Azure 数据资源管理器中的业务连续性和灾难恢复使企业能够在发生中断时继续运营。 本文详细介绍了多个灾难恢复配置,具体取决于可恢复性要求(RPO 和 RTO)、所需的工作量和成本。
有关适用于 Azure 数据资源管理器 的可靠性选项的更多信息,包括可用性区域支持、备份和防止某些类型的人为错误,请参阅 Azure 数据资源管理器 中的可靠性。
灾难恢复配置
恢复时间目标 (RTO) 是指发生中断后恢复所用的时间。 例如,RTO 为 2 小时意味着应用程序必须在中断后两小时内恢复正常运行。 恢复点目标 (RPO) 是指在发生中断后,在中断期间丢失的数据量超过允许的阈值之前可经过的时间间隔。 例如,如果 RPO 是 24 小时,而应用程序的数据是从 15 年前开始的,则它们仍处于商定的 RPO 参数范围内。
在规划灾难恢复时,引入、处理和特选过程需要预先进行精心设计。 引入是指从各种源集成到Azure 数据资源管理器中的数据;处理是指转换和类似活动;策展是指具体化视图、导出到数据湖等。
以下是常用的灾难恢复配置:
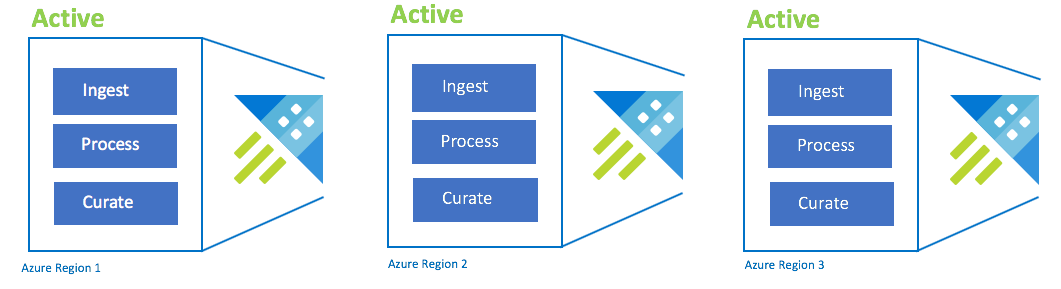
主动-主动-主动配置
此配置也称为始终在线。 对于无法容忍中断的关键应用程序部署,应跨Azure配对区域使用多个Azure 数据资源管理器群集。 在所有群集中并行设置引入、处理和管理。 不同区域的群集 SKU 必须相同。 Azure确保在Azure配对区域中逐步推出和错开更新。 Azure区域中断不会导致应用程序中断。 可能会遇到一些延迟或性能下降的情况。
| 配置 | RPO | RTO | 工作量 | 成本 |
|---|---|---|---|---|
| 主动-主动-主动-n | 0 小时 | 0 小时 | 较低 | 最高 |
主动-主动配置
此配置与 active-active-active 配置 相同,但仅涉及两个 Azure 配对区域。 配置双重引入、处理和整理。 将用户路由到最近的区域。 不同区域的群集 SKU 必须相同。

| 配置 | RPO | RTO | 工作量 | 成本 |
|---|---|---|---|---|
| 主动-主动 | 0 小时 | 0 小时 | 较低 | 高 |
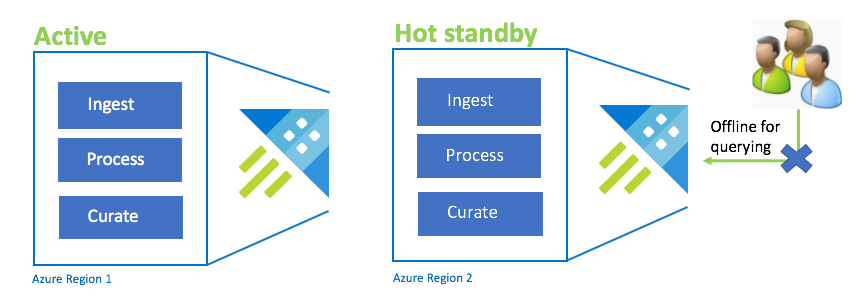
主动-热备用配置
活动-热点配置与活动-活动配置在双重引入、处理和数据整理方面相似。 当备用群集在线进行数据引入、处理和管理时,它无法执行查询。 备用群集不需要与主群集位于同一 SKU 中。 它可以是较小的 SKU 和规模,这可能会导致其性能较低。 在灾难场景中,用户会被重定向到备用群集,你可以选择纵向扩展该群集以提高性能。
| 配置 | RPO | RTO | 工作量 | 成本 |
|---|---|---|---|---|
| 主动-热备用 | 0 小时 | 低 | 中等 | 中等 |
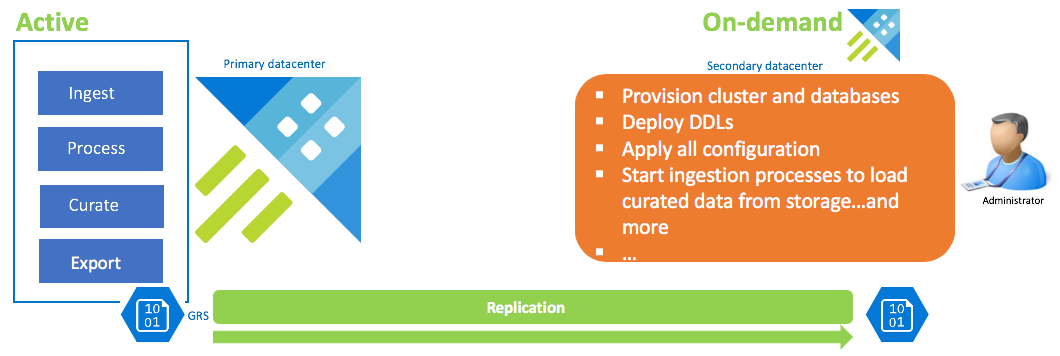
按需数据恢复配置
此解决方案提供最低的可恢复性(最高 RPO 和 RTO),是成本最低且工作量最高的解决方案。 在此配置中,没有数据恢复群集。 配置将特选数据(除非也需要原始数据和中间数据)连续导出到配置了异地冗余存储 (GRS) 的存储帐户。 如果发生灾难恢复情况,则会启动群集数据恢复。 此时将应用 DDL、配置、策略和流程。 使用引入属性kustoCreationTime从存储中引入数据,以覆盖默认的系统时间作为引入时间。
| 配置 | RPO | RTO | 工作量 | 成本 |
|---|---|---|---|---|
| 按需数据恢复群集 | 最高 | 最高 | 最高 | 最低 |
灾难恢复配置选项摘要
| 配置 | 可恢复性 | RPO | RTO | 工作量 | 成本 |
|---|---|---|---|---|---|
| 主动-主动-主动-n | 最高 | 0 小时 | 0 小时 | 较低 | 最高 |
| 主动-主动 | 高 | 0 小时 | 0 小时 | 较低 | 高 |
| 主动-热备用 | 中等 | 0 小时 | 低 | 中等 | 中等 |
| 按需数据恢复群集 | 最低 | 最高 | 最高 | 最高 | 最低 |
最佳做法
无论选择哪种灾难恢复配置,请遵循以下最佳做法:
- 所有数据库对象、策略和配置都应该保存在源代码管理中,这样就可以从发布自动化工具中将其发布到群集。
- 设计、开发和实现验证例程,以确保从数据角度来看所有群集都是同步的。 Azure 数据资源管理器支持 跨群集连接。 在表之间进行简单的行数统计可以帮助验证。
- 发布过程应该包括可确保群集镜像实现的治理检查和制衡措施。
- 充分了解从头开始构建群集所需完成的所有操作。
- 创建部署单元清单。 你的列表符合你的需求,但应包括:部署脚本、引入连接、BI 工具和其他重要配置。