适用于: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Azure Data Factory和 Synapse Analytics 支持对管道进行迭代开发和调试。 这些功能使你能够在创建拉取请求或将其发布到服务之前测试更改。
调试管道
当您使用管道画布编写时,可使用调试功能进行活动测试。 进行测试运行时,在选择“调试”之前,不需要将更改发布到服务。 若要确保所做的更改在你更新工作流之前按预期生效,则可使用此功能。
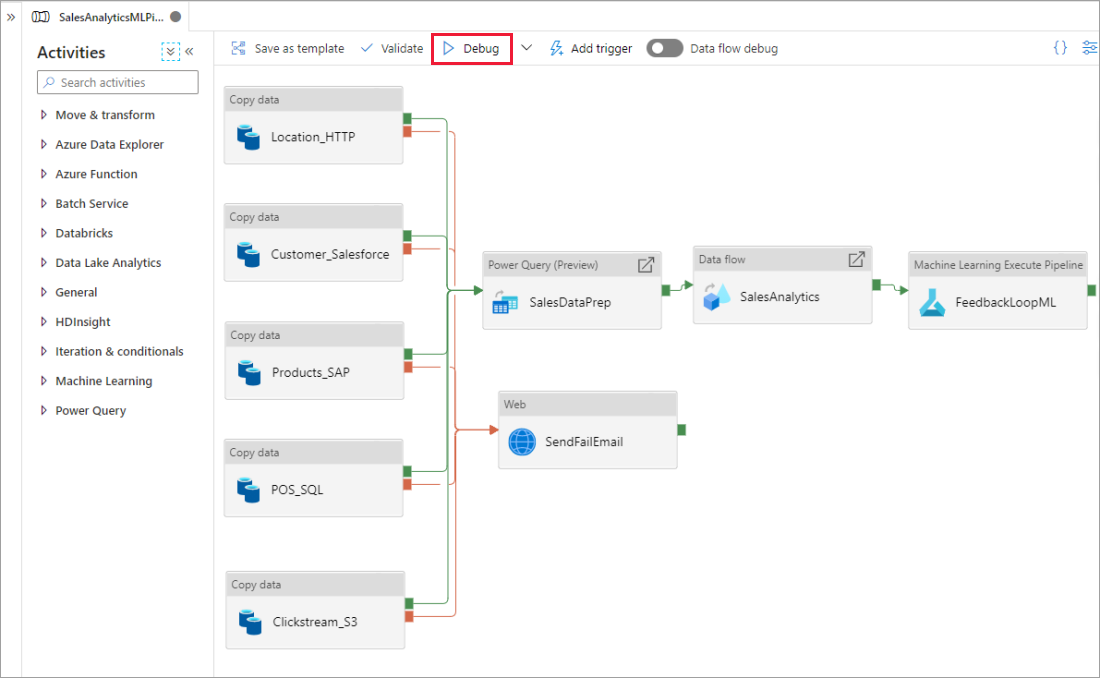
管道运行时,你可在管道画布的“输出”选项卡中查看每个活动的结果。
在管道画布的“输出” 窗口中查看测试运行的结果。
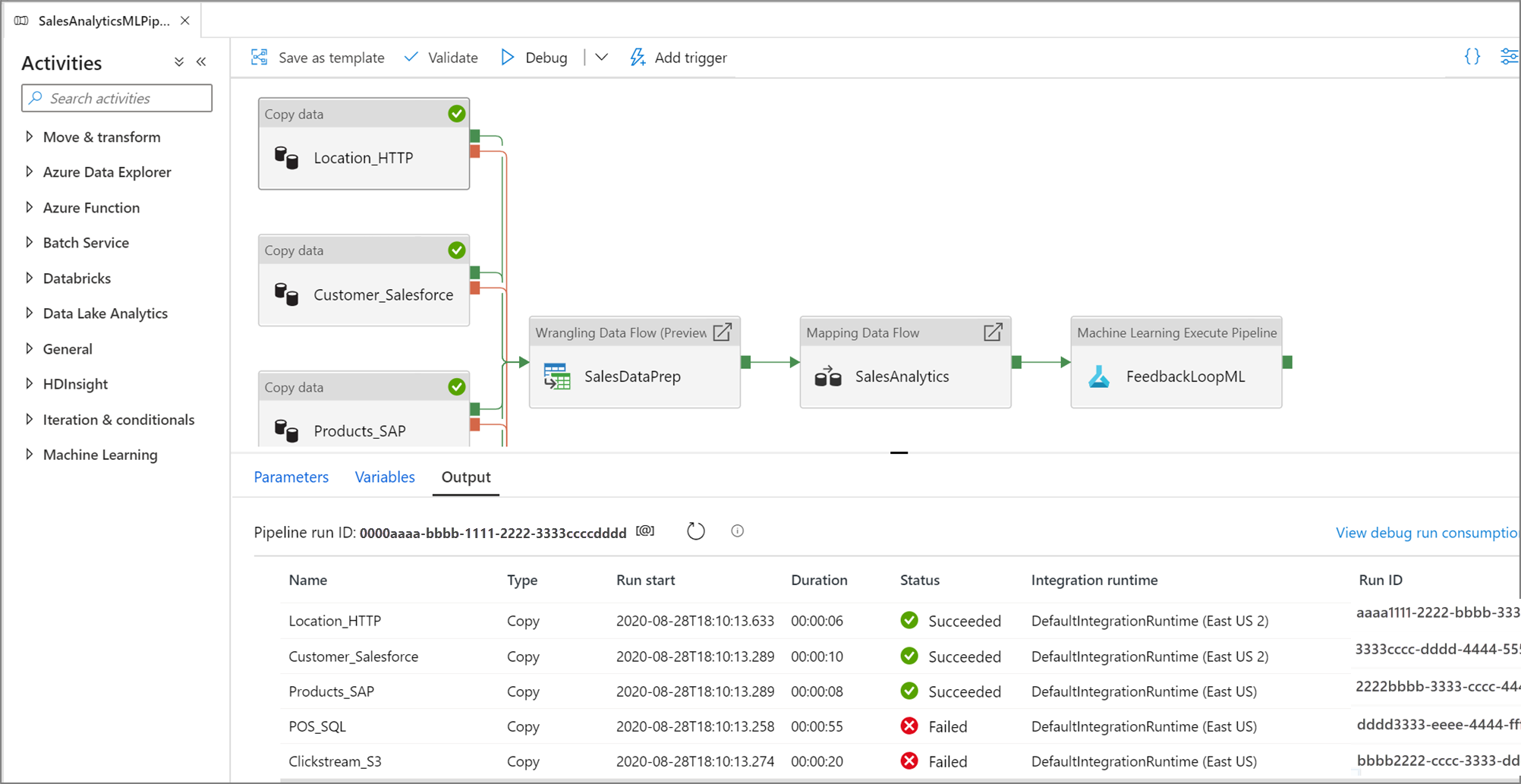
在测试运行成功后,向管道中添加更多活动并继续以迭代方式进行调试。 还可以在测试运行正在执行时将其取消。
重要
选择“调试”选项实际上会运行管道。 例如,如果管道包含复制活动,则测试运行会将数据从源复制到目标。 因此,在调试时,建议在复制活动和其他活动中使用测试文件夹。 在调试管道后,切换到要在正常操作中使用的实际文件夹。
设置断点
此服务还允许你一直调试管道,直到到达管道画布中的某个特定活动。 在要测试到的活动上设置断点,然后选择“调试”。 此服务确保测试仅运行至管道画布上的断点活动。 如果不想测试整个管道,只想测试该管道内的一部分活动,则此“调试至” 功能非常有用。
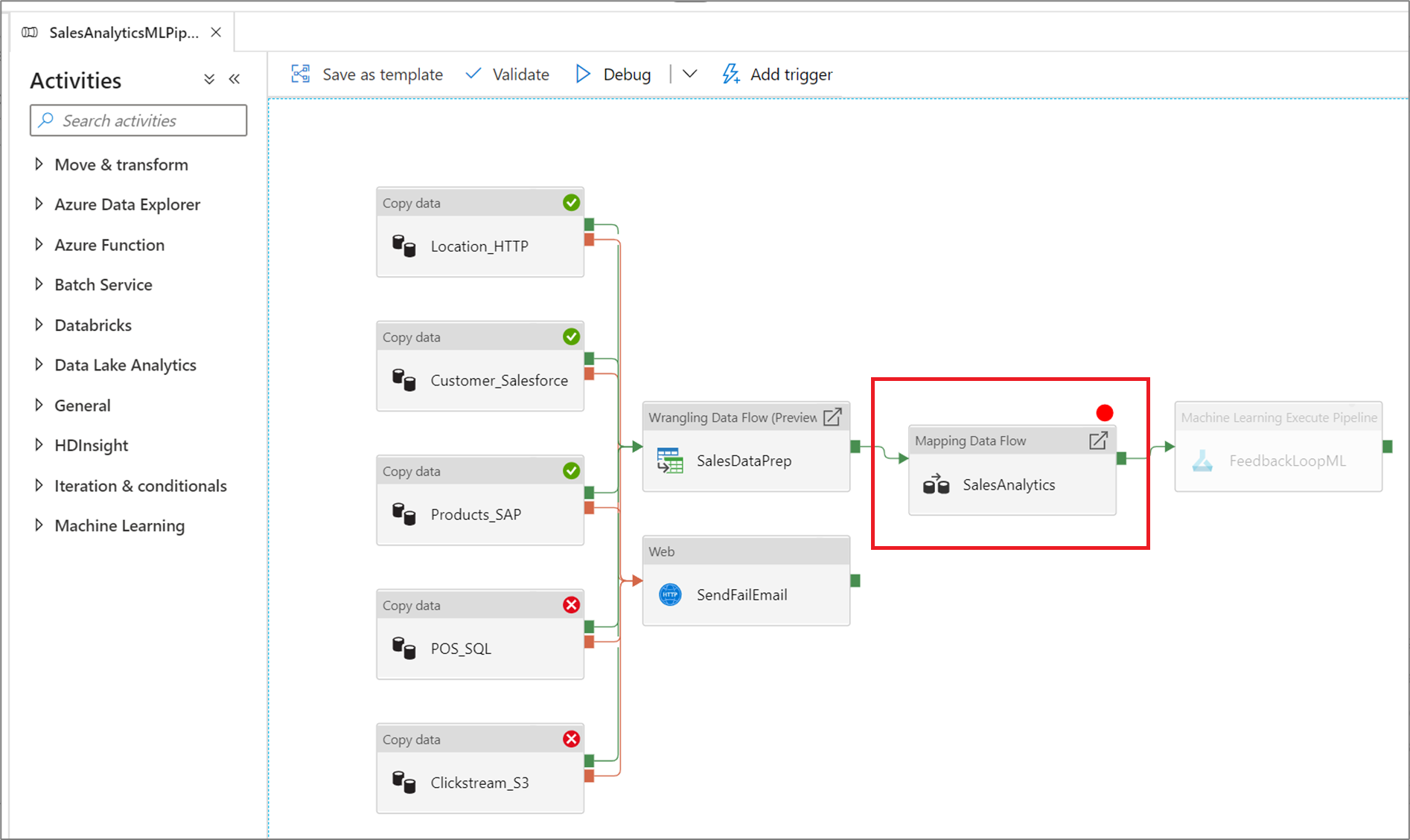
若要设置断点,请选择管道画布上的元素。 “调试至” 选项在元素的右上角显示为空心的红色圆圈。
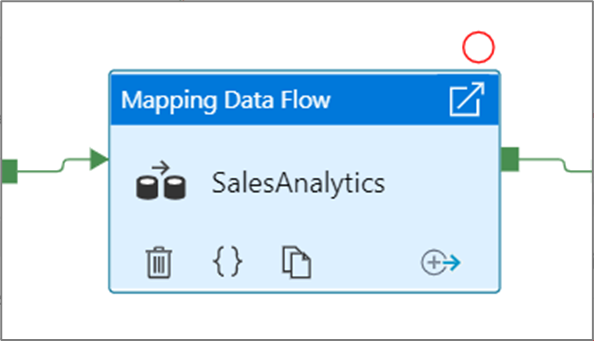
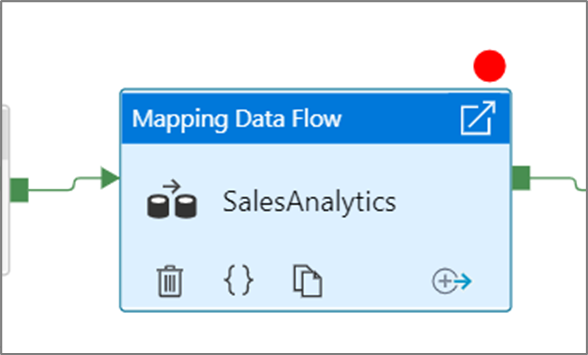
选择“调试至”选项后,它将变为实心的红色圆圈,以指示已启用断点 。
监视调试运行
运行管道调试运行时,结果将显示在管道画布的“输出”窗口中。 “输出”选项卡只包含在当前浏览器会话过程中出现的最新运行。
若要查看调试运行的历史视图或查看所有活动调试运行的列表,你可以进入“监视器”体验。
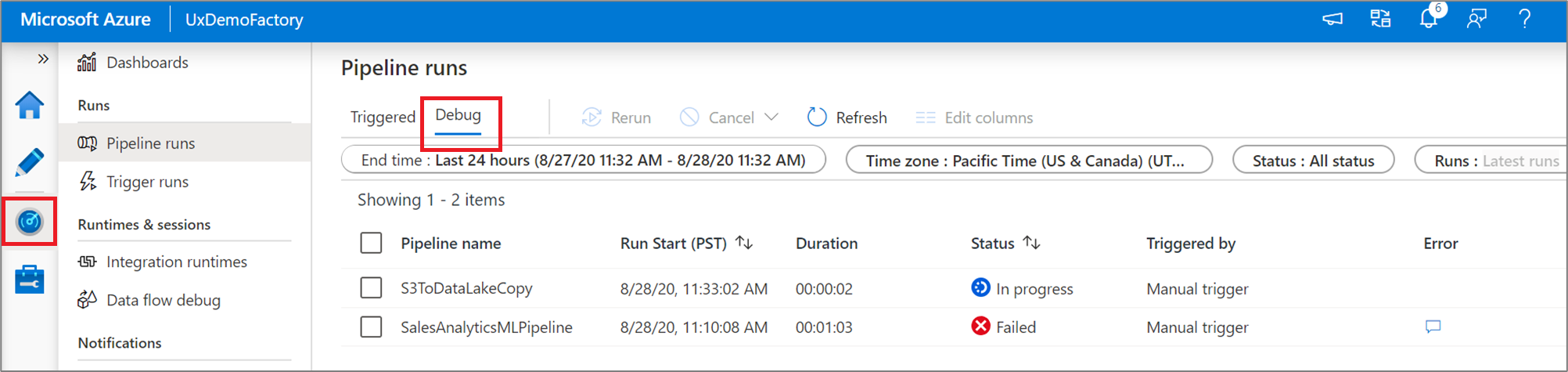
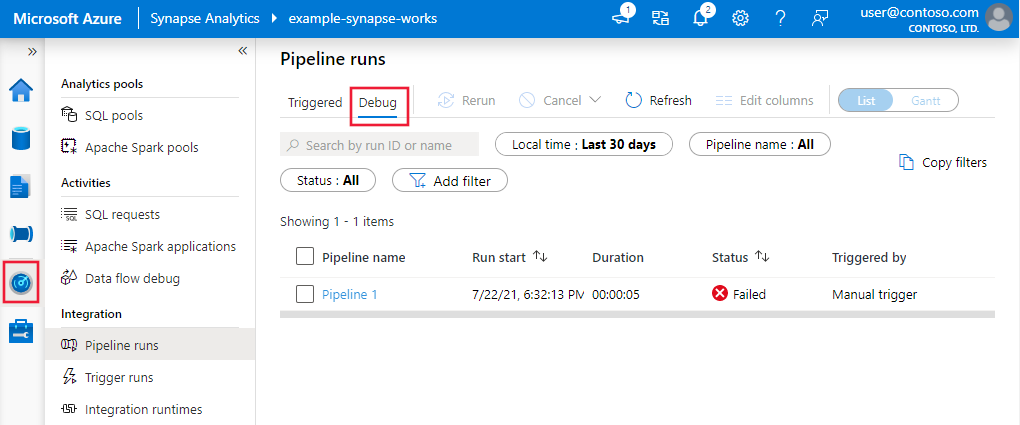
注意
此服务仅将调试运行历史记录保留 15 天。
调试映射数据流
通过映射数据流,可构建大规模运行的无代码数据转换逻辑。 生成逻辑时,可打开调试会话,使用实时 Spark 群集以交互方式处理数据。 若要了解详细信息,请阅读映射数据流调试模式。
您可以在“Monitor”界面中监控活跃的数据流调试会话。
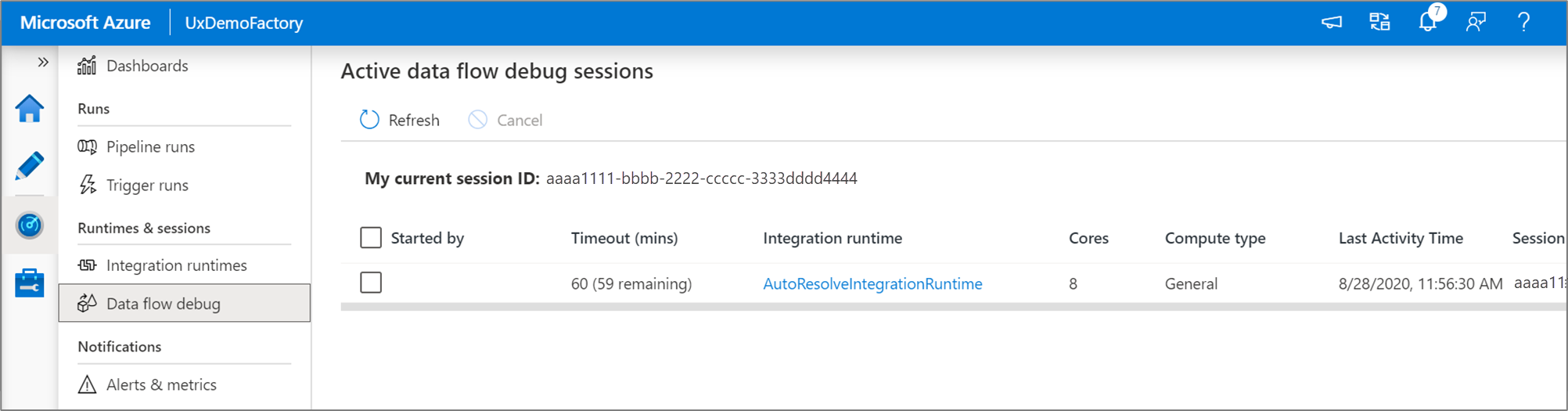
数据流设计器中的数据预览和数据流的管道调试最适合与数据的小示例一起使用。 但是,如果需要针对大量数据在管道或数据流中测试逻辑,请增大在调试会话中使用的Azure Integration Runtime的大小,其中包含更多核心和最少的常规用途计算。
调试包含数据流活动的管道
在使用数据流执行调试管道运行时,您有两个选项来选择所使用的计算资源。 你可使用现有调试群集,也可为数据流启动新的实时群集。
使用现有调试会话将大幅缩短数据流启动时间,这是因为群集已在运行,但建议不要对复杂或并行工作负载这样做,理由是一次运行多个作业时可能会失败。
如果使用活动运行时,则将使用在每个数据流活动的集成运行时中指定的设置创建一个新群集。 这样可隔离每个作业,它应该用于复杂的工作负载或性能测试。 还可以控制 Azure IR 中的 TTL,以便用于调试的群集资源仍可用于该时间段来提供其他作业请求。
注意
如果有一个管道并行执行数据流,或者需要使用大型数据集测试的数据流,请选择“使用活动运行时”,以便服务可以使用在数据流活动中选择的Integration Runtime。 这使得数据流能在多个群集上执行,还可适应并行数据流执行。