在本快速入门中,你将使用 Python Azure SDK 为 NoSQL 应用程序部署基本Azure Cosmos DB。 NoSQL的Azure Cosmos DB是一种无架构数据存储,允许应用程序在云中存储非结构化数据。 使用 Azure SDK for Python 查询容器中的数据,并对单个项执行常规操作。
API 参考文档 | Library 源代码 | Package (PyPI) | Azure Developer CLI
先决条件
- Azure Developer CLI
- Docker Desktop
- Python 3.12
如果没有Azure帐户,请在开始前创建 Trial。
初始化项目
使用Azure开发人员 CLI(azd)为NoSQL帐户创建Azure Cosmos DB并部署容器化示例应用程序。 示例应用程序使用客户端库来管理、创建、读取和查询示例数据。
在空目录中打开终端。
如果尚未进行身份验证,请使用
azd auth login向 Azure 开发人员 CLI 进行身份验证。 按照工具指定的步骤,使用首选Azure凭据向 CLI 进行身份验证。azd auth login使用
azd init来初始化项目。azd init --template cosmos-db-nosql-python-quickstart在初始化期间,配置唯一的环境名称。
使用
azd up部署Azure Cosmos DB帐户。 Bicep 模板还会部署一个示例 Web 应用程序。azd up在预配过程中,选择订阅、所需位置和目标资源组。 等待预配过程完成。 此过程可能需要大约 5 分钟。
完成Azure资源的预配后,输出中将包含正在运行的 Web 应用程序的 URL。
Deploying services (azd deploy) (✓) Done: Deploying service web - Endpoint: <https://[container-app-sub-domain].azurecontainerapps.io> SUCCESS: Your application was provisioned and deployed to Azure in 5 minutes 0 seconds.使用控制台中的 URL 在浏览器中导航到 Web 应用程序。 观察正在运行的应用的输出。
安装客户端库
客户端库可通过 Python 包索引作为 azure-cosmos 库使用。
打开终端并导航到
/src文件夹。cd ./src使用
azure-cosmos安装pip install包(如果尚未安装)。pip install azure-cosmos另请安装
azure-identity包(如果尚未安装)。pip install azure-identity打开并查看 src/requirements.txt 文件以验证 和
azure-cosmos条目是否同时存在azure-identity。
导入库文件
将 DefaultAzureCredential 和 CosmosClient 类型导入应用程序代码。
from azure.identity import DefaultAzureCredential
from azure.cosmos import CosmosClient
对象模型
| Name | Description |
|---|---|
CosmosClient |
此类是主要客户端类,用于管理帐户范围的元数据或数据库。 |
DatabaseProxy |
这个类表示帐户内的数据库。 |
ContainerProxy |
这个类主要用于对容器或容器中存储的项执行读取、更新和删除操作。 |
PartitionKey |
此类表示逻辑分区键。 许多常见操作和查询都需要这个类。 |
代码示例
模板中的示例代码使用名为 cosmicworks 的数据库和名为 products 的容器。
products 容器包含每个产品的名称、类别、数量、唯一标识符和销售标志等详细信息。 该容器使用 /category 属性作为逻辑分区键。
对客户端进行身份验证
此示例创建一个 CosmosClient 类型的新实例并使用 DefaultAzureCredential 实例进行身份验证。
credential = DefaultAzureCredential()
client = CosmosClient(url="<azure-cosmos-db-nosql-account-endpoint>", credential=credential)
获取数据库
使用 client.get_database_client 检索名为 cosmicworks 的现有数据库。
database = client.get_database_client("cosmicworks")
获取容器
使用 products 检索现有的 database.get_container_client 容器。
container = database.get_container_client("products")
创建一个项目
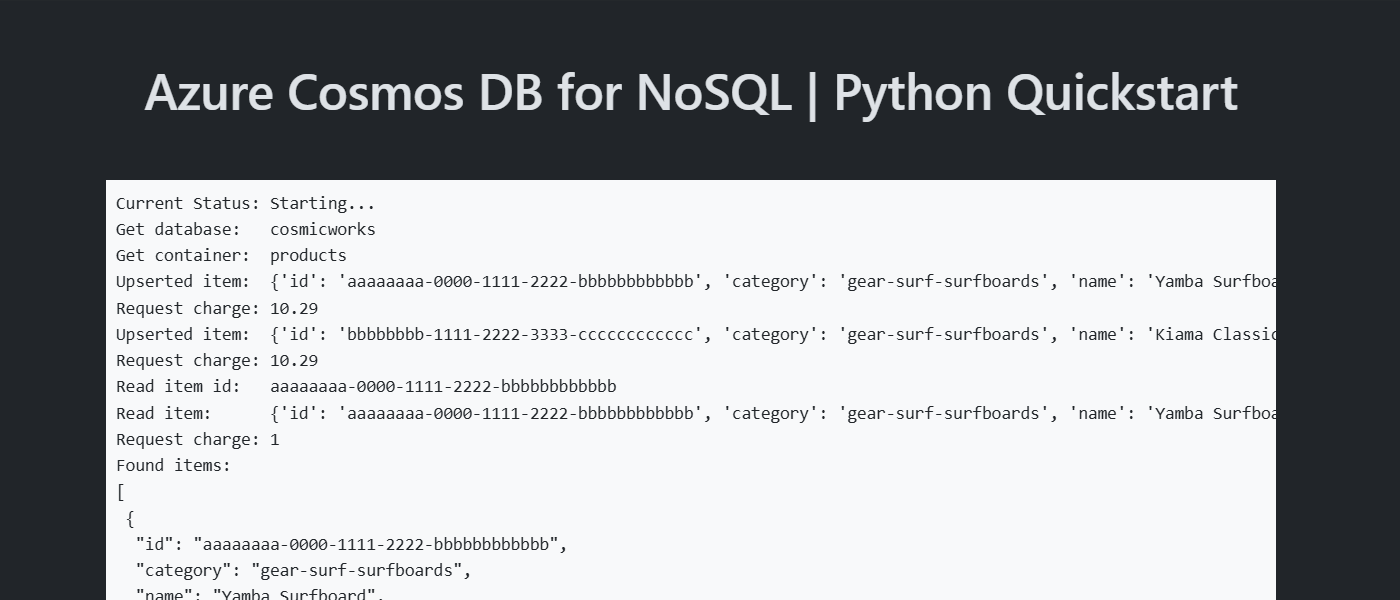
使用要序列化为 JSON 的所有成员生成一个新对象。 在此示例中,该类型具有唯一标识符以及用于类别、名称、数量、价格和销售的字段。 使用 container.upsert_item 在容器中创建某个项。 如果该项已经存在,此方法会“更新插入”该项,从而有效地替换该项。
new_item = {
"id": "aaaaaaaa-0000-1111-2222-bbbbbbbbbbbb",
"category": "gear-surf-surfboards",
"name": "Yamba Surfboard",
"quantity": 12,
"sale": False,
}
created_item = container.upsert_item(new_item)
读取项
同时使用唯一标识符 (id) 和分区键字段来执行点读取操作。 使用 container.read_item 以有效检索特定项。
existing_item = container.read_item(
item="aaaaaaaa-0000-1111-2222-bbbbbbbbbbbb",
partition_key="gear-surf-surfboards",
)
查询项
使用 container.query_items 对容器中的多个项执行查询。 使用此参数化查询查找指定类别中的所有项:
SELECT * FROM products p WHERE p.category = @category
queryText = "SELECT * FROM products p WHERE p.category = @category"
results = container.query_items(
query=queryText,
parameters=[
dict(
name="@category",
value="gear-surf-surfboards",
)
],
enable_cross_partition_query=False,
)
循环遍历查询结果。
items = [item for item in results]
output = json.dumps(items, indent=True)
探索您的数据
使用用于Azure Cosmos DB的 Visual Studio Code 扩展来浏览NoSQL数据。 可以执行核心数据库操作,这些操作包括但不限于:
- 使用剪贴簿或查询编辑器执行查询
- 修改、更新、创建和删除项
- 从其他源导入批量数据
- 管理数据库和容器
有关详细信息,请参阅 如何使用 Visual Studio Code 扩展浏览NoSQL数据的Azure Cosmos DB。
清理资源
不再需要示例应用程序或资源时,请删除相应的部署和所有资源。
azd down