APPLIES TO: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
数据流可在Azure Data Factory管道和Azure Synapse Analytics管道中使用。 本文适用于映射数据流。 如果你不熟悉转换,请参阅介绍性文章: 使用映射数据流转换数据。
存在转换是一个行筛选转换,用于检查数据是否存在于另一个源或流中。 输出流包括左侧流中存在或不存在于右侧流中的所有行。 存在转换类似于 SQL WHERE EXISTS 和 SQL WHERE NOT EXISTS。
Configuration
- 在“右侧流”下拉菜单中选择要检查是否存在的数据流。
- 在“存在类型”设置中指定要查找的数据是否存在。
- 选择是否需要“自定义表达式”。
- 选择要作为存在条件进行比较的键列。 默认情况下,数据流在每个流中的一列之间查找相等性。 若要通过计算值进行比较,请将鼠标悬停在列下拉菜单上,然后选择“计算列”。
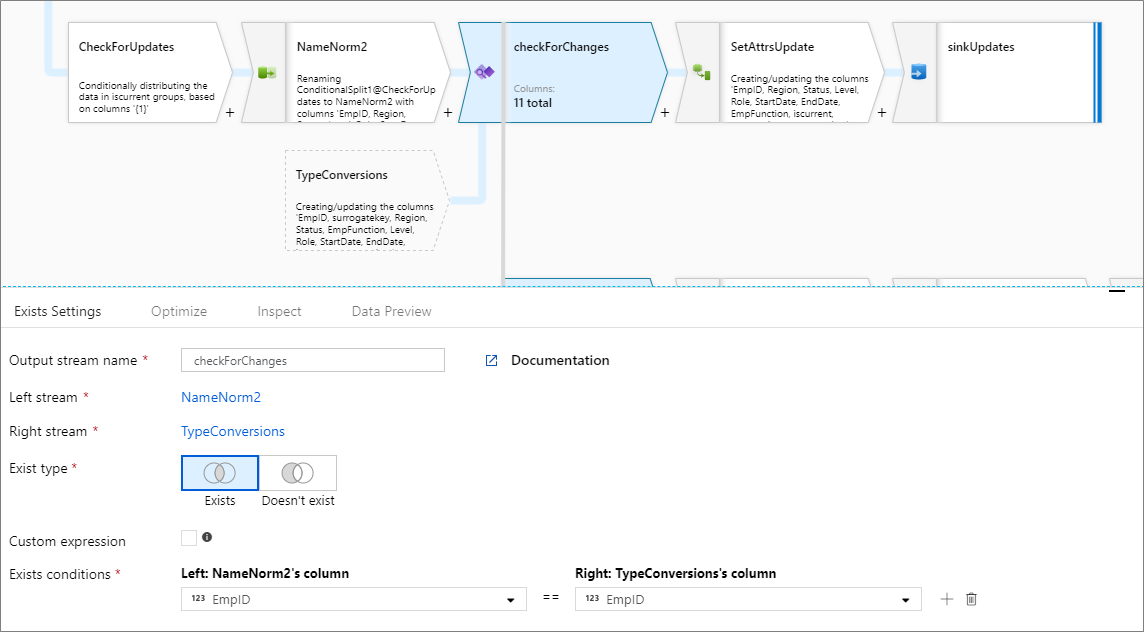
多个存在条件
若要比较每个流中的多列,请通过单击现有行旁边的加号图标来添加新的存在条件。 每个附加条件都由一个“and”语句连接。 比较两列与以下表达式相同:
source1@column1 == source2@column1 && source1@column2 == source2@column2
自定义表达式
若要创建包含除“and”与“equals to”之外的其他运算符的自由格式表达式,请选择“自定义表达式”字段。 单击蓝色框,通过数据流表达式生成器输入自定义表达式。
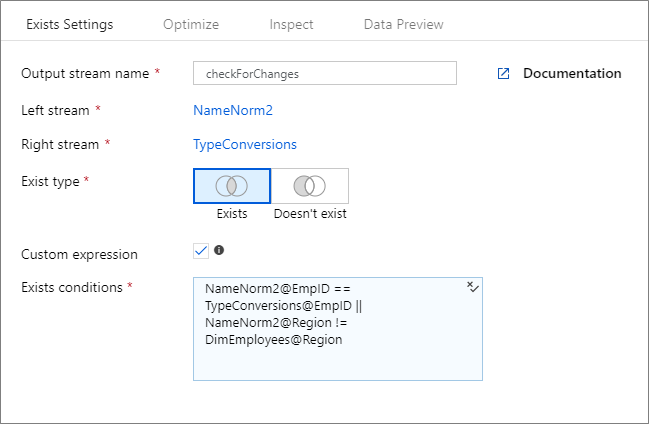
如果通过架构偏差使用列“后期绑定”在数据流中构建动态模式,则可以借助 byName() 表达式函数使用存在转换,而无需对列名称进行硬编码(例如早期绑定)。 示例: toString(byName('ProductNumber','source1')) == toString(byName('ProductNumber','source2'))
广播优化
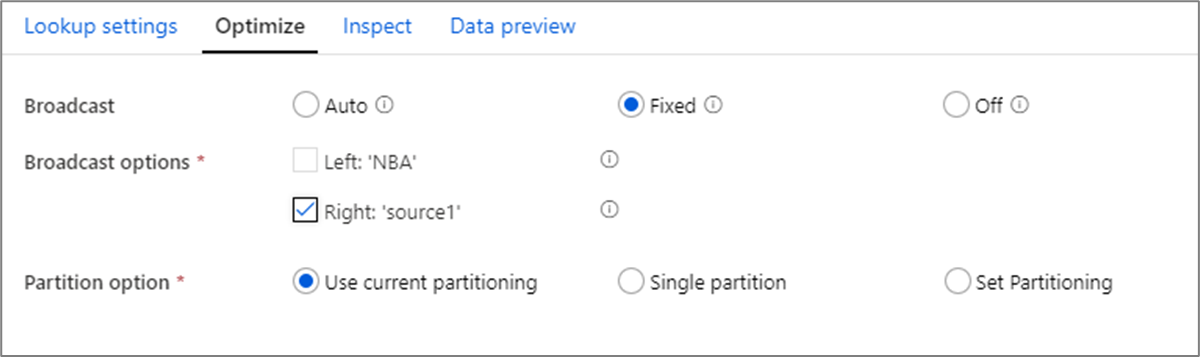
在联接、查找和存在转换中,如果工作器节点内存可容纳一个数据流或同时容纳两个数据流,则可以通过启用“广播”来优化性能。 默认情况下,Spark 引擎将自动决定是否广播一侧。 若要手动选择要广播的一侧,请选择“固定”。
建议不要通过“关闭”选项来禁用广播,除非联接遇到超时错误。
数据流脚本
语法
<leftStream>, <rightStream>
exists(
<conditionalExpression>,
negate: { true | false },
broadcast: { 'auto' | 'left' | 'right' | 'both' | 'off' }
) ~> <existsTransformationName>
示例
下面的示例是一个名为 checkForChanges 的存在转换,它采用左侧流 NameNorm2 和右侧流 TypeConversions。 存在条件为表达式 NameNorm2@EmpID == TypeConversions@EmpID && NameNorm2@Region == DimEmployees@Region,如果每个流中的 EMPID 和 Region 列均匹配,则返回 true。 由于我们将检查是否存在,negate 为 false。 我们未在“优化”选项卡中启用任何广播,因此 broadcast 的值为 'none'。
在 UI 体验中,此转换如下图所示:
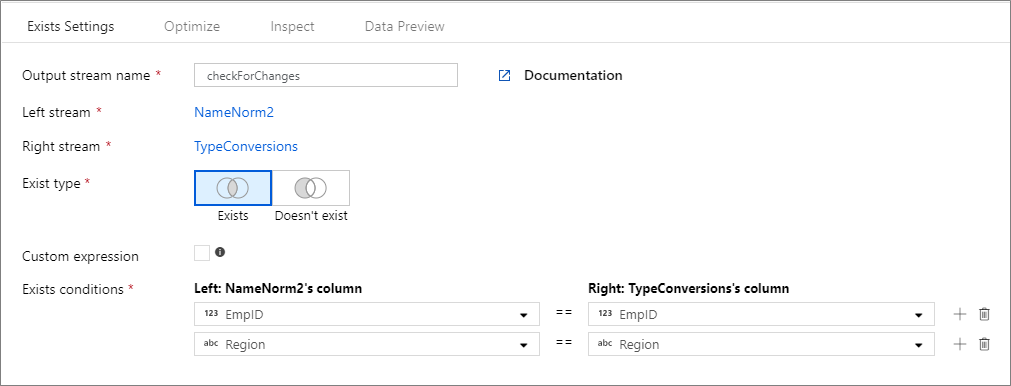
此转换的数据流脚本位于下面的代码片段中:
NameNorm2, TypeConversions
exists(
NameNorm2@EmpID == TypeConversions@EmpID && NameNorm2@Region == DimEmployees@Region,
negate:false,
broadcast: 'auto'
) ~> checkForChanges