适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
数据流可在Azure 数据工厂管道和Azure Synapse Analytics管道中使用。 本文适用于映射数据流。 如果你不熟悉转换,请参阅介绍性文章: 使用映射数据流转换数据。
使用派生列转换在数据流中生成新列或修改现有字段。
创建和更新列
创建派生列时,可以生成新列或更新现有列。 在 “列 ”文本框中,输入要创建的列。 若要替代架构中的现有列,可以使用“列”下拉列表。 若要生成派生列的表达式,请在 Enter 表达式 文本框中选择。 你可以开始键入表达式或打开表达式生成器来构造逻辑。
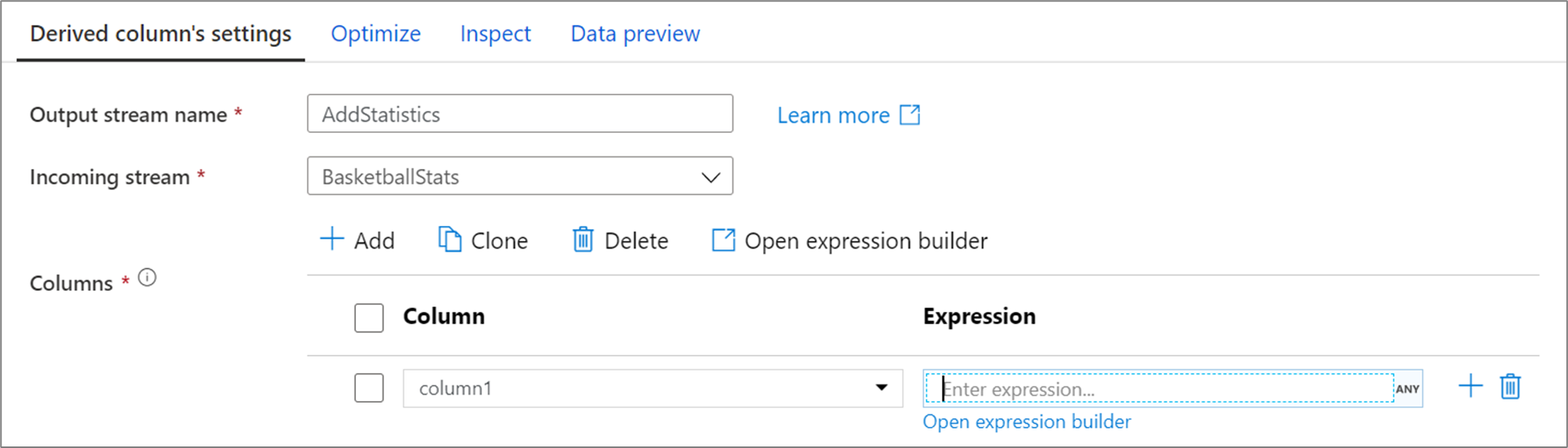
若要添加更多派生列,请选择列列表上方的 “添加 ”或现有派生列旁边的加号图标。 选择“添加列”或“添加列模式”。
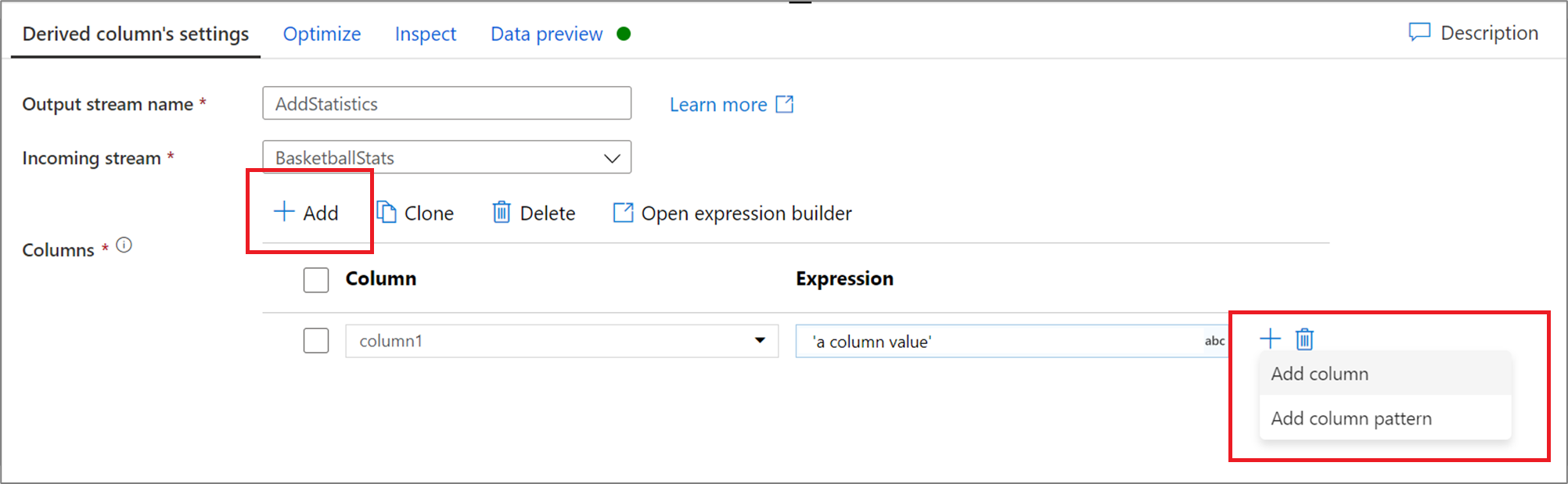
列模式
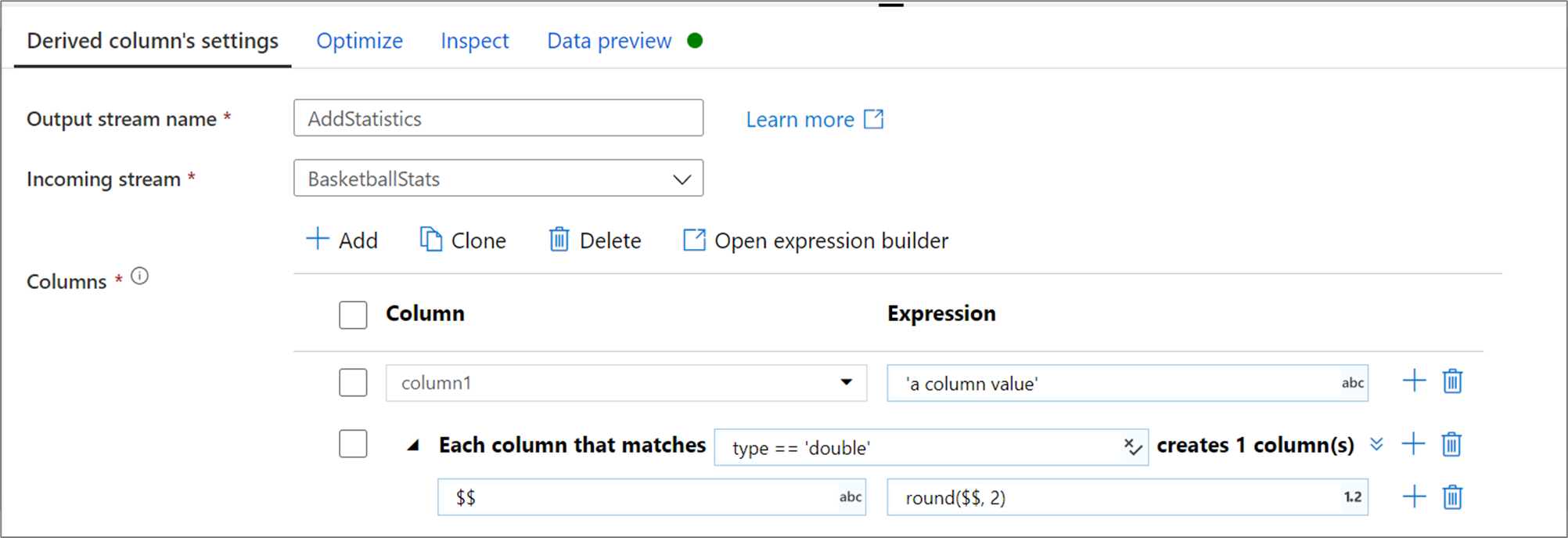
如果未显式定义架构,或者想要批量更新一组列,则需要创建列模式。 列模式让你可以使用基于列元数据的规则与列匹配,并为每个匹配列创建派生列。 如需了解更多信息,请参阅在派生列转换过程中如何生成列模式。
使用表达式生成器生成架构
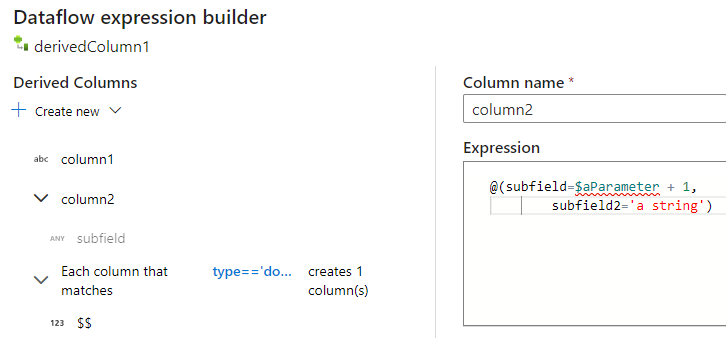
使用映射数据流表达式生成器时,可以在“派生列”部分中创建、编辑和管理派生列。 系统将列出转换过程中创建或更改的所有列。 通过选择列名称以交互方式选择要编辑的列或模式。 若要添加另一列,请选择“ 新建 ”并选择是要添加单个列还是模式。
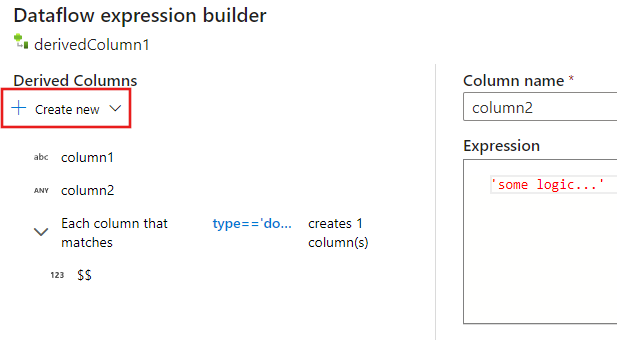
使用复杂列时,可以创建子列。 为此,请选择任何列旁边的加号图标,然后选择 “添加子列”。 有关处理数据流中的复杂类型的详细信息,请参阅映射数据流中的 JSON 处理。
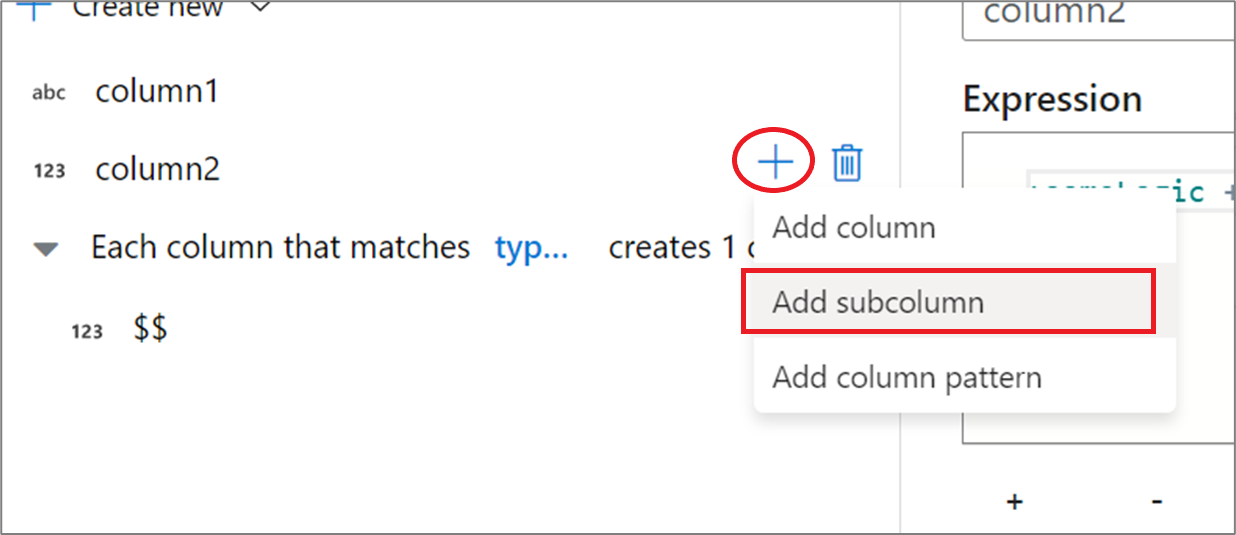
有关处理数据流中的复杂类型的详细信息,请参阅映射数据流中的 JSON 处理。
数据流脚本
语法
<incomingStream>
derive(
<columnName1> = <expression1>,
<columnName2> = <expression2>,
each(
match(matchExpression),
<metadataColumn1> = <metadataExpression1>,
<metadataColumn2> = <metadataExpression2>
)
) ~> <deriveTransformationName>
示例
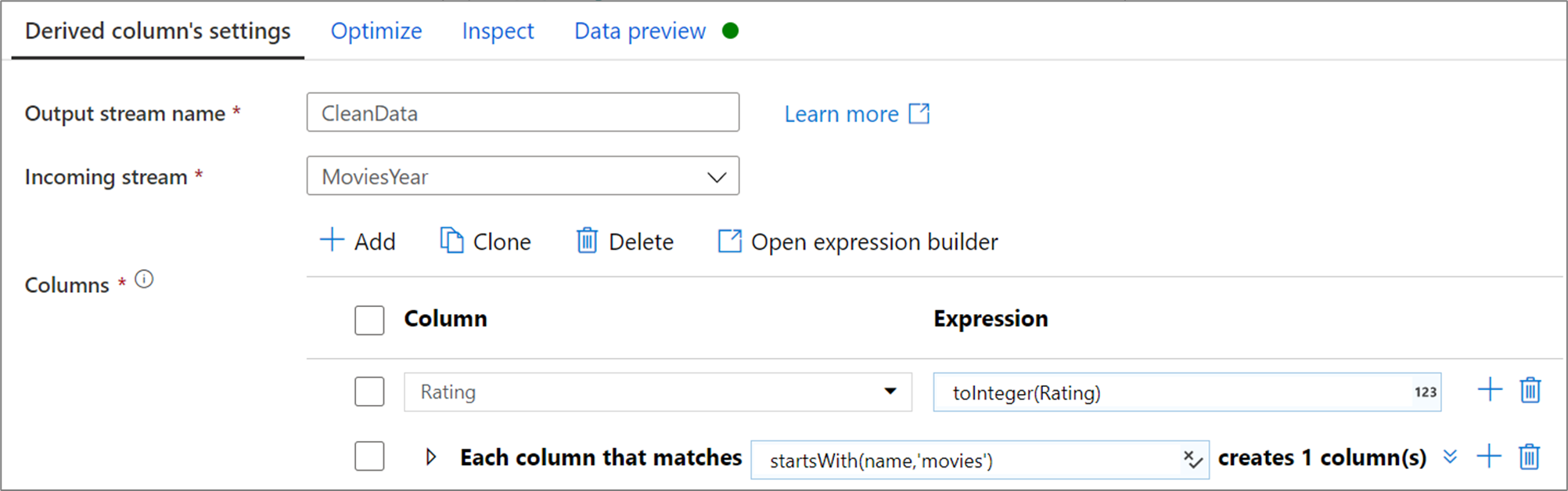
下面的示例是一个名为 CleanData 的派生列,它接受传入的流 MoviesYear 并创建两个派生列。 第一个派生列将列 Rating 替换为整数类型的 Rating 值。 第二个派生列是与名称以“movies”开头的每个列匹配的模式。 对于每个匹配列,它创建一个列,该列 movie 等于前缀为“movie_”的匹配列的值。
在 UI 中,此转换如下图所示:
此转换的数据流脚本位于下面的代码片段中:
MoviesYear derive(
Rating = toInteger(Rating),
each(
match(startsWith(name,'movies')),
'movie' = 'movie_' + toString($$)
)
) ~> CleanData
相关内容
- 详细了解 Mapping 数据流 表达式语言。