适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
数据流在 Azure 数据工厂管道和 Azure Synapse Analytics 管道中都可用。 本文适用于映射数据流。 如果你不熟悉转换,请参阅介绍性文章: 使用映射数据流转换数据。
条件拆分转换依据匹配条件将数据行路由到不同的数据流。 有条件拆分转换类似于编程语言中的 CASE 决策结构。 转换计算表达式,并根据结果将数据行定向到指定的流。
配置
“拆分依据”设置可确定数据行是流向第一个匹配的流还是流向所有匹配的流。
使用数据流表达式生成器为拆分条件输入表达式。 若要添加新条件,请单击现有行中的加号图标。 还可以为与任何条件都不匹配的行添加默认流。
数据流脚本
语法
<incomingStream>
split(
<conditionalExpression1>
<conditionalExpression2>
...
disjoint: {true | false}
) ~> <splitTx>@(stream1, stream2, ..., <defaultStream>)
示例
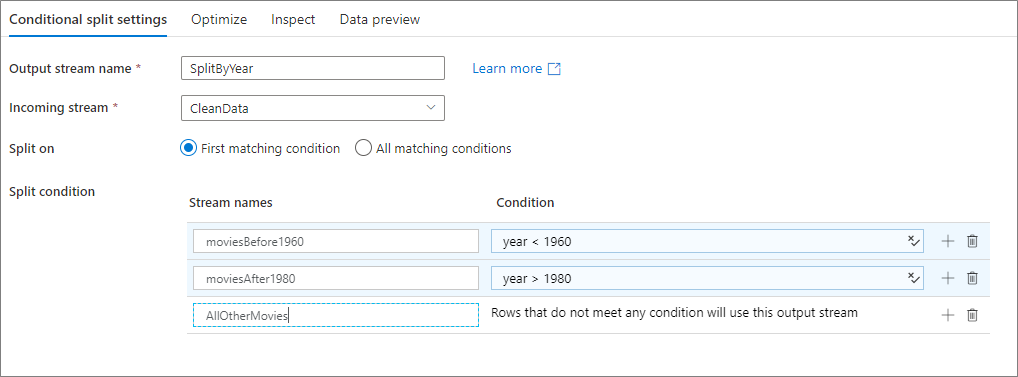
下面的示例是一个名为 SplitByYear 的有条件拆分转换,它采用传入流 CleanData。 此转换有两个拆分条件,即 year < 1960 和 year > 1980。
disjoint 为 false,因为数据会流向第一个匹配条件而不是所有匹配条件。 每个匹配第一个条件的行都会转到输出流 moviesBefore1960。 与第二个条件匹配的所有剩余行都会转到输出流 moviesAFter1980。 所有其他行都转到默认流 AllOtherMovies。
在服务器 UI 中,此转换如下图所示:
此转换的数据流脚本位于下面的代码片段中:
CleanData
split(
year < 1960,
year > 1980,
disjoint: false
) ~> SplitByYear@(moviesBefore1960, moviesAfter1980, AllOtherMovies)