适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
概述
通过 Azure 数据工厂和 Synapse Analytics 映射数据流的调试模式,你可以在生成和调试数据流时以交互方式观察数据形状转换。 调试会话可在数据流设计会话中使用,也可在数据流的管道调试执行期间使用。 若要启用调试模式,请在有数据流活动时使用数据流画布或管道画布顶部栏中的“数据流调试”按钮。
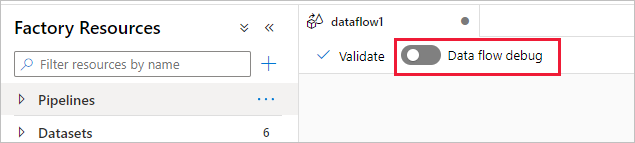

开启滑块后,系统将提示你选择要使用的集成运行时配置。 如果选择“AutoResolveIntegrationRuntime”,则将启动具有八个常规计算内核的群集(默认 60 分钟时间)。 如果要在会话超时之前允许更多空闲团队,可以选择更高的 TTL 设置。 有关数据流集成运行时的详细信息,请参阅 Integration Runtime 性能。
启用调试模式时,将使用活动的 Spark 群集以交互方式构建数据流。 关闭调试后,会话将关闭。 你应了解数据工厂在打开调试会话期间产生的每小时费用。
大多数情况下,最好在调试模式下生成数据流,以便在发布工作之前验证业务逻辑并查看数据转换。 使用管道面板上的“调试”按钮测试管道中的数据流。
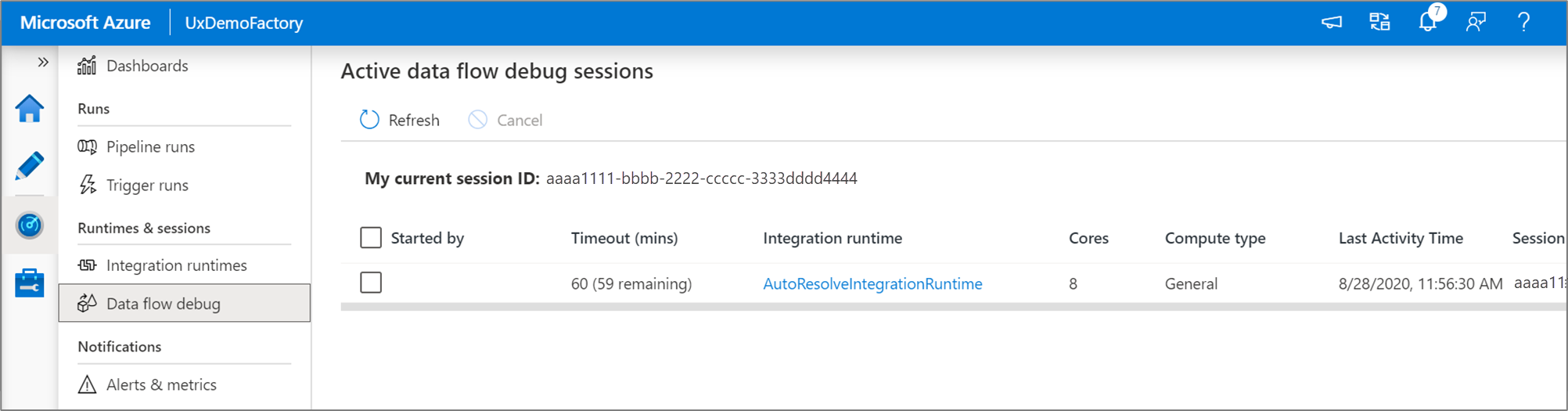
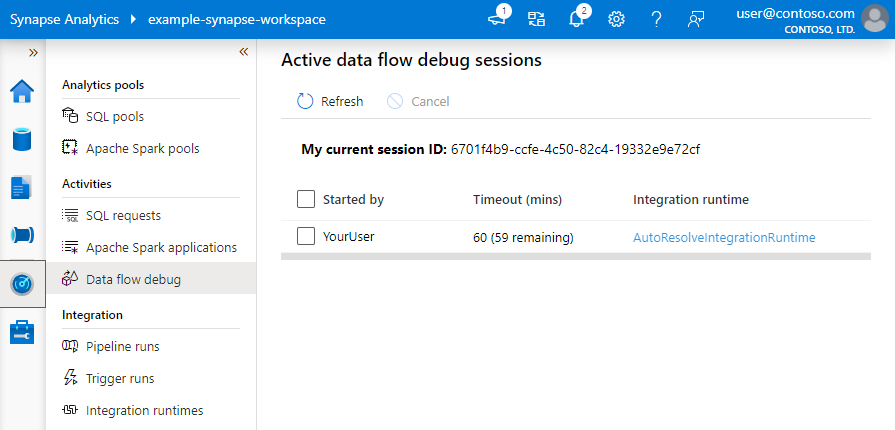
注意
用户从浏览器 UI 启动的每个调试会话都是具有其自己的 Spark 群集的新会话。 可以将监视视图用于之前图片中显示的调试会话,以查看和管理调试会话。 每个调试会话执行的每小时都会向你收费,包括 TTL 时间。
群集状态
设计图面顶部的群集状态指示器在群集准备好进行调试时会变为绿色。 如果群集已热,那么绿色指示器几乎会立即出现。 如果在你进入调试模式时 Spark 群集尚未运行,则该群集会执行冷启动。 指示器会旋转,直到环境准备好进行交互式调试为止。
完成调试后,请关闭调试开关,这样 Spark 群集就可以终止,你不再需要为调试活动付费。
调试设置
开启调试模式后,可以编辑数据流预览数据的方式。 可以通过单击“数据流”画布工具栏上的“调试设置”来编辑调试设置。 你可以在此处选择要用于每个“源”转换的行限制或文件源。 此设置中的行限制仅适用于当前调试会话。 还可以选择要用于 Azure Synapse Analytics 源的暂存链接服务。
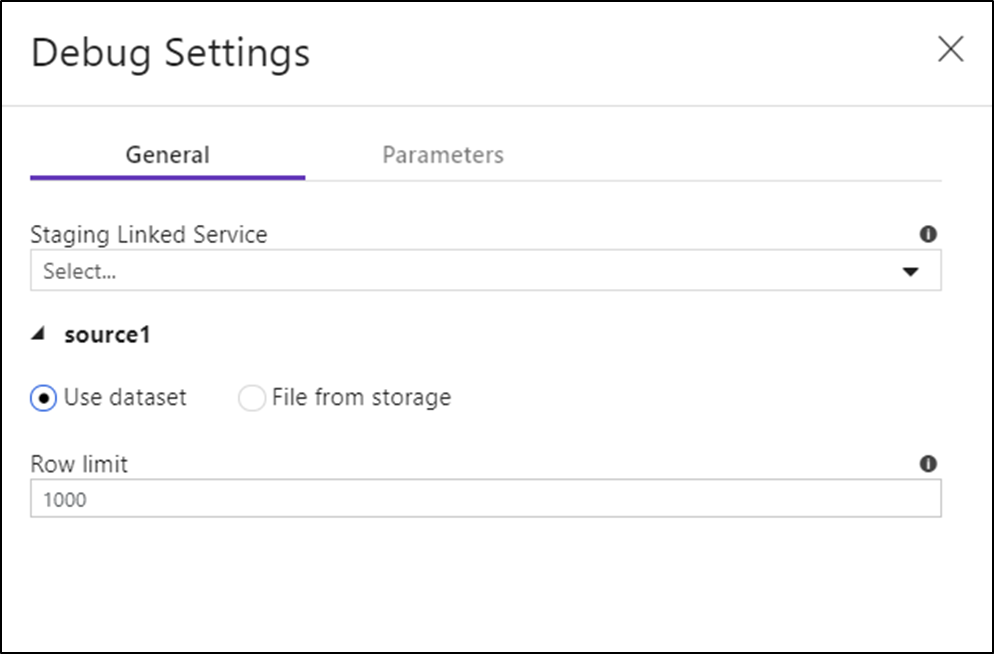
如果在数据流或任何其引用的数据集中具有参数,可以通过选择“参数”选项卡指定在调试期间要使用的值。
使用此处的采样设置可以指向样本文件或数据样本表,这样就不必更改源数据集。 通过使用此处的样本文件或表,可以在针对数据的子集进行测试时,在数据流中维护相同的逻辑和属性设置。
数据流中用于调试模式的默认 IR 是具有 4 核单驱动程序节点的小型 4 核单工作器节点。 这非常适合用于测试数据流逻辑时的较小数据样本。 如果在数据预览期间在调试设置中扩展行限制,或在管道调试期间在源中设置更多采样行数,则不妨考虑在新的 Azure Integration Runtime 中设置更大的计算环境。 然后,你可以使用更大的计算环境重新启动调试会话。
数据预览
打开调试后,“数据预览”选项卡将在底部面板上亮起。 如果未打开调试模式,数据流将仅在“检查”选项卡中显示传入和传出每个转换的当前元数据。数据预览仅查询你在调试设置中设置为限制的行数。 选择“刷新”以基于当前转换更新数据预览。 如果源数据已更改,请在源中选择“刷新并>重新提取”。
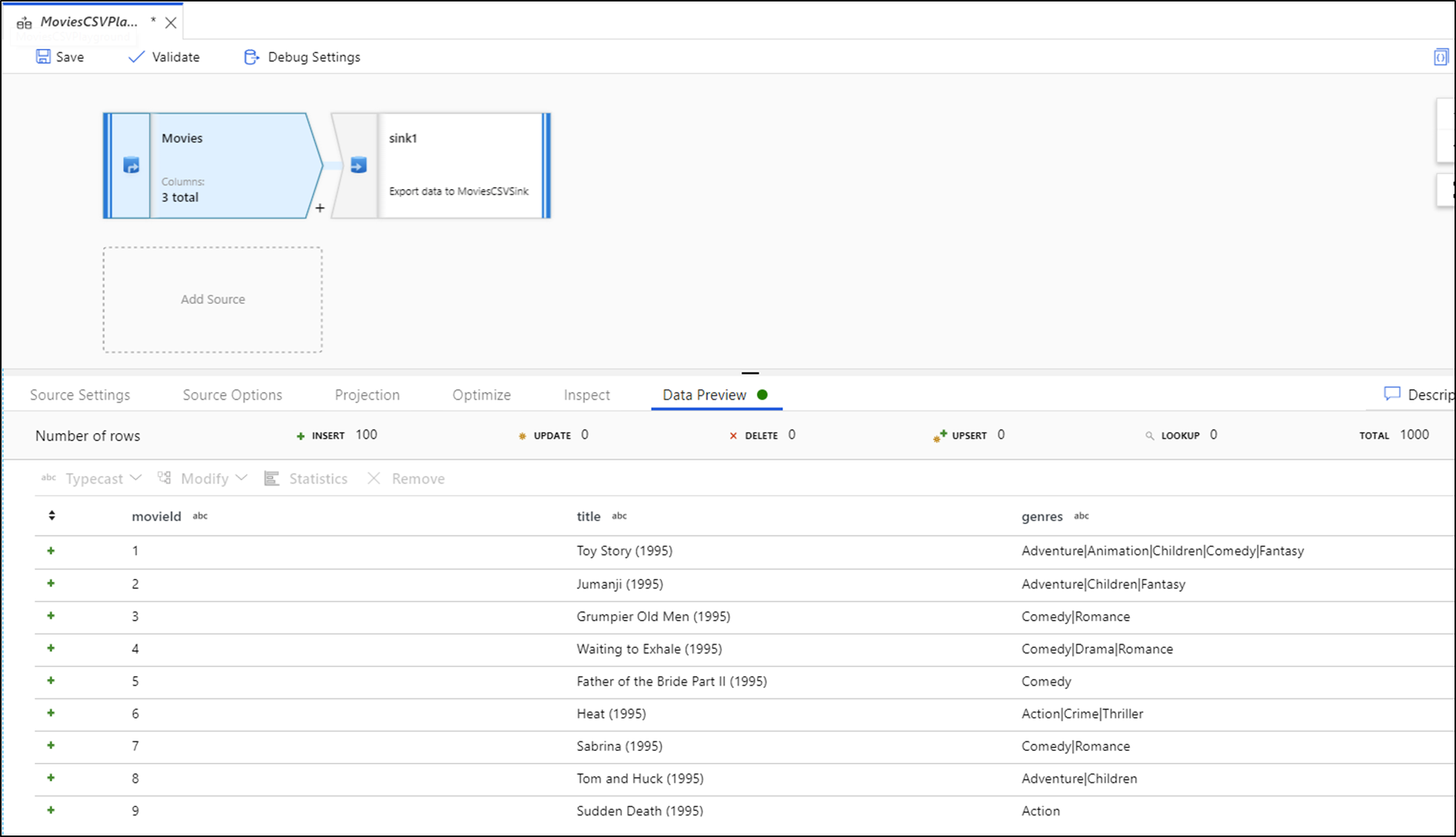
可在数据预览中对列进行排序,并使用拖放功能对列进行重新排列。 此外,数据预览面板顶部还有一个导出按钮,可用于将预览数据导出为 CSV 文件进行脱机数据浏览。 可使用此功能导出最多 1,000 行的预览数据。
注意
文件源仅限制你看到的行,而不是正在读取的行。 对于非常大的数据集,建议你占用该文件的一小部分并将其用于测试。 在“调试设置”中为文件数据集类型的每个源选择临时文件。
在调试模式下运行数据流时,您的数据不会写入到汇聚转换。 调试会话旨在用作转换测试工具。 调试期间不需要接收器,并且会在数据流中忽略接收器。 如果希望在接收器中测试数据写入,请从管道执行数据流,并从管道使用调试执行。
数据预览是 Spark 内存的数据帧中使用行限制和数据采样的转换数据的快照。 因此,在这种情况下,不会使用或测试接收器驱动程序。
注意
数据预览根据浏览器的区域设置显示时间。
测试联接条件
当单元在测试“联接”、“存在”或“查找”转换时,请确保使用少量已知数据进行测试。 可以使用上文描述的“调试设置”选项设置临时文件以用于测试。 这很有必要,因为在对大型数据集中的行进行限制或采样时,你无法预测哪些行和哪些键将被读取到流中进行测试。 结果是非确定性的,这意味着你的联接条件可能失败。
快速操作
看到数据预览后,就可以生成快速转换以对列进行类型强制转换、删除或修改。 选择列标题,然后从数据预览工具栏中选择其中一个选项。
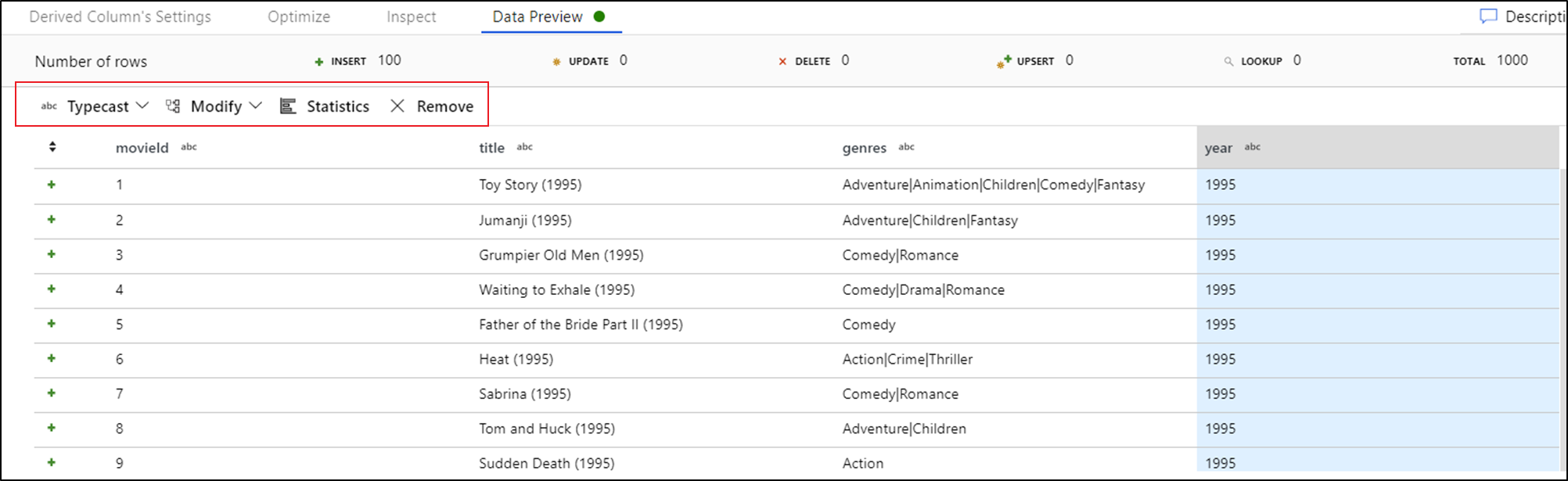
选择“修改”后,数据预览将立即刷新。 选择右上角的“确认”,以生成新的转换。
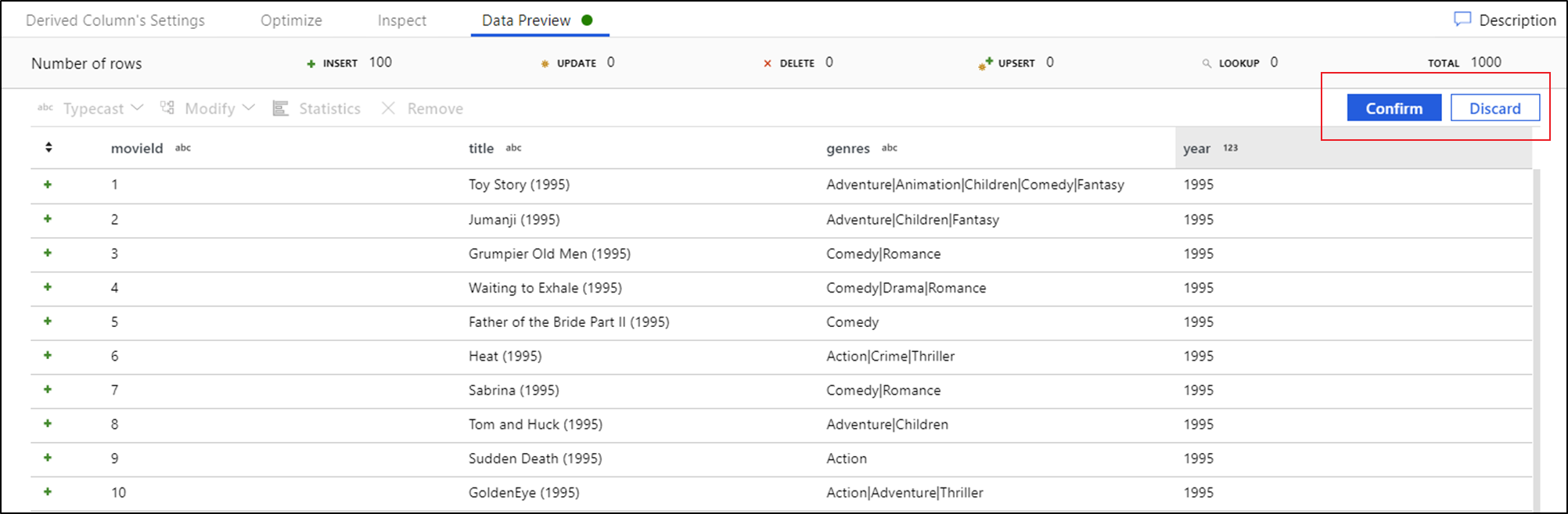
“类型强制转换”和“修改”将生成“派生列”转换,“删除”将生成“选择”转换。
注意
如果编辑数据流,则需要在添加快速转换之前重新提取数据预览。
数据事件探查
通过在数据预览选项卡中选择单个列并在数据预览工具栏中单击“统计信息”,将在数据网格的最右侧弹出一个图表,其中包含有关每个字段的详细统计信息。 该服务将根据要显示的图表类型的数据采样做出决定。 高基数字段将默认为 NULL/NOT NULL 图表,而具有低基数的分类和数值数据将显示条形图(显示数据值频率)。 你还将看到字符串字段的最大/最小长度、数值字段中的最小/最大值、标准偏差、百分点值、计数和平均值。
