如 Azure Batch Data Contributor。 该角色需要创建池、作业和任务。 您可以在 Azure 门户中 Batch 帐户的 访问控制(IAM) 页上分配该角色,或使用 Azure CLI:
az role assignment create \ --assignee "<your-user-principal-name>" \ --role "Azure Batch Data Contributor" \ --scope "/subscriptions/<subscription-id>/resourceGroups/<resource-group>/providers/Microsoft.Batch/batchAccounts/<batch-account-name>"在存储账户上为用户账户指定为 存储块数据贡献 者角色。 该角色需要创建容器、上传输入文件,并请求签署任务所用共享访问签名(SAS)URL 的用户委派密钥:
az role assignment create \ --assignee "<your-user-principal-name>" \ --role "Storage Blob Data Contributor" \ --scope "/subscriptions/<subscription-id>/resourceGroups/<resource-group>/providers/Microsoft.Storage/storageAccounts/<storage-account-name>"请注意以下数值,这些值会添加到下一节采样的 config.py 文件中。 你可以在Azure门户的每个账户的概览页面找到它们:
- 批量帐户名称
- 比如批量账户的URL。
https://mybatchaccount.chinanorth3.batch.chinacloudapi.cn - 存储帐户名称
注释
角色分配可能需要几分钟才能生效。 如果应用在分配角色后立即出现授权错误,请等待几分钟再试一次。
下载并运行示例应用
Important
batch-python-ffmpeg-tutorial 仓库中的可下载示例正在更新以匹配本教程。 在该更新发布之前,仓库可能仍包含早期基于密钥的认证和Ubuntu 20.04代码。 本文中的代码是事实的来源。 如果下载的样本与这里的片段不符,请按照本文所示的代码操作。
下载示例应用
从 GitHub 下载或克隆示例应用。 若要使用 Git 客户端克隆示例应用存储库,请使用以下命令:
git clone https://github.com/Azure-Samples/batch-python-ffmpeg-tutorial.git
导航到包含文件 batch_python_tutorial_ffmpeg.py 的目录。
在 Python 环境中使用 pip 安装所需的包。
pip install -r requirements.txt
使用代码编辑器打开文件 config.py。 将 Batch 和存储帐户的值更新为你的帐户所特有的名称。 此示例使用 DefaultAzureCredential 进行身份验证,因此不再需要帐户密钥。 例如:
_BATCH_ACCOUNT_NAME = 'yourbatchaccount'
_BATCH_ACCOUNT_URL = 'https://yourbatchaccount.yourbatchregion.batch.chinacloudapi.cn'
_STORAGE_ACCOUNT_NAME = 'mystorageaccount'
确保你已使用 az login 登录,并且你的身份具有 授予对 Batch 和存储帐户的访问权限中所述的角色。
DefaultAzureCredential还可以发现其他凭证来源,如管理身份、Visual Studio Code 或环境变量。
运行应用
若要运行该脚本,请执行以下操作:
python batch_python_tutorial_ffmpeg.py
运行示例应用程序时,控制台输出如下所示。 在执行过程中,当池中的计算节点启动时,会在 Monitoring all tasks for 'Completed' state, timeout in 00:30:00... 处暂停一下。
Sample start: 11/28/2018 3:20:21 PM
Container [input] created.
Container [output] created.
Uploading file LowPriVMs-1.mp4 to container [input]...
Uploading file LowPriVMs-2.mp4 to container [input]...
Uploading file LowPriVMs-3.mp4 to container [input]...
Uploading file LowPriVMs-4.mp4 to container [input]...
Uploading file LowPriVMs-5.mp4 to container [input]...
Creating pool [LinuxFFmpegPool]...
Creating job [LinuxFFmpegJob]...
Adding 5 tasks to job [LinuxFFmpegJob]...
Monitoring all tasks for 'Completed' state, timeout in 00:30:00...
Success! All tasks reached the 'Completed' state within the specified timeout period.
Deleting container [input]....
Sample end: 11/28/2018 3:29:36 PM
Elapsed time: 00:09:14.3418742
转到 Azure 门户中的 Batch 帐户,监视池、计算节点、作业和任务。 例如,若要查看池中计算节点的热度地图,请选择“池”>“LinuxFFmpegPool”。
任务正在运行时,热度地图如下所示:
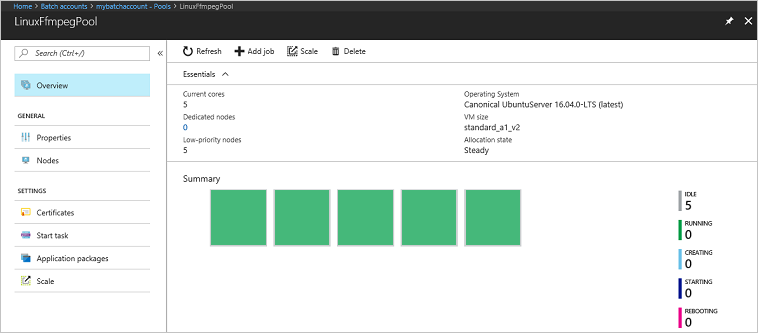
以默认配置运行应用程序时,典型的执行时间大约为 5 分钟。 池创建过程需要最多时间。
检索输出文件
可以使用 Azure 门户下载 ffmpeg 任务生成的输出 MP3 文件。
- 单击“所有服务”>“存储帐户”,然后单击存储帐户的名称。
- 单击“Blobs”>“output”。
- 右键单击一个输出 MP3 文件,然后单击“下载”。 在浏览器中按提示打开或保存该文件。
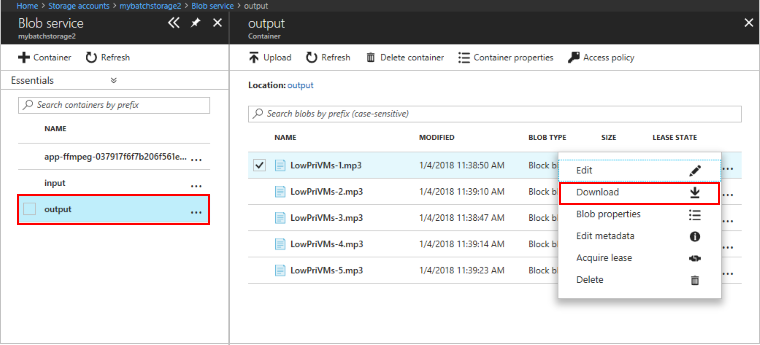
也可以编程方式从计算节点或存储容器下载这些文件(但在本示例中未演示)。
查看代码
以下部分将示例应用程序细分为多个执行步骤,用于处理 Batch 服务中的工作负荷。 在阅读本文的其余内容时,请参阅 Python 代码,因为我们并没有讨论示例中的每行代码。
对 Blob 和 Batch 客户端进行身份验证
此示例使用 Azure 标识包中的 DefaultAzureCredential 对存储和 Batch 进行身份验证。
DefaultAzureCredential按顺序尝试多种凭据类型(环境变量、托管标识、Azure CLI登录等),这使得相同的代码在本地开发和生产环境中运行,而无需存储帐户密钥。
为了与存储帐户交互,应用使用 azure-storage-blob 包创建使用凭据的 BlobServiceClient 对象。
示例导入以下身份和存储类型,并读取账户名称 config.py:
import config
from azure.identity import DefaultAzureCredential
from azure.storage.blob import (
BlobServiceClient,
BlobSasPermissions,
ContainerSasPermissions,
generate_blob_sas,
generate_container_sas,
)
credential = DefaultAzureCredential()
blob_service_client = BlobServiceClient(
account_url=f"https://{config._STORAGE_ACCOUNT_NAME}.blob.core.chinacloudapi.cn/",
credential=credential)
该应用创建一个 BatchClient 对象,用于在 Batch 服务中创建和管理池、作业和任务。 Batch 客户端使用相同的 DefaultAzureCredential 通过 Microsoft Entra ID 进行身份验证。
batch_client = BatchClient(
endpoint=config._BATCH_ACCOUNT_URL,
credential=credential)
批处理计算节点通过共享访问签名(SAS)URL访问输入和输出容器。 因为应用不使用存储账户密钥,所以无法用它签名SAS令牌。 相反,应用向 Blob 服务请求用户委托密钥,该密钥以应用的 Microsoft Entra 凭证签名,并用该密钥生成 SAS 令牌。 有关详细信息,请参阅创建用户委托 SAS。
start = datetime.datetime.now(datetime.timezone.utc)
expiry = start + datetime.timedelta(hours=4)
user_delegation_key = blob_service_client.get_user_delegation_key(
key_start_time=start, key_expiry_time=expiry)
# Sign the SAS tokens with the same expiry as the user delegation key.
sas_expiry = expiry
注释
本样本中的用户委派密钥有效期为四小时。 使用用户委派密钥签名的 SAS 令牌,其有效期不能超过该密钥的有效期,而用户委派密钥的最长有效期为 7 天。 对于长时间运行的工作负载,请申请新的密钥,并在 SAS URL 过期前重新生成 SAS URL。
上传输入文件
在创建输入 blob_service_client和输出容器后,应用会将 InputFiles 文件夹中的每个本地 MP4 文件上传到输入容器。 以下 upload_file_to_container 辅助工具上传单个文件,生成一个只读的 SAS 令牌,并用用户委派键签名,并返回一个 Batch ResourceFile 对象,其 URL 包含 SAS 令牌,以便 Batch 之后将该文件下载到计算节点。 应用对每个输入文件调用一次这个助手:
def upload_file_to_container(blob_service_client, user_delegation_key,
sas_expiry, container_name, file_path):
blob_name = os.path.basename(file_path)
blob_client = blob_service_client.get_blob_client(container_name, blob_name)
with open(file_path, "rb") as data:
blob_client.upload_blob(data, overwrite=True)
sas_token = generate_blob_sas(
account_name=config._STORAGE_ACCOUNT_NAME,
container_name=container_name,
blob_name=blob_name,
user_delegation_key=user_delegation_key,
permission=BlobSasPermissions(read=True),
expiry=sas_expiry)
sas_url = f"{blob_client.url}?{sas_token}"
return models.ResourceFile(http_url=sas_url, file_path=blob_name)
应用还会为输出容器生成一个 SAS URL,授予写入权限。 任务使用该URL上传输出文件到存储:
sas_token = generate_container_sas(
account_name=config._STORAGE_ACCOUNT_NAME,
container_name=output_container_name,
user_delegation_key=user_delegation_key,
permission=ContainerSasPermissions(write=True, create=True, list=True),
expiry=sas_expiry)
output_container_sas_url = (
f"https://{config._STORAGE_ACCOUNT_NAME}.blob.core.chinacloudapi.cn/"
f"{output_container_name}?{sas_token}")
创建计算节点池
接下来,样本通过调用 create_pool在批处理账户中创建一个计算节点池。 此定义的函数使用 Batch BatchPoolCreateOptions 类设置节点数、VM 大小和池配置。 在此配置中,VirtualMachineConfiguration 对象指定 BatchVmImageReference 以指向发布于 Azure 市场 的 Ubuntu Server 22.04 LTS 映像。 Batch 支持 Azure 市场中的各种 VM 映像以及自定义 VM 映像。
节点数和 VM 大小使用定义的常数进行设置。 Batch 支持专用节点和 Spot 节点,你可以在池中使用其中任一类型或同时使用两者。 专用节点为您的池预留。 现成节点在 Azure 有剩余 VM 容量时以优惠价提供。 如果 Azure 没有足够容量,则现成节点会变得不可用。 默认情况下,此示例会创建一个仅包含五个大小为 Standard_A1_v2 的 Spot 节点的池。
除了物理节点属性,此池配置还包括 BatchStartTask 对象。 BatchStartTask 会在每个节点加入池时在该节点上执行,并且在每次节点重启时也会执行。 在此示例中,BatchStartTask 运行 Bash shell 命令,以在节点上安装 ffmpeg 包和依赖项。
create_pool方法将池提交到 Batch 服务。
new_pool = models.BatchPoolCreateOptions(
id=pool_id,
virtual_machine_configuration=models.VirtualMachineConfiguration(
image_reference=models.BatchVmImageReference(
publisher="canonical",
offer="0001-com-ubuntu-server-jammy",
sku="22_04-lts",
version="latest"
),
node_agent_sku_id="batch.node.ubuntu 22.04"),
vm_size=_POOL_VM_SIZE,
target_dedicated_nodes=_DEDICATED_POOL_NODE_COUNT,
target_low_priority_nodes=_LOW_PRIORITY_POOL_NODE_COUNT,
start_task=models.BatchStartTask(
command_line="/bin/bash -c \"apt-get update && apt-get install -y ffmpeg\"",
wait_for_success=True,
user_identity=models.UserIdentity(
auto_user=models.AutoUserSpecification(
scope=models.AutoUserScope.POOL,
elevation_level=models.ElevationLevel.ADMIN)),
)
)
batch_client.create_pool(pool=new_pool)
创建作业
Batch 作业可指定在其中运行任务的池以及可选设置,例如工作的优先级和计划。 此示例通过调用 create_job 创建作业。 这个已定义的函数使用 BatchJobCreateOptions 类在你的池中创建作业。
create_job方法将作业提交给批处理服务。 最初,该作业没有任务。
job = models.BatchJobCreateOptions(
id=job_id,
pool_info=models.BatchPoolInfo(pool_id=pool_id))
batch_client.create_job(job=job)
创建任务
应用通过调用 add_tasks 在作业中创建任务。 此定义的函数使用 BatchTaskCreateOptions 类创建任务对象列表。 每个任务都运行 ffmpeg,使用 resource_files 参数来处理输入 command_line 对象。 ffmpeg 此前已在创建池时安装在每个节点上。 在这里,命令行运行 ffmpeg 将每个输入 MP4(视频)文件转换为 MP3(音频)文件。
此示例在运行命令行后为 MP3 文件创建 OutputFile 对象。 每个任务的输出文件(在此示例中为一个)都会使用任务的 output_files 属性上传到关联的存储帐户中的一个容器。
然后,应用使用 create_tasks 方法将任务添加到作业,该方法将任务排成队列以在计算节点上运行。
tasks = list()
for idx, input_file in enumerate(input_files):
input_file_path = input_file.file_path
output_file_path = "".join((input_file_path).split('.')[:-1]) + '.mp3'
command = "/bin/bash -c \"ffmpeg -i {} {} \"".format(
input_file_path, output_file_path)
tasks.append(models.BatchTaskCreateOptions(
id='Task{}'.format(idx),
command_line=command,
resource_files=[input_file],
output_files=[models.OutputFile(
file_pattern=output_file_path,
destination=models.OutputFileDestination(
container=models.OutputFileBlobContainerDestination(
container_url=output_container_sas_url)),
upload_options=models.OutputFileUploadConfiguration(
upload_condition=models.OutputFileUploadCondition.TASK_SUCCESS))]
)
)
batch_client.create_tasks(job_id=job_id, task_collection=tasks)
监控任务
将任务添加到作业后,Batch 会自动将这些任务加入队列并安排它们在关联池中的计算节点上执行。 Batch 根据指定的设置处理所有任务排队、计划、重试和其他任务管理工作。
监视任务的执行有许多方法。 此示例中的 wait_for_tasks_to_complete 函数使用 BatchTaskState 对象在限定时间内监视任务是否处于某一状态,在本例中为“已完成”状态。
while datetime.datetime.now() < timeout_expiration:
print('.', end='')
sys.stdout.flush()
tasks = batch_client.list_tasks(job_id=job_id)
incomplete_tasks = [task for task in tasks if
task.state != models.BatchTaskState.COMPLETED]
if not incomplete_tasks:
print()
return True
else:
time.sleep(5)
...
清理资源
运行任务之后,应用自动删除所创建的输入存储容器,并允许你选择是否删除 Batch 池和作业。 该类的begin_delete_job和BatchClient方法在确认提示时各自启动相应的删除操作。 虽然不会对作业和任务本身收费,但会对计算节点收费。 因此,只需根据需要分配池。 删除池时会删除节点上的所有任务输出。 但是,输出文件保留在存储帐户中。
若不再需要资源组、Batch 帐户和存储帐户,请将其删除。 为此,请在 Azure 门户中选择 Batch 帐户所在的资源组,然后选择“删除资源组”。
后续步骤
在本教程中,你了解了如何执行以下操作:
- 通过 Batch 和存储帐户进行身份验证。
- 将输入文件上传到存储。
- 创建运行应用程序所需的计算节点池。
- 创建用于处理输入文件的作业和任务。
- 监视任务执行情况。
- 检索输出文件。
有关如何使用 Python API 来计划和处理 Batch 工作负载的更多示例,请参阅 GitHub 上的 Batch Python 示例。