本文探讨了 Azure 数据工厂 (ADF) 中与映射数据流的连接器和格式相关的故障排除方法。
Azure Blob 存储
存储帐户类型(常规用途 v1)不支持服务主体和 MI 身份验证
现象
在数据流中,如果将 Azure Blob 存储(常规用途 v1)与服务主体或 MI 身份验证一起使用,则可能会遇到以下错误消息:
com.microsoft.dataflow.broker.InvalidOperationException: ServicePrincipal and MI auth are not supported if blob storage kind is Storage (general purpose v1)
原因
在数据流中使用 Azure Blob 链接服务时,如果帐户类型为空或“存储”,则不支持托管标识或服务主体身份验证。 此情况如下图 1 和图 2 所示。
图 1: Azure Blob 存储链接服务中的帐户类型
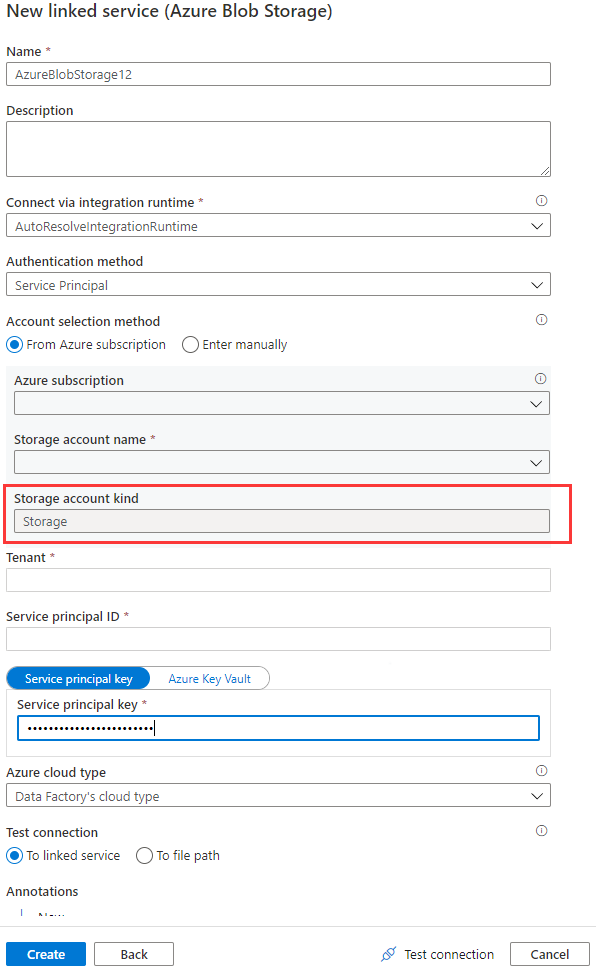
图 2:存储帐户页

建议
若要解决此问题,请参考以下建议:
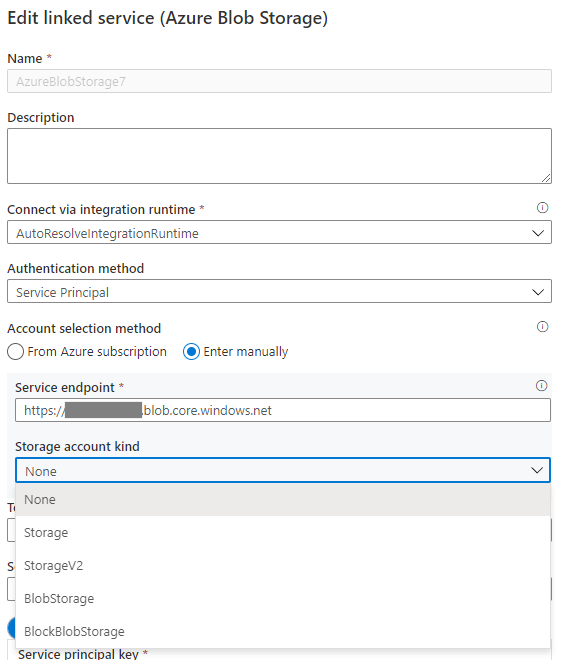
如果 Azure Blob 链接服务中的存储帐户类型为“无”,请指定适当的帐户类型,并参考下面的图 3 来完成此操作。 此外,请参阅图 2 以获取存储帐户类型,并检查和确认帐户类型不是“存储”(常规用途 v1)。
图 3:在 Azure Blob 存储链接服务中指定存储帐户类型
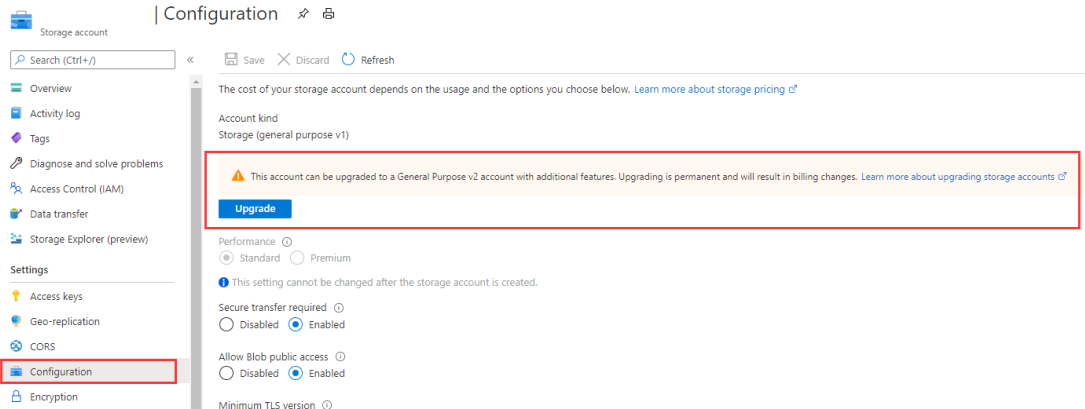
如果帐户类型为“存储”(常规用途 v1),请将存储帐户升级为常规用途 v2 或选择其他身份验证。
图 4:将存储帐户升级为常规用途 v2

Azure Cosmos DB 和 JSON 格式
支持源中的自定义架构
现象
如果要使用 ADF 数据流将数据从 Azure Cosmos DB/JSON 移动或传输到其他数据存储,则可能会缺失源数据的某些列。
原因
对于自由架构连接器(与其他行进行比较时,每行的列号、列名和列数据类型可能不同),默认情况下,ADF 使用样本行(例如,前 100 或 1000 行数据)来推断架构,并且推断结果会用作架构来读取数据。 因此,如果数据存储具有未出现在样本行中的额外列,则这些额外列的数据不会被读取、移动或传输到接收器数据存储中。
建议
为了覆盖默认行为并引入其他字段,ADF 提供了用于自定义源架构的选项。 可以在数据流源投影中指定架构推断结果中可能缺失的额外/缺失列来读取数据,并且可以应用以下选项之一来设置自定义架构。 通常情况下,选项 1 更为可取。
选项 1:与可能是包含数百万行并具有复杂架构的一个大型文件、表或容器的原始源数据进行比较时,可以使用包含要读取的所有列的几行创建临时表/容器,然后继续执行以下操作:
使用数据流源“调试设置”使具有样本文件/表的“导入投影”获取完整架构 。 可以执行下图中的步骤:
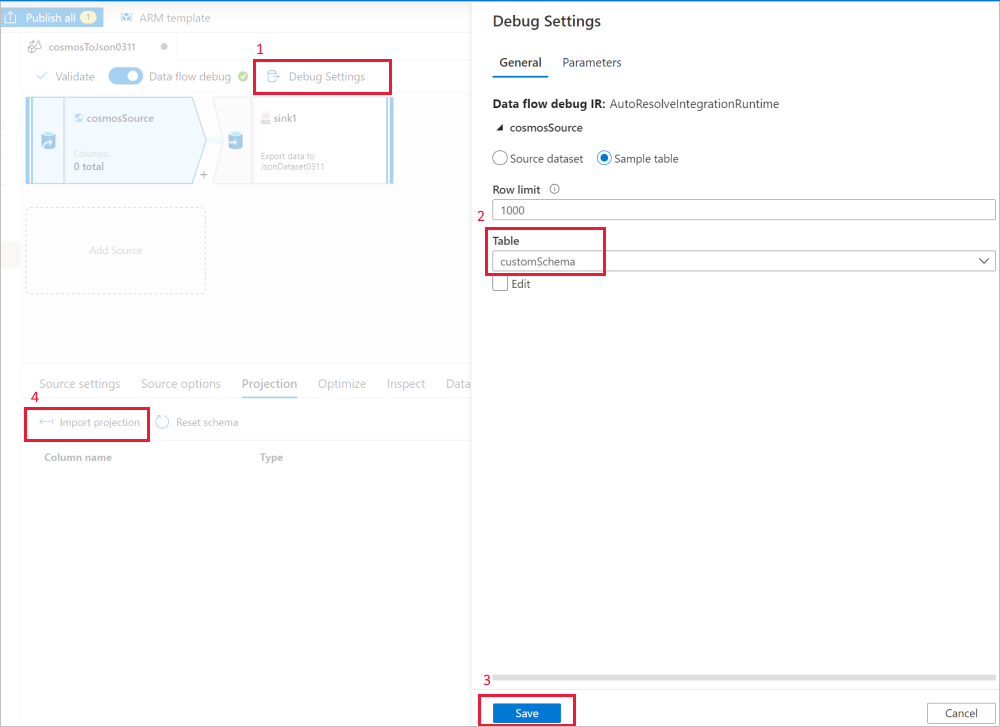
- 在数据流画布中选择“调试设置”。
- 在弹出窗口中,选择“cosmosSource”选项卡下的“样本表”,然后在“表”块中输入表的名称 。
- 选择“保存”以保存设置。
- 选择“导入投影”。
改回“调试设置”,以将源数据集用于其余数据移动/转换。 可以继续执行下图中的步骤:
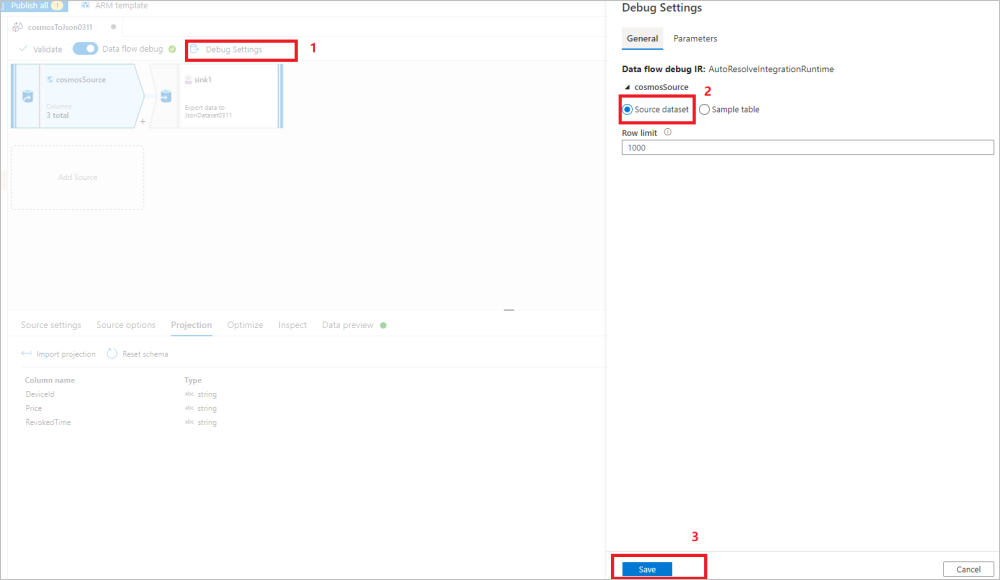
- 在数据流画布中选择“调试设置”。
- 在弹出窗口中,选择“cosmosSource”选项卡下的“源数据集” 。
- 选择“保存”以保存设置。
之后,ADF 数据流运行时会接受并使用自定义架构从原始数据存储读取数据。
选项 2:如果熟悉源数据的架构和 DSL 语言,则可以手动更新数据流源脚本,以添加额外/缺失列来读取数据。 下图显示了一个示例:
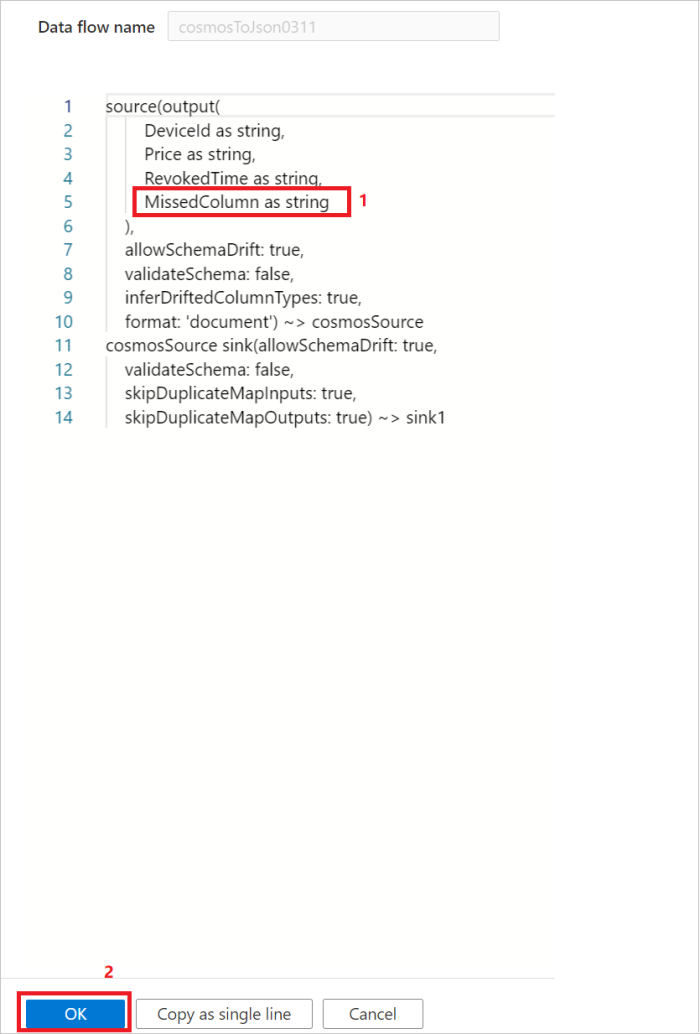
在源中支持映射类型
现象
在 ADF 数据流中,Azure Cosmos DB 或 JSON 源无法直接支持映射数据类型,因此你无法在“导入投影”下获得映射数据类型。
原因
对于 Azure Cosmos DB 和 JSON 来说,它们是无架构连接,而相关的 spark 连接器使用示例数据来推断架构,然后将该架构用作 Azure Cosmos DB/JSON 源架构。 推断架构时,Azure Cosmos DB/JSON spark 连接器只能将对象数据推断为结构,而不能推断为映射数据类型,这正是无法直接支持映射类型的原因。
建议
若要解决此问题,请参阅以下示例和步骤,手动更新 Azure Cosmos DB/JSON 源的脚本 (DSL) 以支持映射数据类型。
示例:

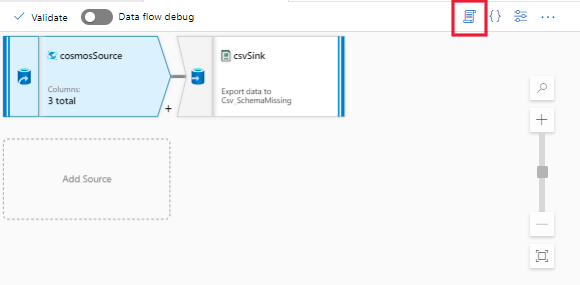
步骤 1:打开数据流活动的脚本。
步骤 2:参考上述示例更新 DSL 以支持映射类型。
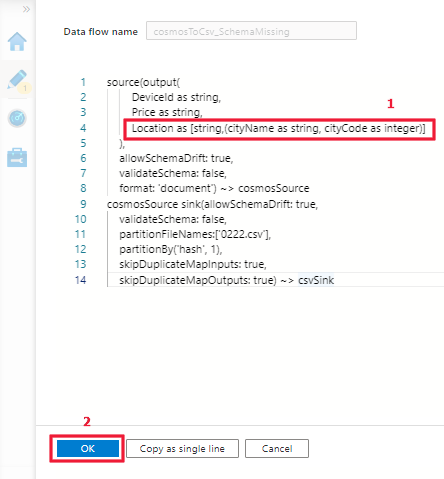
映射类型支持:
| 类型 | 是否支持映射类型? | 注释 |
|---|---|---|
| Excel、CSV | 否 | 两者都是使用基元类型的表格数据源,因此无需支持映射类型。 |
| Orc、Avro | 是 | 无。 |
| JSON | 是 | 无法直接支持映射类型。 请按照本节中的建议部分的要求更新源投影下的脚本 (DSL)。 |
| Azure Cosmos DB | 是 | 无法直接支持映射类型。 请按照本节中的建议部分的要求更新源投影下的脚本 (DSL)。 |
| Parquet | 是 | parquet 数据集目前不支持复杂数据类型,因此你需要使用数据流 parquet 源下的“导入投影”来获取映射类型。 |
| XML | 否 | 无。 |
使用复制活动生成的 JSON 文件
症状
如果使用复制活动生成一些 JSON 文件,尝试在数据流中读取这些文件会失败,并显示错误消息:JSON parsing error, unsupported encoding or multiline
原因
对于复制和数据流,JSON 分别有以下限制:
对于 Unicode 编码(utf-8、utf-16、utf-32)JSON 文件,复制活动始终生成带有 BOM 的 JSON 文件。
启用了“单个文档”的数据流 JSON 源不支持使用 BOM 进行 Unicode 编码。
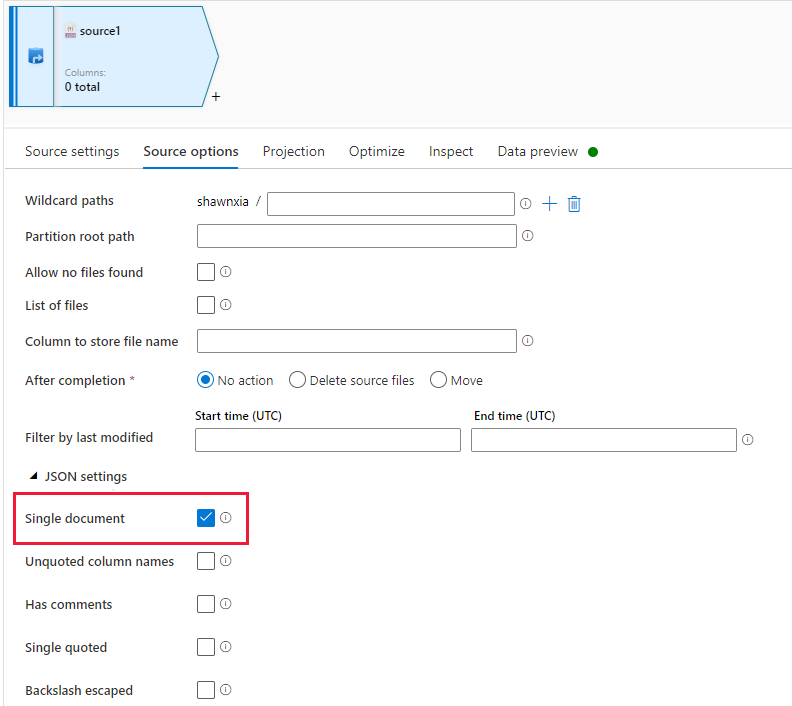
因此,在满足以下条件时可能会出现问题:
复制活动使用的接收器数据集设置为 Unicode 编码(utf-8、utf-16、utf-16be、utf-32、utf-32be)或使用默认值。
复制接收器设置为使用“对象数组”文件模式(如下图所示),无论数据流 JSON 源中是否启用了“单个文件”。
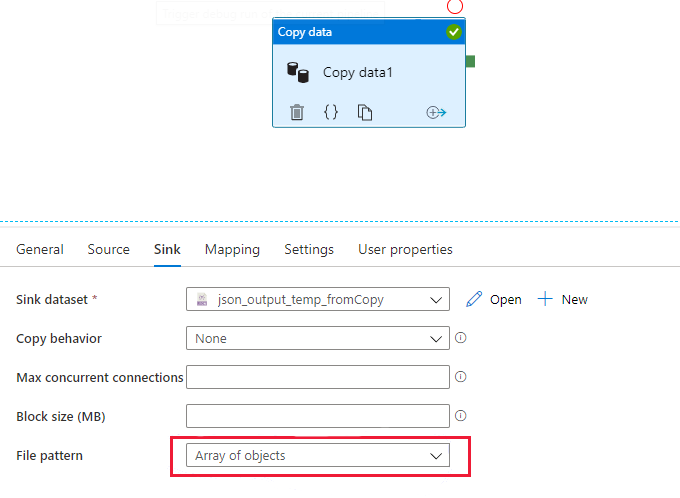
建议
- 如果在数据流中使用生成的文件,请始终在复制接收器中使用默认文件模式或显式“对象集”模式。
- 禁用数据流 JSON 源中的“单个文档”选项。
注意
从性能角度来看,还建议使用“对象集”。 由于数据流中的“单个文档”JSON 无法对单个大文件进行并行读取,因此本建议没有任何负面影响。
使用参数的查询不起作用
现象
Azure 数据工厂中的映射数据流支持使用参数。 参数值由调用管道通过执行数据流活动设置,使用参数是一种使数据流具有通用性、灵活性和可重用性的不错方式。 可以使用这些参数将数据流设置和表达式参数化:参数化映射数据流。
设置参数并在数据流源查询中使用它们后,这些参数不会生效。
原因
遇到此错误是由于配置错误。
建议
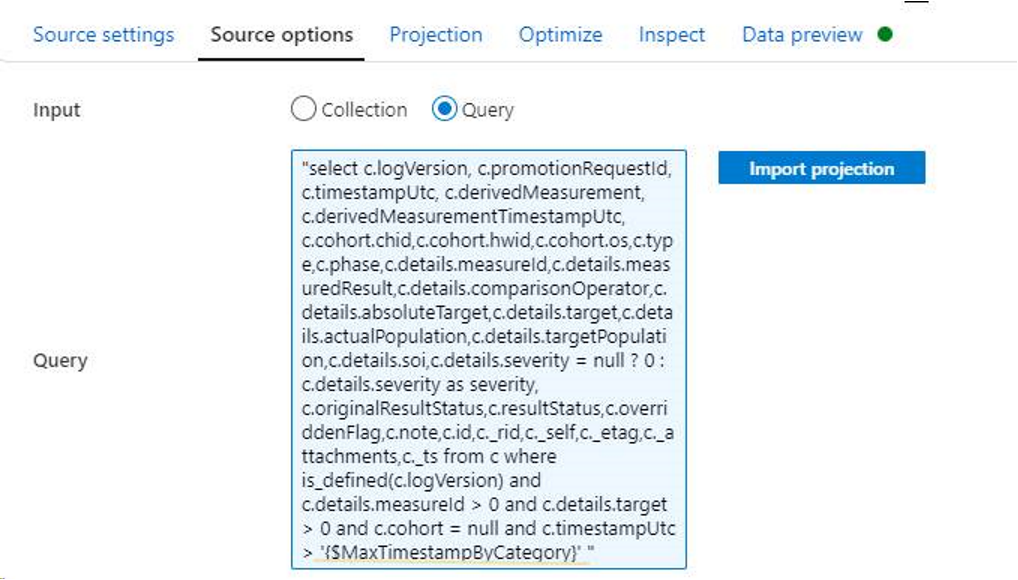
请使用下述规则设置查询中的参数,有关更多详细信息,请参阅在映射数据流中生成表达式。
- 在 SQL 语句的开头应用双引号。
- 在参数两侧使用单引号。
- 对所有 CLAUSE 语句使用小写字母。
例如:
Common Data Model 格式
带有特殊字符的 Model.json 文件
现象
你可能会遇到 model.json 文件的最终名称包含特殊字符的问题。
错误消息
at Source 'source1': java.lang.IllegalArgumentException: java.net.URISyntaxException: Relative path in absolute URI: PPDFTable1.csv@snapshot=2020-10-21T18:00:36.9469086Z.
建议
替换文件名中的特殊字符,这在 Synapse 中起作用,但在 ADF 中不起作用。
数据预览中或在运行管道后没有数据输出
症状
将 manifest.json 用于 CDM 时,数据预览中或在运行管道后不会显示任何数据。 只显示标头。 可以在下图中查看此问题。
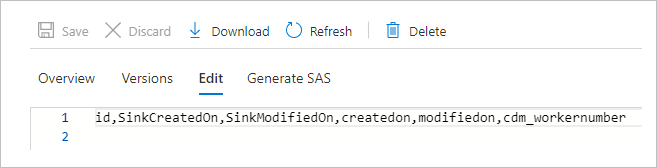
原因
清单文档描述 CDM 文件夹,例如,文件夹中有哪些实体、这些实体的引用以及与此实例对应的数据。 你的清单文档中缺少指示 ADF 在何处读取数据的 dataPartitions 信息,并且由于它是空文档,因此不会返回任何数据。
建议
更新清单文档以获得 dataPartitions 信息,可以参考此示例清单文档来更新你的文档:Common Data Model 元数据:引入清单示例清单文档。
JSON 数组属性被推断为单独的列
现象
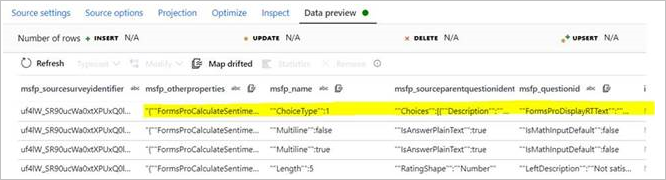
你可能会遇到 CDM 实体的一个属性(字符串类型)有一个 JSON 数组作为数据的问题。 遇到此数据时,ADF 错误地将数据推断为单独的列。 如下图所示,源 (msfp_otherproperties) 中显示的单个属性在 CDM 连接器的预览中被推断为单独一列。
在 CSV 源数据(参阅第二列)中:

在 CDM 源数据预览中:
还可以尝试映射偏移列,并使用数据流表达式将此属性转换为数组。 但由于在读取时将此属性作一个单独的列读取,因此转换为数组不起作用。
原因
此问题可能是由该列的 JSON 对象值中的逗号引起的。 因为数据文件应该是 CSV 文件,所以逗号表示它是列值的结尾。
建议
要解决此问题,需要对 JSON 列加双引号,并避免使用任何带有反斜杠 (\) 的内部引号。 这样,该列值的内容可以完全作为单个列来读取。
注意
CDM 没有通知列值的数据类型是 JSON,而是通知它是一个字符串,并按此进行分析。
无法在数据流预览中提取数据
症状
你将 CDM 与由 Power BI 生成的 model.json 一起使用。 使用数据流预览来预览 CDM 数据时,会遇到错误:No output data.
原因
由 Power BI 数据流生成的 model.json 文件的分区中存在以下代码。
"partitions": [
{
"name": "Part001",
"refreshTime": "2020-10-02T13:26:10.7624605+00:00",
"location": "https://datalakegen2.dfs.core.chinacloudapi.cn/powerbi/salesEntities/salesPerfByYear.csv @snapshot=2020-10-02T13:26:10.6681248Z"
}
对于此 model.json 文件,问题是数据分区文件的命名架构中包含特殊字符,并且当前不存在带有“@”的支持文件路径。
建议
请从数据分区文件名和 model.json 文件中删除 @snapshot=2020-10-02T13:26:10.6681248Z 部分,然后重试。
语料库路径为 null 或空
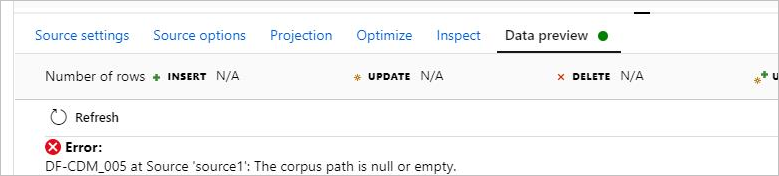
现象
将数据流中的 CDM 用于模型格式时,无法预览数据,并遇到错误:DF-CDM_005 The corpus path is null or empty。 该错误如下图所示:
原因
model.json 中的数据分区路径指向的是 Blob 存储位置,而不是数据湖。 对于 ADLS Gen2,该位置的基 URL 应该是 .dfs.core.chinacloudapi.cn。
建议
为了解决此问题,可以参考文章:ADF 向数据流添加了对内联数据集和 Common Data Model 的支持。下面的图片展示了修复了此文中所述语料库路径错误的方法。
无法读取 CSV 数据文件
现象
你使用内联数据集作为常见数据模型,将清单作为源,并提供了条目清单文件、根路径、实体名称和路径。 在清单中,有包含 CSV 文件位置的数据分区。 同时,实体架构和 CSV 架构完全相同,所有验证均成功。 但是,在数据预览中,只加载了架构而未加载数据,且数据不可见,如下图所示:
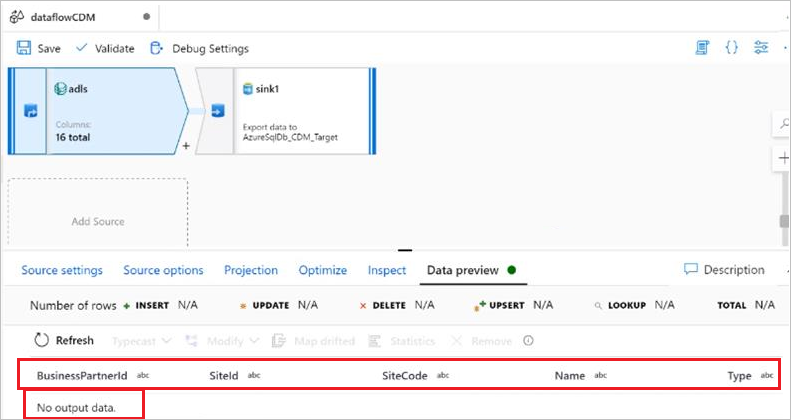
原因
CDM 文件夹不分为逻辑模型和物理模型,并且其中只存在物理模型。 以下两篇文章介绍了差异:逻辑定义和解析逻辑实体定义。
建议
对于使用 CDM 作为源的数据流,请尝试使用逻辑模型作为实体引用,并使用描述物理解析实体位置和数据分区位置的清单。 可以在公共 CDM GitHub 存储库 (CDM-schemaDocuments) 中看到一些逻辑实体定义示例
构建语料库的一个好的起点是复制架构文档文件夹(GitHub 存储库中的该级别)中的文件,然后将这些文件放到一个文件夹中。 之后,可以使用存储库中预定义的逻辑实体之一(作为起点或参考点)来创建逻辑模型。
设置语料库后,建议将 CDM 用作数据流中的接收器,这样就可以正确地创建格式标准的 CDM 文件夹。 可以使用 CSV 数据库作为源,然后将其接收到所创建的 CDM 模型。
CSV 和 Excel 格式
CSV 中不支持将引号字符设置为“无引号字符”
现象
当引号字符设置为“无引号字符”时,CSV 中不支持以下几个问题:
- 当引号字符设置为“无引号字符”时,多字符列分隔符不能以相同的字母开头和结尾。
- 当引号字符设置为“无引号字符”时,多字符列分隔符不能包含转义字符:
\。 - 当引号字符设置为“无引号字符”时,列值不能包含行分隔符。
- 如果列值包含列分隔符,则引号字符和转义字符不能同时为空(无引号且无转义)。
原因
下面分别举例说明了这些症状的原因:
以相同字母开头和结尾。
column delimiter: $*^$*
column value: abc$*^ def
csv sink: abc$*^$*^$*def
will be read as "abc" and "^&*def"多字符分隔符包含转义字符。
column delimiter: \x
escape char:\
column value: "abc\\xdef"
转义字符会对列分隔符或字符进行转义。列值包含行分隔符。
We need quote character to tell if row delimiter is inside column value or not.引号字符和转义字符都为空,列值包含列分隔符。
Column delimiter: \t
column value: 111\t222\t33\t3
It will be ambiguous if it contains 3 columns 111,222,33\t3 or 4 columns 111,222,33,3.
建议
当前无法解决第一个症状和第二个症状。 对于第三个和第四个症状,可以应用以下方法:
- 对于症状 3,请勿对多行 CSV 文件使用“无引号字符”。
- 对于症状 4,将引号或转义字符设置为非空,或者可以删除数据中的所有列分隔符。
读取具有不同架构的文件出错
现象
使用数据流读取具有不同架构的文件(例如 CSV 和 Excel 文件)时,数据流调试、沙盒或活动运行会失败。
对于 CSV,当文件架构不同时,存在数据未对齐的情况。
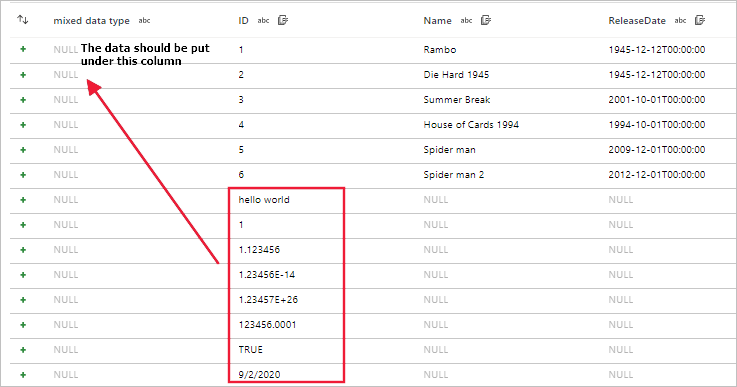
对于 Excel,文件架构不同时,会发生错误。

原因
不支持读取数据流中具有不同架构的文件。
建议
如果仍要传输数据流中具有不同架构的文件(如 CSV 和 Excel 文件),可以使用以下方法解决此问题:
对于 CSV,需要手动合并不同文件的架构,以获取完整的架构。 例如,file_1 的列为
c_1、c_2、c_3,而 file_2 的列为c_3、c_4、...c_10,因此合并后的完整架构是c_1、c_2、...c_10。 然后使其他文件也有相同的完整架构(即使它没有数据),例如 file_x 只有列c_1、c_2、c_3、c_4,添加文件中的列c_5、c_6、...c_10,使它们与其他文件一致。对于 Excel,你可以通过应用下列选项之一来解决此问题:
- 选项-1:需要手动合并不同文件的架构,以获取完整的架构。 例如,file_1 的列为
c_1、c_2、c_3,而 file_2 的列为c_3、c_4、...c_10,因此合并后的完整架构是c_1、c_2、...c_10。 然后使其他文件也有相同的架构(即使它没有数据),例如,file_x 与工作表“SHEET_1”只有列c_1、c_2、c_3、c_4,请在工作表中添加列c_5、c_6、...c_10,使其正常运行。 - 选项-2:使用“范围(例如 A1:G100)+ firstRowAsHeader=false”,然后它可以从所有 Excel 文件加载数据,即使列名和计数不同。
- 选项-1:需要手动合并不同文件的架构,以获取完整的架构。 例如,file_1 的列为
Snowflake
无法连接到 Snowflake 链接服务
现象
在公用网络中创建 Snowflake 链接服务并使用自动解析集成运行时时,遇到以下错误。
ERROR [HY000] [Microsoft][Snowflake] (4) REST request for URL https://XXXXXXXX.china-east-2.azure.snowflakecomputing.com.snowflakecomputing.com:443/session/v1/login-request?requestId=XXXXXXXXXXXXXXXXXXXXXXXXX&request_guid=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
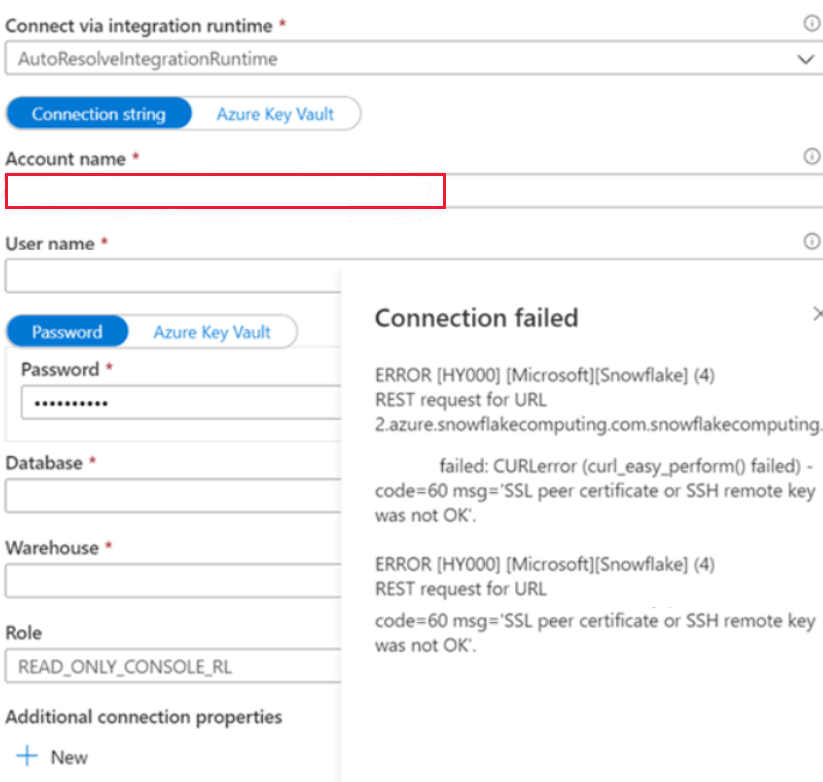
原因
尚未以 Snowflake 帐户文档中给定的格式(包括标识区域和云平台的额外段)应用帐户名,例如 XXXXXXXX.china-east-2.azure。 有关详细信息,请参阅文档:链接服务属性。
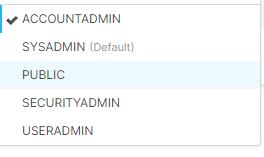
建议
要解决此问题,请更改帐户名格式。 角色应为下图所示的角色之一,但默认值为“Public”。
SQL 访问控制错误:“权限不足,无法对架构进行操作”
症状
尝试在数据流的 Snowflake 源中使用“导入投影”、“数据预览”等时,遇到类似 net.snowflake.client.jdbc.SnowflakeSQLException: SQL access control error: Insufficient privileges to operate on schema 的错误。
原因
遇到此错误是由于配置错误。 使用数据流读取 Snowflake 数据时,运行时 Azure Databricks (ADB) 不会直接选择 Snowflake 的查询。 而是创建一个临时阶段,将数据从表拉取到该阶段,然后由 ADB 压缩和拉取数据。 此过程如下图所示。
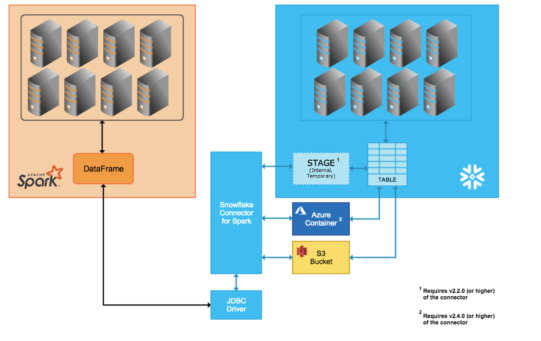
因此,在 ADB 中使用的用户/角色应具有在 Snowflake 中执行此操作所需的权限。 但用户/角色通常不具有该权限,因为该数据库是在该共享上创建的。
建议
要解决此问题,可以创建不同的数据库,并在共享 DB 的基础上创建视图,以便从 ADB 访问该数据库。 有关更多详细信息,请参阅 Snowflake。
失败并出现错误:“SnowflakeSQLException: 不允许 IP x.x.x.x 访问 Snowflake。 请联系你的本地安全管理员”
症状
在 Azure 数据工厂中使用 Snowflake 时,可以成功使用 Snowflake 链接服务中的测试连接、Snowflake 数据集上的预览数据/导入架构,并使用它运行复制/查找/获取元数据或其他活动。 但在数据流活动中使用 Snowflake 时,可能会看到类似“SnowflakeSQLException: IP 13.66.58.164 is not allowed to access Snowflake. Contact your local security administrator.”的错误
原因
Azure 数据工厂数据流不支持使用固定 IP 范围。 有关详细信息,请参阅 Azure 集成运行时 IP 地址。
建议
要解决此问题,可以通过以下步骤更改 Snowflake 帐户防火墙设置:
可以从“服务标记 IP 范围下载链接”中获取服务标记的 IP 范围列表:使用可下载的 JSON 文件发现服务标记。
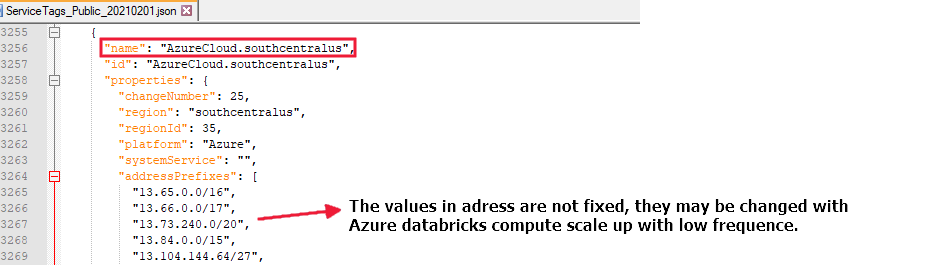
如果在“chinaeast2”区域中运行数据流,则需要允许从名为“AzureCloud.chinaeast2”的所有地址进行的访问,例如:
源中的查询不起作用
现象
尝试通过查询从 Snowflake 读取数据时,可能会看到如下错误:
SQL compilation error: error line 1 at position 7 invalid identifier 'xxx'SQL compilation error: Object 'xxx' does not exist or not authorized.
原因
遇到此错误是由于配置错误。
建议
对于 Snowflake,它在创建/定义时将以下规则应用于存储标识符,并在查询和其他 SQL 语句中解析它们:
当标识符(表名、架构名、列名等)不带引号时,默认情况下以大写形式存储和解析,并且不区分大小写。 例如:

因为它不区分大小写,所以你可以随意使用以下查询来读取 Snowflake 数据,而结果是相同的:
Select MovieID, title from Public.TestQuotedTable2Select movieId, title from Public.TESTQUOTEDTABLE2Select movieID, TITLE from PUBLIC.TESTQUOTEDTABLE2
当标识符(表名、架构名、列名等)带有双引号时,它的存储和解析方式与输入完全一致,包括大小写(因为区分大小写),你可以在下图中看到一个示例。 有关更多详细信息,请参阅此文档:标识符要求。

由于区分大小写的标识符(表名、架构名、列名等)具有小写字符,因此在使用查询读取数据时必须在标识符两边使用引号,例如:
- Select "movieId", "title" from Public."testQuotedTable2"
如果 Snowflake 查询出现错误,请按以下步骤检查某些标识符(表名、架构名、列名等)是否区分大小写:
登录 Snowflake 服务器(
https://{accountName}.azure.snowflakecomputing.com/,将 {accountName} 替换为自己的帐户名)以检查标识符(表名称、架构名称、列名称等)。创建用于测试和验证查询的工作表:
- 运行
Use database {databaseName},将 {databaseName} 替换为你的数据库名。 - 使用表运行查询,例如
select "movieId", "title" from Public."testQuotedTable2"
- 运行
测试和验证 Snowflake 的 SQL 查询后,可以直接在数据流 Snowflake 源中使用它。
表达式类型与列数据类型不匹配,需要 VARIANT,但获得的是 VARCHAR
现象
尝试将数据写入 Snowflake 表时,可能会遇到以下错误:
java.sql.BatchUpdateException: SQL compilation error: Expression type does not match column data type, expecting VARIANT but got VARCHAR
原因
输入数据的列类型为字符串,此类型不同于 Snowflake 接收器中相关列的 VARIANT 类型。
在新的 Snowflake 表中通过复杂架构(数组/映射/结构)存储数据时,数据流类型会自动转换为其物理类型 VARIANT。

相关值以 JSON 字符串的形式存储,如下图所示。

建议
对于 Snowflake VARIANT,它只能接受类型为结构、映射或数组的数据流值。 如果输入数据列的值为 JSON、XML 或其他字符串,请使用下列选项之一来解决此问题:
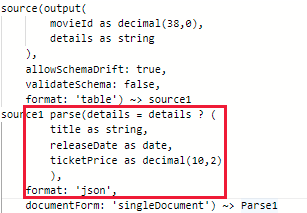
选项-1:使用 Snowflake 作为接收器之前,使用分析转换将输入数据列值转换为结构、映射或数组类型,例如:
注意
默认情况下,具有 VARIANT 类型的 Snowflake 列的值在 Spark 中以字符串形式读取。
选项-2:登录 Snowflake 服务器(
https://{accountName}.azure.snowflakecomputing.com/,将 {accountName} 替换为你的帐户名),更改 Snowflake 目标表的架构。 通过在每个步骤下运行查询,应用以下步骤。创建一个具有 VARCHAR 的新列来存储这些值。
alter table tablename add newcolumnname varchar;将 VARIANT 类型的值复制到新列中。
update tablename t1 set newcolumnname = t1."details"删除未使用的 VARIANT 列。
alter table tablename drop column "details";将新列重命名为旧名称。
alter table tablename rename column newcolumnname to "details";
相关内容
在故障排除时如需更多帮助,请参阅以下资源: