APPLIES TO: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
如果要分析 JSON 文件或以 JSON 格式写入数据,请遵循本文中的说明。
以下连接器支持 JSON 格式:
- Amazon S3
- Amazon S3 兼容存储、
- Azure Blob
- Azure Data Lake Storage Gen2
- Azure Files
- 文件系统
- FTP
- Google 云存储
- HDFS
- HTTP
- Oracle 云存储
- SFTP
数据集属性
有关可用于定义数据集的各部分和属性的完整列表,请参阅数据集一文。 本部分提供 JSON 数据集支持的属性列表。
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | 数据集的 type 属性必须设置为 Json。 | 是 |
| 位置 | 文件的位置设置。 每个基于文件的连接器在 location 下都有其自己的位置类型和支持的属性。 请在连接器文章 -> 数据集属性部分中查看详细信息。 |
是 |
| encodingName | 用于读取/写入测试文件的编码类型。 允许的值如下所示:“UTF-8”、“不带 BOM 的 UTF-8”、“UTF-16”、“UTF-16BE”、“UTF-32”、“UTF-32BE”、“US-ASCII”、“UTF-7”“BIG5”、“EUC-JP”、“EUC-KR”、“GB2312”、“GB18030”、“JOHAB”、“SHIFT-JIS”、“CP875”、“CP866”、“IBM00858”、“IBM037”、“IBM273”、“IBM437”、“IBM500”、“IBM737”、“IBM775”、“IBM850”、“IBM852”、“IBM855”、“IBM857”、“IBM860”、“IBM861”、“IBM863”、“IBM864”、“IBM865”、“IBM869”、“IBM870”、“IBM01140”、“IBM01141”、“IBM01142”、“IBM01143”、“IBM01144”、“IBM01145”、“IBM01146”、“IBM01147”、“IBM01148”、“IBM01149”、“ISO-2022-JP”、“ISO-2022-KR”、“ISO-8859-1”、“ISO-8859-2”、“ISO-8859-3”、“ISO-8859-4”、“ISO-8859-5”、“ISO-8859-6”、“ISO-8859-7”、“ISO-8859-8”、“ISO-8859-9”、“ISO-8859-13”、“ISO-8859-15”、“WINDOWS-874”、“WINDOWS-1250”、“WINDOWS-1251”、“WINDOWS-1252”、“WINDOWS-1253”、“WINDOWS-1254”、“WINDOWS-1255”、“WINDOWS-1256”、“WINDOWS-1257”、“WINDOWS-1258”。 |
否 |
| 压缩 | 用来配置文件压缩的属性组。 如果需要在活动执行期间进行压缩/解压缩,请配置此部分。 | 否 |
| 类型 (在 compression 下) |
用来读取/写入 JSON 文件的压缩编解码器。 允许的值为 bzip2、gzip、deflate、ZipDeflate、TarGzip、Tar、snappy 或 lz4 。 默认设置是不压缩。 Note当前Copy activity不支持“snappy”和“lz4”,映射数据流不支持“ZipDeflate”、“TarGzip”和“Tar”。 注意,使用复制活动解压缩 ZipDeflateTarGzipTar 文件并将其写入基于文件的接收器数据存储时,默认情况下文件将提取到 / 文件夹,对复制活动源使用 / <path specified in dataset>/<folder named as source compressed file>/ 来控制是否以文件夹结构形式保留压缩文件名 。 |
否。 |
| 水平仪 (在 compression 下) |
压缩率。 允许的值为 Optimal 或 Fastest。 - Fastest:尽快完成压缩操作,不过,无法以最佳方式压缩生成的文件。 - 最佳:以最佳方式完成压缩操作,不过,需要耗费更长的时间。 有关详细信息,请参阅 Compression Level(压缩级别)主题。 |
否 |
下面是Azure Blob Storage上的 JSON 数据集示例:
{
"name": "JSONDataset",
"properties": {
"type": "Json",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"compression": {
"type": "gzip"
}
}
}
}
Copy activity属性
有关可用于定义活动的各部分和属性的完整列表,请参阅管道一文。 本部分提供 JSON 源和接收器支持的属性列表。
若要了解如何从 JSON 文件中提取数据并将其映射到接收器数据存储/格式(反之亦然),请参阅架构映射。
以 JSON 作为源
复制活动的 *source* 部分支持以下属性。
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | 复制活动源的 type 属性必须设置为 JSONSource。 | 是 |
| formatSettings | 一组属性。 请参阅下面的“JSON 读取设置”表。 | 否 |
| storeSettings | 有关如何从数据存储读取数据的一组属性。 每个基于文件的连接器在 storeSettings 下都有其自己支持的读取设置。
请参阅连接器文章 -> Copy activity properties section中的详细信息。 |
否 |
下支持的“JSON 读取设置”:
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | formatSettings 的 type 必须设置为“JsonReadSettings”。 | 是 |
| compressionProperties | 一组属性,指示如何为给定的压缩编解码器解压缩数据。 | 否 |
| preserveZipFileNameAsFolder (在 compressionProperties->type 下为 ZipDeflateReadSettings) |
当输入数据集配置了 ZipDeflate 压缩时适用。 指示是否在复制过程中以文件夹结构形式保留源 zip 文件名。 - 如果设置为“true(默认)”,服务会将解压缩的文件写入 。 - 如果设置为“false”,服务会将解压缩的文件直接写入 。 请确保不同的源 zip 文件中没有重复的文件名,以避免产生冲突或出现意外行为。 |
否 |
| preserveCompressionFileNameAsFolder (在 compressionProperties->type 下为 TarGZipReadSettings 或 TarReadSettings) |
当输入数据集配置了 TarGzipTar 压缩时适用 。 指示是否在复制过程中以文件夹结构形式保留源压缩文件名。 - 如果设置为“true(默认)”,服务会将解压缩文件写入 。 - 如果设置为“false”,服务会将解压文件直接写入 。 请确保不同的源文件中没有重复的文件名,以避免产生冲突或出现意外行为。 |
否 |
JSON 作为接收器
复制活动的 *sink* 部分支持以下属性。
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | 复制活动源的 type 属性必须设置为 JSONSink。 | 是 |
| formatSettings | 一组属性。 请参阅下面的“JSON 写入设置”表。 | 否 |
| storeSettings | 有关如何将数据写入到数据存储的一组属性。 每个基于文件的连接器在 storeSettings 下都有其自身支持的写入设置。
请参阅连接器文章 -> Copy activity properties section中的详细信息。 |
否 |
下支持的 formatSettings:
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | formatSettings 的类型必须设置为 JsonWriteSettings。 | 是 |
| filePattern | 指示每个 JSON 文件中存储的数据模式。 允许的值为:setOfObjects (JSON Lines) 和 arrayOfObjects。 默认值为 setOfObjects。 请参阅 JSON 文件模式部分,详细了解这些模式。 | 否 |
JSON 文件模式
从 JSON 文件复制数据时,复制活动可自动检测并分析以下 JSON 文件模式。 将数据写入 JSON 文件时,可以在复制活动接收器上配置文件模式。
类型 I:setOfObjects
每个文件都包含单一对象、JSON Lines 或串联的对象。
单一对象 JSON 示例
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }JSON Lines(接收器的默认值)
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"} {"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"} {"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}串连的 JSON 示例
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" } { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" } { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" }
类型 II:arrayOfObjects
每个文件包含对象的数组。
[ { "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }, { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" }, { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" } ]
映射数据流属性
在映射数据流中,可以读取和写入以下数据存储中的 JSON 格式:Azure Blob Storage、Azure Data Lake Storage Gen2 和 SFTP。
源属性
下表列出了 json 源支持的属性。 你可以在“源选项”选项卡中编辑这些属性。
| 名称 | 描述 | 必需 | 允许的值 | 数据流脚本属性 |
|---|---|---|---|---|
| 通配符路径 | 将处理与通配符路径匹配的所有文件。 重写数据集中设置的文件夹和文件路径。 | 否 | String[] | wildcardPaths |
| 分区根路径 | 对于已分区的文件数据,可以输入分区根路径,以便将已分区的文件夹读取为列 | 否 | 字符串 | partitionRootPath |
| 文件列表 | 源是否指向某个列出待处理文件的文本文件 | 否 |
true 或 false |
fileList |
| 用于存储文件名的列 | 使用源文件名称和路径创建新列 | 否 | 字符串 | rowUrlColumn |
| 完成后 | 在处理后删除或移动文件。 文件路径从容器根开始 | 否 | 删除:true 或 false Move: ['<from>', '<to>'] |
purgeFiles moveFiles |
| 按上次修改时间筛选 | 选择根据上次更改时间筛选文件 | 否 | 时间戳 | modifiedAfter modifiedBefore |
| 单个文档 | 映射数据流从每个文件中读取一个 JSON 文档 | 否 |
true 或 false |
singleDocument |
| 不带引号的列名称 | 如果选择了“不带引号的列名称”,则映射数据流会读取不在引号中的 JSON 列。 | 否 |
true 或 false |
unquotedColumnNames |
| 具有注释 | 如果 JSON 数据具有 C 或 C++ 样式的注释,请选择“具有注释” | 否 |
true 或 false |
asComments |
| 带单引号 | 读取不在引号中的 JSON 列 | 否 |
true 或 false |
singleQuoted |
| 使用反斜杠转义 | 如果使用反斜杠对 JSON 数据中的字符进行转义,请选择“使用反斜杠转义” | 否 |
true 或 false |
backslashEscape |
| 允许找不到文件 | 如果为 true,则找不到文件时不会引发错误 | 否 |
true 或 false |
ignoreNoFilesFound |
内联数据集
映射数据流支持将“内联数据集”作为定义源和接收器的选项。 内联 JSON 数据集直接在源和接收器转换中定义,并且不会在定义的数据流外部共享。 该数据集对直接在数据流中参数化数据集属性非常有用,并且可以从共享 ADF 数据集的性能改进中获益。
读取大量源文件夹和文件时,可以通过在“投影 | 架构”选项对话框中设置选项“用户投影架构”来提升数据流文件发现的性能。 此选项会关闭 ADF 的默认架构自动发现,并将极大地提升文件发现的性能。 在设置此选项前,请务必导入 JSON 投影,以便 ADF 具有用于投影的现有架构。 此选项不适用于架构偏差。
源格式选项
在数据流中使用 JSON 数据集作为源时,你可以设置五个额外的设置。 这些设置可以在“源选项”选项卡中的“JSON 设置”可折叠部分下找到。对于“文档格式”设置,可以选择“单个文档”、“每行文档”和“文档数组”类型之一。
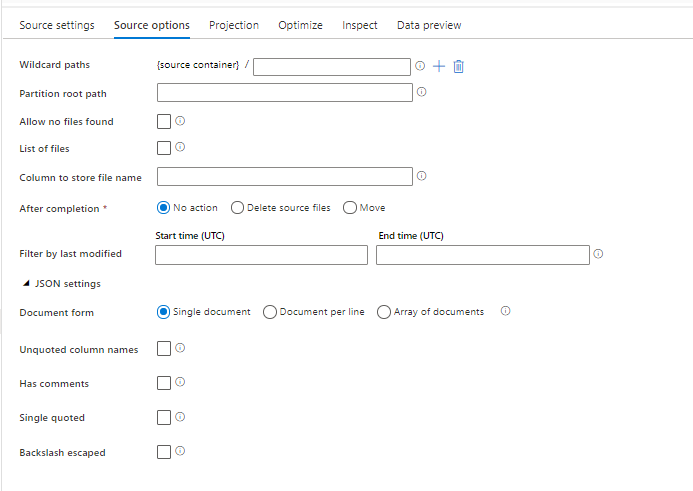
默认
默认情况下,将使用以下格式读取 JSON 数据。
{ "json": "record 1" }
{ "json": "record 2" }
{ "json": "record 3" }
单个文档
如果选择了“单个文档”,则映射数据流会从每个文件中读取一个 JSON 文档。
File1.json
{
"json": "record 1"
}
File2.json
{
"json": "record 2"
}
File3.json
{
"json": "record 3"
}
如果选择了“每行一个文档”,则映射数据流会从文件中的每行读取一个 JSON 文档。
File1.json
{"json": "record 1"}
File2.json
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"}
{"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"}
File3.json
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"}
{"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"}
{"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}
如果选择了“文档数组”,则映射数据流会从文件中读取一个文档数组。
File.json
[
{
"time": "2015-04-29T07:12:20.9100000Z",
"callingimsi": "466920403025604",
"callingnum1": "678948008",
"callingnum2": "567834760",
"switch1": "China",
"switch2": "Germany"
},
{
"time": "2015-04-29T07:13:21.0220000Z",
"callingimsi": "466922202613463",
"callingnum1": "123436380",
"callingnum2": "789037573",
"switch1": "US",
"switch2": "UK"
},
{
"time": "2015-04-29T07:13:21.4370000Z",
"callingimsi": "466923101048691",
"callingnum1": "678901578",
"callingnum2": "345626404",
"switch1": "Germany",
"switch2": "UK"
}
]
注意
如果预览你的 JSON 数据时数据流引发了“corrupt_record”错误,则你的数据可能在 JSON 文件中包含单个文档。 设置“单个文档”应当能够清除该错误。
不带引号的列名称
如果选择了“不带引号的列名称”,则映射数据流会读取不在引号中的 JSON 列。
{ json: "record 1" }
{ json: "record 2" }
{ json: "record 3" }
具有注释
如果 JSON 数据具有 C 或 C++ 样式的注释,请选择“具有注释”。
{ "json": /** comment **/ "record 1" }
{ "json": "record 2" }
{ /** comment **/ "json": "record 3" }
带单引号
如果 JSON 字段和值使用单引号而非双引号,请选择“带单引号”。
{ 'json': 'record 1' }
{ 'json': 'record 2' }
{ 'json': 'record 3' }
使用反斜杠转义
如果使用反斜杠对 JSON 数据中的字符进行转义,请选择“使用反斜杠转义”。
{ "json": "record 1" }
{ "json": "\} \" \' \\ \n \\n record 2" }
{ "json": "record 3" }
接收器属性
下表列出了 json 接收器支持的属性。 可以在“设置”选项卡中编辑这些属性。
| 名称 | 描述 | 必需 | 允许的值 | 数据流脚本属性 |
|---|---|---|---|---|
| 清除文件夹 | 如果在写入前目标文件夹已被清除 | 否 |
true 或 false |
截断 |
| 文件名选项 | 写入的数据的命名格式。 默认情况下,每个分区有一个 part-#####-tid-<guid> 格式的文件 |
否 | 模式:字符串 每分区:String[] 作为列中的数据:字符串 输出到单个文件: ['<fileName>'] |
filePattern partitionFileNames rowUrlColumn partitionFileNames |
在派生列中创建 JSON 结构
你可以通过派生列表达式生成器将复杂的列添加到数据流中。 在派生列转换中,添加一个新列并通过单击蓝色框打开表达式生成器。 若要使列成为复杂列,可以手动输入 JSON 结构,或者使用 UX 以交互方式添加子列。
使用表达式生成器 UX
在输出架构侧窗格中,将鼠标指针悬停在某个列上,并单击加号图标。 选择“添加子列”,使列成为复杂类型。
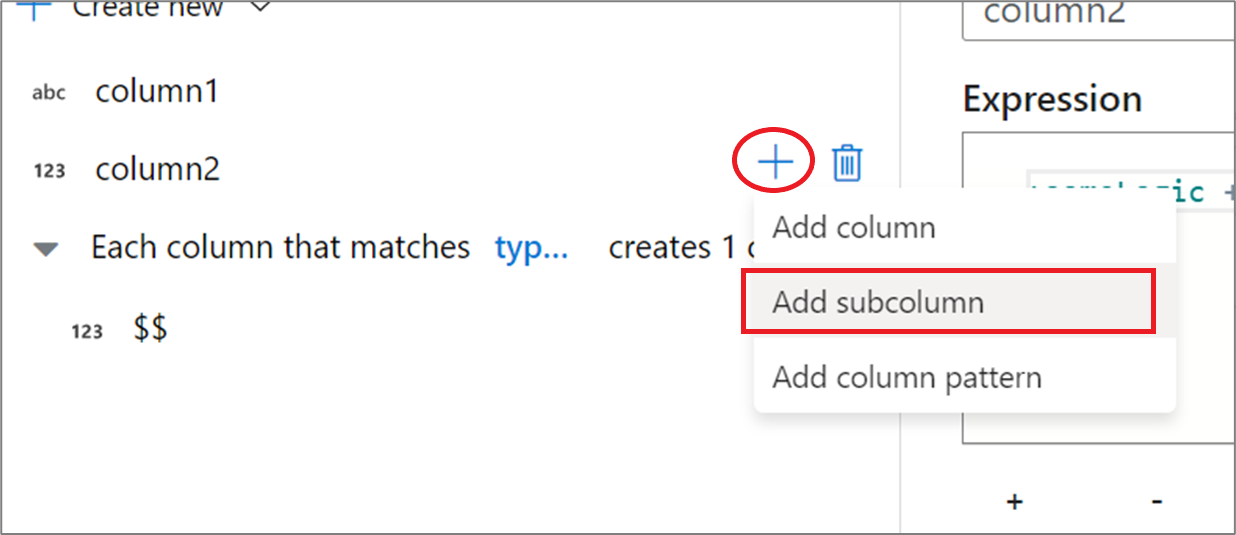
你可以通过相同的方式添加更多的列和子列。 对于每个非复杂字段,可以在右侧的表达式编辑器中添加表达式。
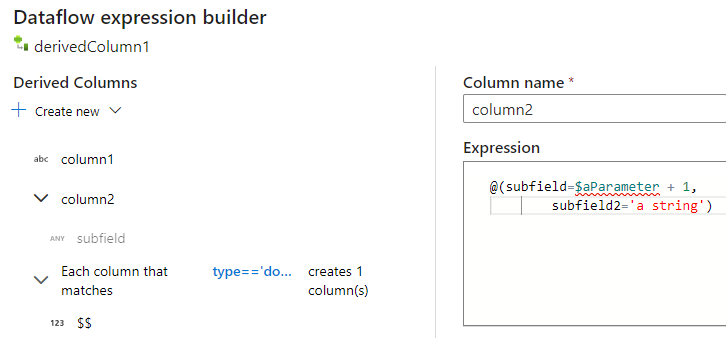
手动输入 JSON 结构
若要手动添加 JSON 结构,请添加一个新列,然后在编辑器中输入表达式。 表达式采用以下常规格式:
@(
field1=0,
field2=@(
field1=0
)
)
如果为名为“complexColumn”的列输入了此表达式,则会将其作为以下 JSON 写入到接收器:
{
"complexColumn": {
"field1": 0,
"field2": {
"field1": 0
}
}
}
完整分层定义的示例手动脚本
@(
title=Title,
firstName=FirstName,
middleName=MiddleName,
lastName=LastName,
suffix=Suffix,
contactDetails=@(
email=EmailAddress,
phone=Phone
),
address=@(
line1=AddressLine1,
line2=AddressLine2,
city=City,
state=StateProvince,
country=CountryRegion,
postCode=PostalCode
),
ids=[
toString(CustomerID), toString(AddressID), rowguid
]
)
相关连接器和格式
下面是一些与 JSON 格式相关的常见连接器和格式: