Azure Cosmos DB 支持许多 API,例如 SQL、MongoDB、Cassandra、Gremlin 和 Table。 每个 API 具有自身的数据库操作集。 这些操作包括简单的点读取和写入,以及复杂的查询等等。 每个数据库操作根据其复杂性消耗系统资源。
Azure Cosmos DB 使用请求单位(或 RU)规范化所有数据库操作的成本,并根据吞吐量(每秒请求单位数,即 RU/秒)来度量成本。
请求单元是一种性能货币,用于抽象化系统资源,例如处理(CPU)、每秒输入/输出作(IOPS),以及执行 Azure Cosmos DB 支持的数据库作所需的内存。 无论数据库操作是写入、点读取还是查询,都始终以 RU 来度量操作。 例如,通过其 ID 和分区键读取单个项 会使用一个请求单位。 该项的大小应约为 1 KB。 对于任何与 Azure Cosmos DB 一起使用的 API,这个估计大小均适用。 可以使用 Azure Cosmos DB 容量计算器为吞吐量成本建模。
下图展示了资源单位(RU)的概念概要。
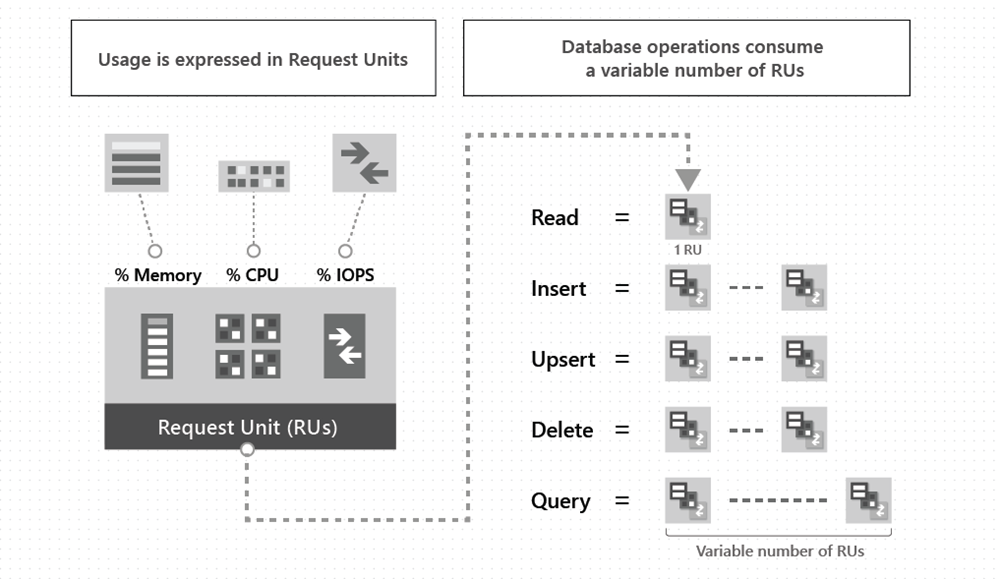
若要管理和规划容量,Azure Cosmos DB 可以确保在给定的数据集上,对于某个数据库操作的请求单位(RU)数量是确定的。 可以检查响应头以跟踪任何数据库操作消耗的 RU 数量。 了解影响 RU 费用的因素以及应用程序吞吐量要求后,可以经济高效地运行应用程序。
正在使用的 Azure Cosmos DB 帐户的类型决定了消耗的请求单位 (RU) 的计费方式。 可以通过三种模式创建帐户:
预配吞吐量模式:在此模式下,可以按秒来分配应用程序的 RU 数,增量为每秒 100 RU。 若要调整应用程序的预配吞吐量,可以随时以 100 请求单位(RU)的增量或减量来增加或减少 RU 数。 可以通过编程方式或使用Azure portal进行更改。 系统会根据预配的每秒 RU 数按小时计费。 有关详细信息,请参阅 预配的吞吐量。
可以按两种不同的粒度分配吞吐量:
Containers:有关详细信息,请参阅将吞吐量分配给 Azure Cosmos DB 容器。
Databases:有关详细信息,请参阅将吞吐量分配给 Azure Cosmos DB 数据库。
无服务器模式:在此模式下,在 Azure Cosmos DB 帐户中创建资源时无需分配任何吞吐量。 计费周期结束时,会针对数据库操作消耗的请求单位数计费。 若要了解详细信息,请参阅无服务器吞吐量一文。
自动缩放模式:在此模式下,可以根据数据库或容器的使用情况自动即时缩放数据库或容器的吞吐量 (RU/s)。 此缩放操作不会影响工作负载的可用性、延迟、吞吐量或性能。 此模式非常适合具有可变或不可预知流量模式的任务关键型工作负荷,并且需要服务级别协议(SLA)实现高性能和规模。 若要了解详细信息,请参阅自动缩放吞吐量一文。
请求单位注意事项
在估计你的工作负荷消耗的 RU 数量时,请考虑以下因素:
项大小:随着项的增大,读取或写入该项所要消耗的 RU 数也会增加。
项索引:默认情况下会自动为每个项创建索引。 如果选择不为容器中的某些项创建索引,则消耗的 RU 数将会减少。
项属性计数:假设所有属性采用默认索引,写入某个项所要消耗的 RU 数会随着项属性计数的增加而增加。
带索引的属性:每个容器的索引策略都可确定默认情况下要进行索引的属性类别。 若要减少写入操作的 RU 消耗,请限制带索引的属性数目。
数据一致性:在执行读取操作时,强一致性和有限过期一致性级别的 RU 消耗量大约是其他宽松一致性级别的两倍。
读取的类型:相较于查询,点读取消耗的 RU 更少。
查询模式:查询的复杂性会影响操作使用的 RU 数。 影响查询操作成本的因素:
查询结果数
谓词数
谓词性质
用户定义的函数数目
源数据的大小
结果集的大小
投影
对相同数据的相同查询在重复执行时始终消耗相同数量的 RU。
脚本的使用:与查询一样,存储过程和触发器也是根据所执行的操作的复杂性来消耗 RU。 开发应用程序时,请检查请求费用标头,以更好地了解每个操作消耗的 RU 容量。
请求单位和多个区域
如果在 Azure Cosmos DB 容器(或数据库)上分配‘R’ RU,Azure Cosmos DB 可确保在与 Azure Cosmos DB 帐户关联的每个
假设 Azure Cosmos DB 容器配置了 'R' RU,并且存在与 Azure Cosmos DB 帐户关联的 'N' 区域, 容器上的多区域可用 RU 总数 = R x N。
所选的一致性模型也会影响吞吐量。 与更强的一致性级别(有限不一致性或强一致性)相比,更宽松的一致性级别(会话、*一致前缀和最终一致性)可以获得约 2 倍的读取吞吐量。
相关内容
- 在 Azure Cosmos DB 容器和数据库中分配吞吐量。
- Azure Cosmos DB 上的 无服务器模式。
- 逻辑分区