适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
数据流在 Azure 数据工厂管道和 Azure Synapse Analytics 管道中都可用。 本文适用于映射数据流。 如果你不熟悉转换,请参阅介绍性文章: 使用映射数据流转换数据。
使用“解析”转换来解析数据中以文档形式的字符串文本列。 可以分析的嵌入文档的当前支持类型是 JSON、XML 和带分隔符的文本。
配置
在分析转换配置面板中,首先选择要以内联方式分析的列中包含的数据类型。 分析转换还包含以下配置设置。

列
“列”属性与派生列和聚合类似,你可以在该属性中通过从下拉选取器中选择现有列来对其进行修改。 或者,也可以在此处键入新列的名称。 ADF 会将已分析的源数据存储在此列中。 在大多情况下,需定义一个新列来分析传入的嵌入式文档字符串字段。
表达式
使用表达式生成器设置分析的源。 设置源可以很简单(只需选择包含要分析的自包含数据的源列即可),也可以很复杂(即创建要分析的复杂表达式)。
表达式示例
源字符串数据:
chrome|steel|plastic- 表达式:
(desc1 as string, desc2 as string, desc3 as string)
- 表达式:
源 JSON 数据:
{"ts":1409318650332,"userId":"309","sessionId":1879,"page":"NextSong","auth":"Logged In","method":"PUT","status":200,"level":"free","itemInSession":2,"registration":1384448}- 表达式:
(level as string, registration as long)
- 表达式:
源嵌套 JSON 数据:
{"car" : {"model" : "camaro", "year" : 1989}, "color" : "white", "transmission" : "v8"}- 表达式:
(car as (model as string, year as integer), color as string, transmission as string)
- 表达式:
源 XML 数据:
<Customers><Customer>122</Customer><CompanyName>Great Lakes Food Market</CompanyName></Customers>- 表达式:
(Customers as (Customer as integer, CompanyName as string))
- 表达式:
具有属性数据的源 XML:
<cars><car model="camaro"><year>1989</year></car></cars>- 表达式:
(cars as (car as ({@model} as string, year as integer)))
- 表达式:
具有保留字符的表达式:
{ "best-score": { "section 1": 1234 } }- 上述表达式不起作用,因为
best-score中的“-”字符被解释为减法运算。 在这些情况下,请使用采用括号表示法的变量来告诉 JSON 引擎从字面上解释文本:var bestScore = data["best-score"]; { bestScore : { "section 1": 1234 } }
- 上述表达式不起作用,因为
注意:如果在从某个复杂类型中提取属性(即 @model)时遇到错误,一个解决方法是将该复杂类型转换为字符串,移除 @ 符号(即 replace(toString(your_xml_string_parsed_column_name.cars.car),'@','')),然后使用分析 JSON 转换活动。
输出列类型
你将在此处配置目标输出架构,该架构基于解析结果,并将其写入单列。 为分析输出设置架构的最简单方法是选择表达式生成器右上方的“检测类型”按钮。 ADF 将尝试从你正在分析的字符串字段中自动检测架构,并在输出表达式中设置该架构。
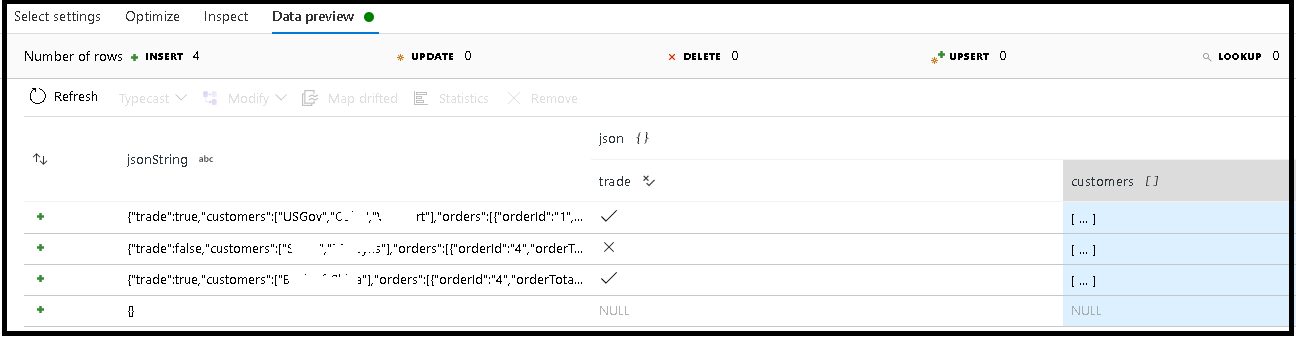
在此示例中,我们定义了对传入字段“jsonString”的分析,该字段是纯文本,但格式为 JSON 结构。 我们将使用此架构将分析结果以 JSON 格式存储在一个名为“json”的新列中:
(trade as boolean, customers as string[])
请参阅检查标签页及数据预览,以确保输出被正确映射。
使用“派生列”功能活动来提取分层数据(例如在表达式字段中输入 your_complex_column_name.car.model)
示例
source(output(
name as string,
location as string,
satellites as string[],
goods as (trade as boolean, customers as string[], orders as (orderId as string, orderTotal as double, shipped as (orderItems as (itemName as string, itemQty as string)[]))[])
),
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false,
documentForm: 'documentPerLine') ~> JsonSource
source(output(
movieId as string,
title as string,
genres as string
),
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false) ~> CsvSource
JsonSource derive(jsonString = toString(goods)) ~> StringifyJson
StringifyJson parse(json = jsonString ? (trade as boolean,
customers as string[]),
format: 'json',
documentForm: 'arrayOfDocuments') ~> ParseJson
CsvSource derive(csvString = 'Id|name|year\n\'1\'|\'test1\'|\'1999\'') ~> CsvString
CsvString parse(csv = csvString ? (id as integer,
name as string,
year as string),
format: 'delimited',
columnNamesAsHeader: true,
columnDelimiter: '|',
nullValue: '',
documentForm: 'documentPerLine') ~> ParseCsv
ParseJson select(mapColumn(
jsonString,
json
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> KeepStringAndParsedJson
ParseCsv select(mapColumn(
csvString,
csv
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> KeepStringAndParsedCsv
数据流脚本
语法
示例
parse(json = jsonString ? (trade as boolean,
customers as string[]),
format: 'json|XML|delimited',
documentForm: 'singleDocument') ~> ParseJson
parse(csv = csvString ? (id as integer,
name as string,
year as string),
format: 'delimited',
columnNamesAsHeader: true,
columnDelimiter: '|',
nullValue: '',
documentForm: 'documentPerLine') ~> ParseCsv