适用于: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
数据流可在Azure Data Factory管道和Azure Synapse Analytics管道中使用。 本文适用于映射数据流。 如果你不熟悉转换,请参阅介绍性文章: 使用映射数据流转换数据。
在数据流中使用查找转换以引用来自其他数据源的数据。 查找转换会将匹配数据中的列追加到源数据中。
查找转换类似于左外部联接。 主流中的所有行都将存在于包含查找流中其他列的输出流中。
配置
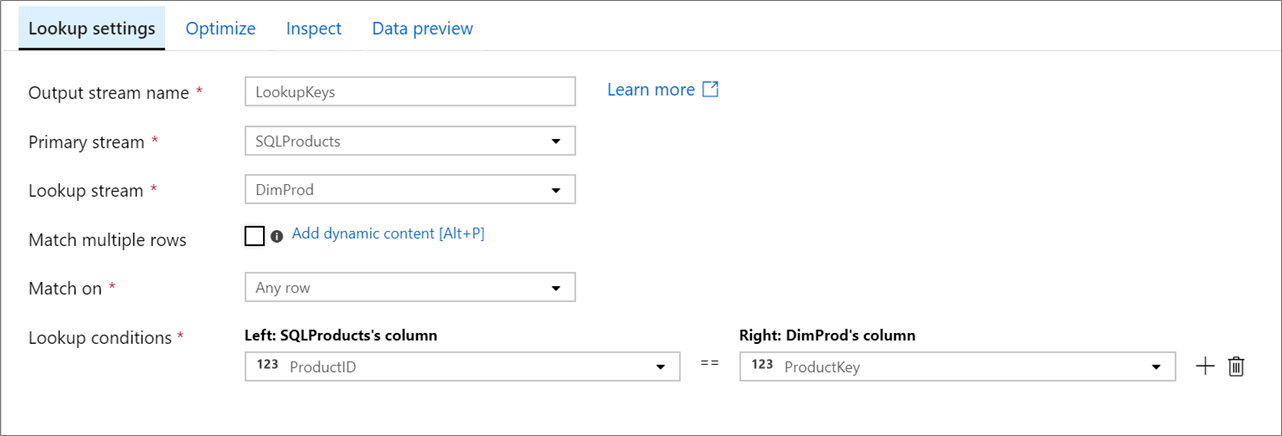
主要数据流: 传入的数据流。 此流等效于联接的左侧。
查找流:追加到主流中的数据。 哪些数据被添加由查找条件决定。 此流等效于联接的右侧。
匹配多行:如果启用,主流中具有多个匹配项的行将返回多行。 否则,将根据“匹配”条件仅返回单个行。
匹配条件:仅当未选择“匹配多行”时才可见。 选择是否匹配任意行、首次匹配或最后匹配。 建议选择任意行,因为它执行速度最快。 如果选择了首行或末行,则需要指定排序条件。
查找条件: 选择要匹配的列。 如果满足相等条件,则将这些行视为匹配项。 悬停鼠标并选择“计算列”,以使用数据流表达式语言提取值。
输出数据中包含两个流中的所有列。 若要删除重复列或不需要的列,请在查找转换后添加选择转换。 还可以在接收器转换中删除或重命名列。
非等值联接
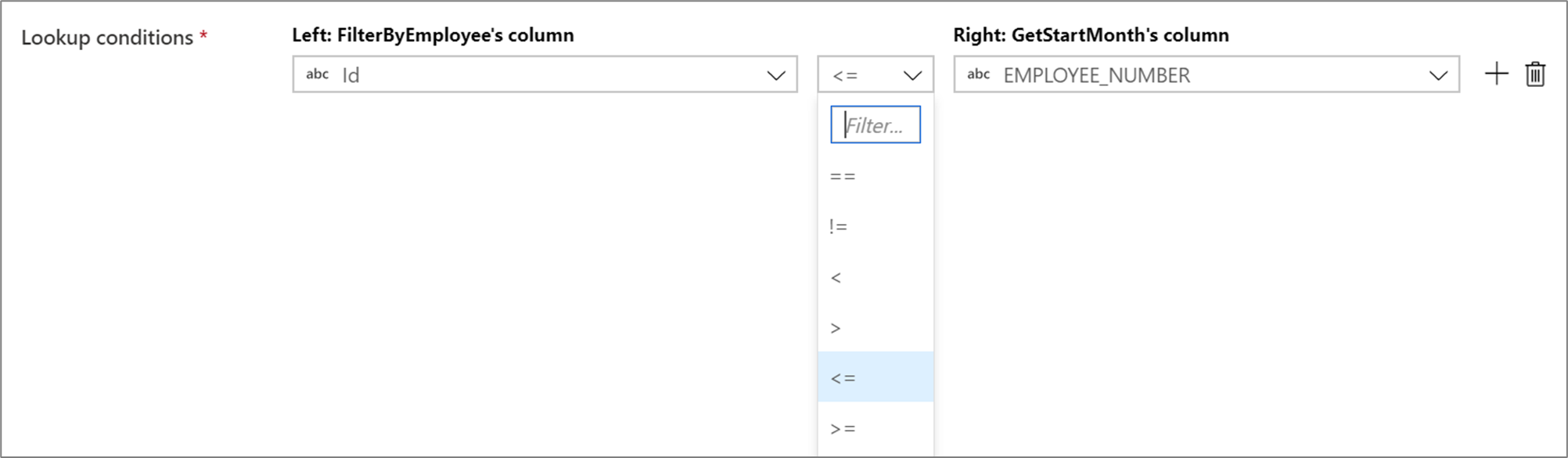
若要在查找条件中使用条件运算符,例如不等于 (!=) 或大于 (>),请在两列之间更改运算符下拉菜单。 非等值联接要求使用“优化”选项卡中的“固定”广播来广播两个流中的至少一个流。
分析匹配的行
查找转换后,可以使用函数 isMatch() 来查看查找结果是否匹配每一行。
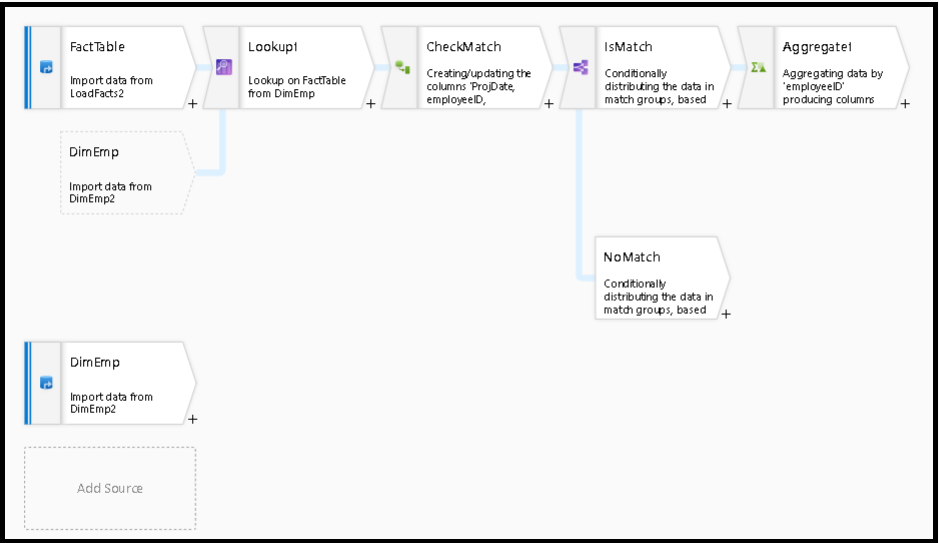
此模式的一个示例是使用有条件拆分转换来拆分 isMatch() 函数。 在上面的示例中,匹配行经过最顶部的流,而不匹配的行则流过 NoMatch 流。
测试查找条件
在调试模式下使用数据预览测试查找转换时,请使用一小组已知数据。 对大型数据集中的行进行采样时,无法预测将读取哪些行和键进行测试。 结果是非确定性的,这意味着你的联接条件可能不会返回任何匹配项。
广播优化
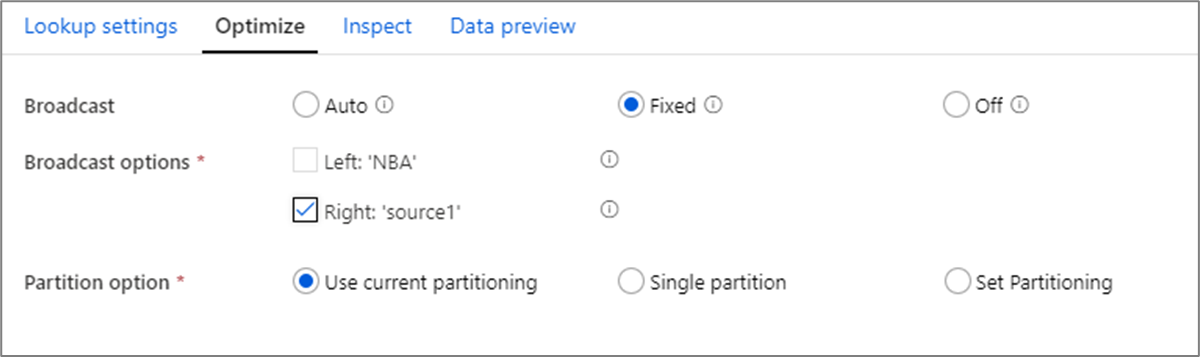
在联接、查找和存在转换中,如果工作器节点内存可容纳一个数据流或同时容纳两个数据流,则可以通过启用“广播”来优化性能。 默认情况下,Spark 引擎将自动决定是否广播一侧。 若要手动选择要广播的一侧,请选择“固定”。
建议不要通过“关闭”选项来禁用广播,除非联接遇到超时错误。
缓存查找
如果要在同一源上执行多次小范围查找,那么相比于查找转换,缓存的接收器和查找可能是一个更佳用例。 缓存接收器的常见示例在以下情况中可能更佳:查找数据存储中的最大值,将错误代码与错误消息数据库进行匹配。 有关详细信息,请了解缓存接收器和缓存查找。
数据流脚本
语法
<leftStream>, <rightStream>
lookup(
<lookupConditionExpression>,
multiple: { true | false },
pickup: { 'first' | 'last' | 'any' }, ## Only required if false is selected for multiple
{ desc | asc }( <sortColumn>, { true | false }), ## Only required if 'first' or 'last' is selected. true/false determines whether to put nulls first
broadcast: { 'auto' | 'left' | 'right' | 'both' | 'off' }
) ~> <lookupTransformationName>
示例
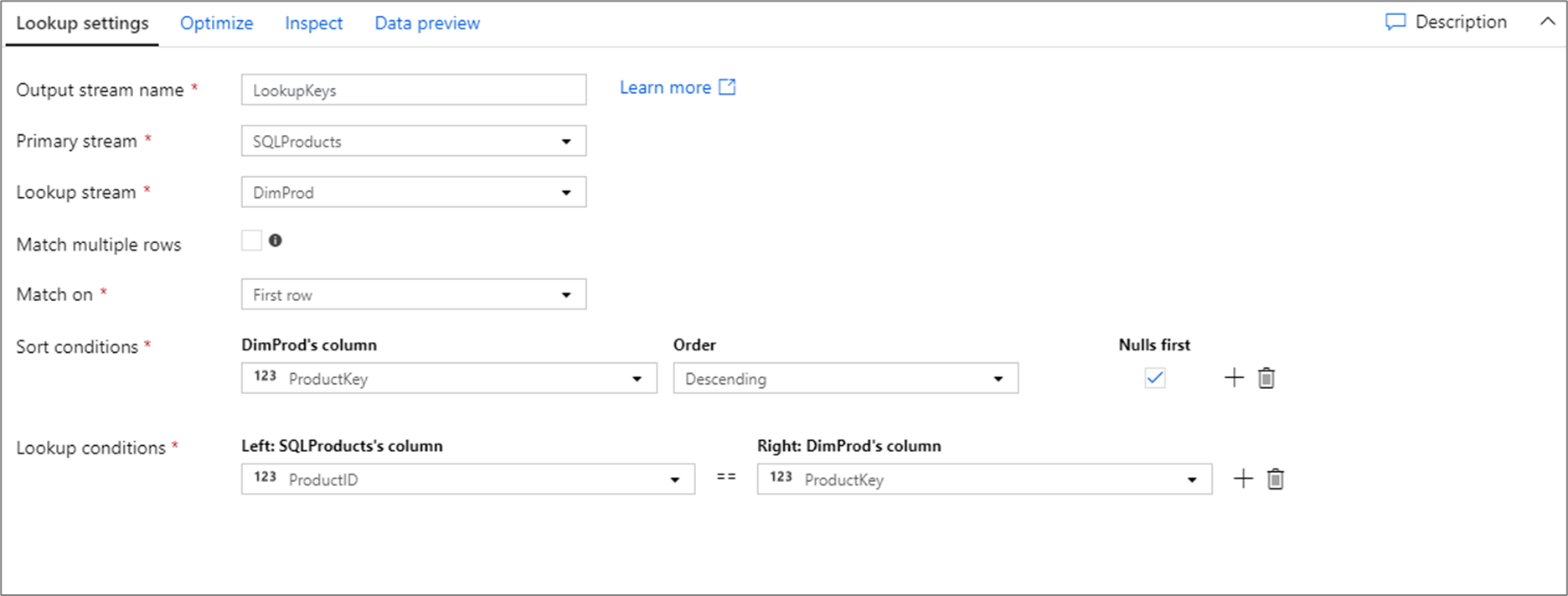
以上查找配置的数据流脚本位于下面的代码片段中。
SQLProducts, DimProd lookup(ProductID == ProductKey,
multiple: false,
pickup: 'first',
asc(ProductKey, true),
broadcast: 'auto')~> LookupKeys