适用对象:
![]() Mongodb
Mongodb
重要
你是否正在寻找一种数据库解决方案,以应对需要高扩展性、99.999% 可用性服务级别协议(SLA)、即时自动扩展和跨多个区域的自动故障转移的场景? 请考虑使用 Azure Cosmos DB for NoSQL。
默认情况下,Azure Cosmos DB 在所有物理分区中平均分发数据库或容器的预配吞吐量。 但由于工作负载的倾斜或分区键的选择,某些逻辑(以及物理)分区可能会比其他分区需要更多的吞吐量。 对于这些场景,Azure Cosmos DB 能够跨物理分区重新分发预配的吞吐量。 跨分区重新分发吞吐量有助于实现更好的性能,且无需根据最热分区配置总体吞吐量。
吞吐量重新分发功能适用于使用预配吞吐量(手动和自动缩放)的数据库和容器,不适用于无服务器容器。 你可以使用 Azure Cosmos DB PowerShell 或 Azure CLI 命令更改每个物理分区的吞吐量。
何时使用此功能
一般情况下,建议在满足下列两个条件的情况下使用此功能:
- 在集合的几个分区上,你总是看到标准化利用率为 100%。
- 你看到延迟一直高于可接受范围。
如果您未观察到 RU 消耗达到 100%,且端到端延迟是可接受的,则无需为每个分区重新配置 RU/s。
如果工作负荷具有一致的流量,并且 所有分区偶尔出现不可预知的峰值,建议使用 自动缩放。 自动缩放可确保满足吞吐量要求。
示例方案
假设我们有一个任务用于跟踪零售店中进行的交易。 由于大部分查询都是按 StoreId 进行划分,因此我们按 StoreId 进行分区。 然而,随着时间的推移,我们发现某些商店的活动比其他商店的活动更多,因此需要更多的吞吐量来为其工作负载提供支持。 对于针对这些 StoreId 的请求,我们看到了 100% 的标准化 RU 消耗量。 同时,其他商店不太活跃,所需吞吐量也较少。 接下来介绍如何重新分发吞吐量以实现更好的性能。
第 1 步:确定哪些物理分区需要更多的吞吐量
可通过两种方法来确定是否存在热分区。
选项 1:使用 Azure Monitor 指标
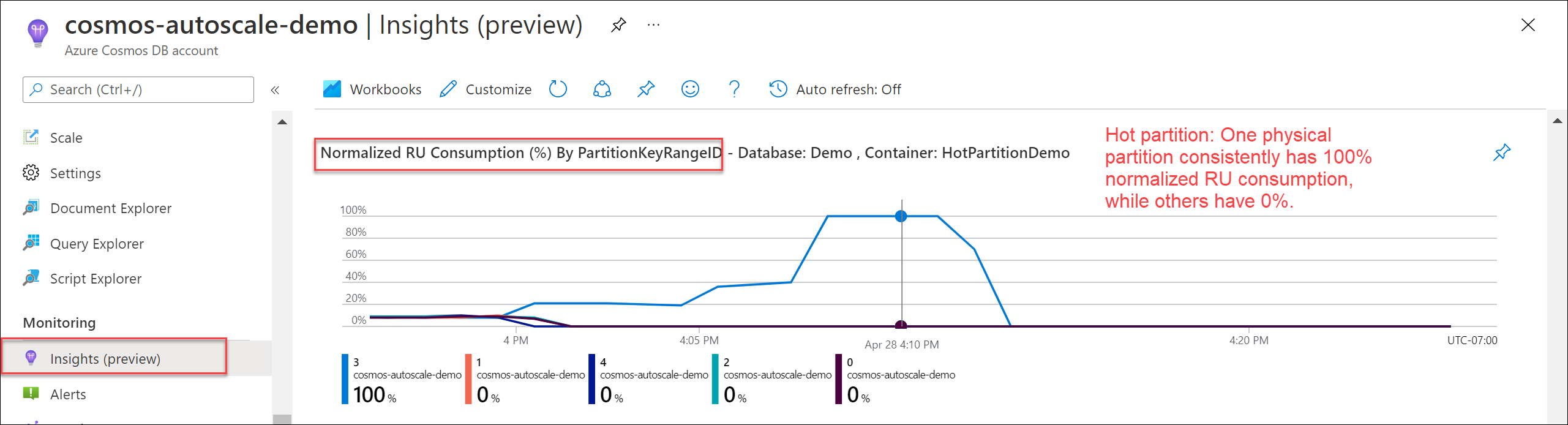
若要验证是否存在热分区,请导航到“见解”“吞吐量”>“按 PartitionKeyRangeID 列出的规范化 RU 消耗量(%)”。 筛选到特定数据库和容器。
每个分区键范围 ID 映射到一个物理分区。 寻找一种 PartitionKeyRangeId,其规范化 RU 消耗量始终高于其他的。 例如,一个值始终为 100%,但其他值为 30% 或更低。 诸如此类的模式可以指示热分区。
选项 2:使用诊断日志
可以根据诊断日志中 CDBPartitionKeyRUConsumption 的信息来获取有关在第二级粒度上消耗最多 RU/s 的逻辑分区键(和相应的物理分区)的更多信息。 请注意,示例查询使用 24 小时仅实现说明目的 - 建议通过至少 7 天的历史记录来了解该模式。
查找一段时间内消耗最多 RU/s 的物理分区 (PartitionKeyRangeId)
CDBPartitionKeyRUConsumption
| where TimeGenerated >= ago(24hr)
| where DatabaseName == "MyDB" and CollectionName == "MyCollection" // Replace with database and collection name
| where isnotempty(PartitionKey) and isnotempty(PartitionKeyRangeId)
| summarize sum(RequestCharge) by bin(TimeGenerated, 1m), PartitionKeyRangeId
| render timechart
对于给定的物理分区,查找每小时消耗最多 RU/s 的前 10 个逻辑分区键
CDBPartitionKeyRUConsumption
| where TimeGenerated >= ago(24hour)
| where DatabaseName == "MyDB" and CollectionName == "MyCollection" // Replace with database and collection name
| where isnotempty(PartitionKey) and isnotempty(PartitionKeyRangeId)
| where PartitionKeyRangeId == 0 // Replace with PartitionKeyRangeId
| summarize sum(RequestCharge) by bin(TimeGenerated, 1hour), PartitionKey
| order by sum_RequestCharge desc | take 10
步骤 2:确定每个物理分区的目标 RU/s
确定每个物理分区当前的 RU/s
首先,确定每个物理分区的当前 RU/s。 你可以使用 Azure Monitor 指标 PhysicalPartitionThroughput 并按维度 PhysicalPartitionId 进行拆分,以查看每个物理分区的 RU/s 值。
另外,如果之前没有更改过每个分区的吞吐量,可以使用以下公式:Current RU/s per partition = Total RU/s / Number of physical partitions
请按照缩放预配吞吐量 (RU/s) 的最佳做法一文中的指导来确定物理分区数。
您还可以使用 PowerShell Get-AzCosmosDBSqlContainerPerPartitionThroughput 和 Get-AzCosmosDBMongoDBCollectionPerPartitionThroughput 命令来读取每个物理分区上的当前 RU/s 值。
使用 Install-Module 安装启用了预发行功能的 Az.CosmosDB 模块。
$parameters = @{
Name = "Az.CosmosDB"
AllowPrerelease = $true
Force = $true
}
Install-Module @parameters
使用 Get-AzCosmosDBMongoDBCollectionPerPartitionThroughput 命令读取每个物理分区上的当前 RU/s。
// Container with dedicated RU/s
$somePartitionsDedicatedRUContainer = Get-AzCosmosDBMongoDBCollectionPerPartitionThroughput `
-ResourceGroupName "<resource-group-name>" `
-AccountName "<cosmos-account-name>" `
-DatabaseName "<cosmos-database-name>" `
-Name "<cosmos-collection-name>" `
-PhysicalPartitionIds ("<PartitionId>", "<PartitionId">, ...)
$allPartitionsDedicatedRUContainer = Get-AzCosmosDBMongoDBCollectionPerPartitionThroughput `
-ResourceGroupName "<resource-group-name>" `
-AccountName "<cosmos-account-name>" `
-DatabaseName "<cosmos-database-name>" `
-Name "<cosmos-collection-name>" `
-AllPartitions
// Database with shared RU/s
$somePartitionsSharedThroughputDatabase = Get-AzCosmosDBMongoDBDatabasePerPartitionThroughput `
-ResourceGroupName "<resource-group-name>" `
-AccountName "<cosmos-account-name>" `
-DatabaseName "<cosmos-database-name>" `
-PhysicalPartitionIds ("<PartitionId>", "<PartitionId">)
$allPartitionsSharedThroughputDatabase = Get-AzCosmosDBMongoDBDatabasePerPartitionThroughput `
-ResourceGroupName "<resource-group-name>" `
-AccountName "<cosmos-account-name>" `
-DatabaseName "<cosmos-database-name>" `
-AllPartitions
确定目标分区的 RU/s
接下来,确定我们想要分配给最热物理分区的 RU/秒值是多少。 我们称这一组为目标分区。 任何物理分区可以包含的最大 RU/s 是 10,000 RU/s。
方法正确与否取决于工作负载要求。 常见方法包括:
- 将 RU/秒增加 10%,并重复,直至达到所需的吞吐量。
- 如果不确定准确的百分比,可以从10%开始以保持保守。
- 如果已知此物理分区需要占用工作负载的大部分吞吐量,则可以先将 RU/s 增加一倍或将其增加到最大 10,000 RU/s,以较低者为准。
确定源分区的 RU/s
最后,确定要在其他物理分区上保留的 RU/s 值。 此选择将决定目标物理分区可从中获取吞吐量的分区。
在 PowerShell API 中,必须至少指定一个源分区来从中重新分发 RU/s。 也可以指定重新分发后每个物理分区应具有的自定义最小吞吐量。 如果未指定,默认情况下,Azure Cosmos DB 将确保重新分发后每个物理分区至少具有 100 RU/s。 建议显式指定最小吞吐量。
方法正确与否取决于工作负载要求。 常见方法包括:
- 从所有源分区平均获取 RU/s(分区 <= 10 个时效果最佳)
- 计算我们需要对每个源物理分区进行的偏移量。
Offset = Total desired RU/s of target partition(s) - total current RU/s of target partition(s)) / (Total physical partitions - number of target partitions) - 为每个源分区分配最小吞吐量 =
Current RU/s of source partition - offset
- 计算我们需要对每个源物理分区进行的偏移量。
- 从最不活跃的分区中获取 RU/s
- 使用 Azure Monitor 指标和诊断日志来确定哪些物理分区的流量/请求量最少
- 计算每个源物理分区所需的偏移量。
Offset = Total desired RU/s of target partition(s) - total current RU/s of target partition) / Number of source physical partitions - 为每个源分区分配最小吞吐量 =
Current RU/s of source partition - offset
第 3 步:以编程方式跨分区更改吞吐量
你可以使用 PowerShell 命令 Update-AzCosmosDBSqlContainerPerPartitionThroughput 来重新分发吞吐量。
为理解下例,我们举一个例子,假设一个容器总共有 6000 RU/s(6000 手动 RU/s 或 6000 自动缩放 RU/s)和 3 个物理分区。 根据分析,所需布局如下:
- 物理分区 0:1000 RU/s
- 物理分区 1:4000 RU/s
- 物理分区 2:1000 RU/s
将分区 0 和 2 指定为源分区,并在重新分配后,确保每个分区的最小 RU/s 为 1000 RU/s。 分区 1 是目标分区,指定它应为 4000 RU/s。
将 Update-AzCosmosDBMongoDBCollectionPerPartitionThroughput 用于具有专用 RU/s 的集合,将 Update-AzCosmosDBMongoDBDatabasePerPartitionThroughput 命令用于具有共享 RU/s 的数据库,以在物理分区之间重新分配吞吐量。 在共享吞吐量数据库中,物理分区的 ID 由 GUID 字符串表示。
$SourcePhysicalPartitionObjects = @()
$SourcePhysicalPartitionObjects += New-AzCosmosDBPhysicalPartitionThroughputObject -Id "0" -Throughput 1000
$SourcePhysicalPartitionObjects += New-AzCosmosDBPhysicalPartitionThroughputObject -Id "2" -Throughput 1000
$TargetPhysicalPartitionObjects = @()
$TargetPhysicalPartitionObjects += New-AzCosmosDBPhysicalPartitionThroughputObject -Id "1" -Throughput 4000
// Collection with dedicated RU/s
Update-AzCosmosDBMongoDBCollectionPerPartitionThroughput `
-ResourceGroupName "<resource-group-name>" `
-AccountName "<cosmos-account-name>" `
-DatabaseName "<cosmos-database-name>" `
-Name "<cosmos-collection-name>" `
-SourcePhysicalPartitionThroughputObject $SourcePhysicalPartitionObjects `
-TargetPhysicalPartitionThroughputObject $TargetPhysicalPartitionObjects
// Database with shared RU/s
Update-AzCosmosDBMongoDBDatabasePerPartitionThroughput `
-ResourceGroupName "<resource-group-name>" `
-AccountName "<cosmos-account-name>" `
-DatabaseName "<cosmos-database-name>" `
-SourcePhysicalPartitionThroughputObject $SourcePhysicalPartitionObjects `
-TargetPhysicalPartitionThroughputObject $TargetPhysicalPartitionObjects
完成重新分发后,可以通过查看 Azure Monitor 中的 PhysicalPartitionThroughput 指标来验证更改。 按维度 PhysicalPartitionId 拆分,查看每个物理分区的 RU/s 值。
如有必要,还可以重置每个物理分区的 RU/s,以便容器的 RU/s 均匀分布在所有物理分区中。
将 Update-AzCosmosDBMongoDBCollectionPerPartitionThroughput 命令用于具有专用 RU/s 的集合,将 Update-AzCosmosDBMongoDBDatabasePerPartitionThroughput 命令和参数 -EqualDistributionPolicy 用于具有共享 RU/s 的数据库,以在所有物理分区之间均匀分配 RU/s。
// Collection with dedicated RU/s
Update-AzCosmosDBMongoDBCollectionPerPartitionThroughput `
-ResourceGroupName "<resource-group-name>" `
-AccountName "<cosmos-account-name>" `
-DatabaseName "<cosmos-database-name>" `
-Name "<cosmos-collection-name>" `
-EqualDistributionPolicy
// Database with shared RU/s
Update-AzCosmosDBMongoDBDatabasePerPartitionThroughput `
-ResourceGroupName "<resource-group-name>" `
-AccountName "<cosmos-account-name>" `
-DatabaseName "<cosmos-database-name>" `
-EqualDistributionPolicy
第 4 步:验证和监视 RU/s 消耗量
完成重新分发后,可以通过查看 Azure Monitor 中的 PhysicalPartitionThroughput 指标来验证更改。 按照维度PhysicalPartitionId进行拆分,以查看每个物理分区拥有多少 RU/s。
建议监视每个分区的标准化 RU 消耗量。 有关详细信息,请查看第 1 步,验证是否达到了预期性能。
更改后,假设总体工作负载没有改变,则你可能会发现目标和源物理分区的规范化 RU 消耗量都比以前高。 规范化 RU 消耗量更高是预期的行为。 基本上,你分配的 RU/s 更接近每个分区实际消耗所需的量,因此规范化 RU 消耗量更高意味着每个分区都在充分利用其分配到的 RU/s。 你还应期望看到 429 异常的总体比率降低,因为热分区现在拥有更多的 RU/s 以处理请求。
局限性
预览资格条件
要使用预览版,Azure Cosmos DB 帐户必须满足以下所有条件:
- Azure Cosmos DB 帐户正在使用 API for MongoDB。
- 版本必须为 >= 3.6。
- Azure Cosmos DB 帐户正在使用预配置的吞吐量(手动或自动缩放)。 跨分区的吞吐量分布不适用于无服务器帐户。
无需注册即可使用预览版。 要使用此功能,请使用 PowerShell 或 Azure CLI 命令在资源的物理分区之间重新分配吞吐量。
后续步骤
通过以下文章了解如何使用预配吞吐量:
- 详细了解预配吞吐量。
- 详细了解请求单元。
- 是否需要监视热分区? 请参阅监视请求单位。
- 想要了解最佳做法? 请参阅缩放预配吞吐量的最佳做法。
- 详细了解速率限制错误