适用于: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
本文介绍可以在Azure Data Factory或Azure Synapse Analytics管道中创建的存储事件触发器。
事件驱动的体系结构是一种常见数据集成模式,其中涉及到事件的生成、检测、消耗和响应。 数据集成方案通常要求客户触发从Azure Storage帐户上的事件触发的管道,例如Azure Blob Storage帐户中的文件的到达或删除。 数据工厂和 Azure Synapse Analytics 管道原生集成了 Azure Event Grid,这使您可以在此类事件发生时触发管道。
存储事件触发器注意事项
使用存储事件触发器时,请考虑以下几点:
- 本文中所述的集成取决于 Azure Event Grid。 请确保您的订阅已通过事件网格资源提供者注册。 有关详细信息,请参阅资源提供程序和类型。 必须能够执行
Microsoft.EventGrid/eventSubscriptions/操作。 此操作是EventGrid EventSubscription Contributor内置角色的一部分。 - 如果在 Azure Synapse Analytics 中使用此功能,请确保还向数据工厂资源提供程序注册订阅。 否则,你会收到一条消息,指出“创建事件订阅失败”。
- 如果 Blob Storage 帐户位于 private 终结点后面并阻止公共网络访问,则需要配置网络规则以允许从Blob Storage到事件网格的通信。 可以按照 Storage 文档授予存储对受信任的 Azure 服务(如事件网格)的访问权限,或者按照 Event Grid 文档配置映射到虚拟网络地址空间的事件网格专用终结点。
- 存储事件触发器目前仅支持Azure Data Lake Storage Gen2和常规用途版本 2 存储帐户。 如果正在处理安全文件传输协议 (SFTP) 存储事件,则还需要在筛选部分下指定 SFTP 数据 API。 由于事件网格限制,数据工厂仅支持每个存储帐户最多 500 个存储事件触发器。
- 若要创建新的存储事件触发器或修改现有触发器,用于登录到服务的Azure帐户和发布存储事件触发器必须对存储帐户具有适当的基于角色的访问控制(Azure RBAC)权限。 不需要其他权限。 Azure Data Factory和Azure Synapse Analytics的服务主体不需要对存储帐户或事件网格具有特殊权限。 有关访问控制的详细信息,请参阅基于角色的访问控制部分。
- 如果将Azure Resource Manager锁应用到存储帐户,则可能会影响 blob 触发器创建或删除 Blob 的能力。
ReadOnly锁可阻止创建和删除,而DoNotDelete锁则会防止删除。 请确保考虑到这些限制,以避免触发器出现任何问题。 - 不建议将文件到达触发器作为数据流接收器的触发机制。 数据流可在目标文件夹中执行许多文件重命名和分区文件整理任务,这些任务可能会在数据完成处理之前意外触发文件到达事件。
使用 UI 创建触发器
本部分介绍如何在Azure Data Factory和Azure Synapse Analytics管道用户界面(UI)中创建存储事件触发器。
切换到数据工厂中的 Edit 选项卡或 Azure Synapse Analytics 中的 Integrate 选项卡。
在菜单上选择“触发器”,然后选择“新建/编辑”。
在“添加触发器”页中选择“选择触发器”,然后选择“+ 新建”。
选择触发器类型“存储事件”。
从Azure订阅下拉列表中选择存储帐户,或使用其存储帐户资源 ID 手动选择存储帐户。 选择你希望在其中发生事件的容器。 需选择容器,但选择所有容器可能会导致发生大量事件。
使用
Blob path begins with和Blob path ends with属性可以指定要接收其事件的容器、文件夹和 blob 的名称。 存储事件触发器要求至少定义其中的一个属性。 可以同时对Blob path begins with和Blob path ends with属性使用各种模式,如本文后面的示例所示。-
Blob path begins with:blob 路径必须以文件夹路径开头。 有效值包括2018/和2018/april/shoes.csv。 如果未选择容器,则无法选择此字段。 -
Blob path ends with:blob 路径必须以文件名或扩展名结尾。 有效值包括shoes.csv和.csv。 指定容器和文件夹名称时,它们必须由/blobs/段分隔。 例如,名为orders的容器的值可以为/orders/blobs/2018/april/shoes.csv。 若要在任何容器中指定文件夹,请省略开头的/字符。 例如,april/shoes.csv会在任何容器内名为shoes.csv的文件夹中对名为april的任何文件触发事件。
请注意,
Blob path begins with和Blob path ends with是存储事件触发器中唯一允许的模式匹配。 触发器类型不支持其他类型的通配符匹配。-
选择触发器是响应已创建 Blob 事件、已删除 Blob 事件,还是同时响应这两种事件。 在您指定的存储位置中,每个事件都会触发与触发器关联的 Azure 数据工厂和 Azure Synapse Analytics 管道。
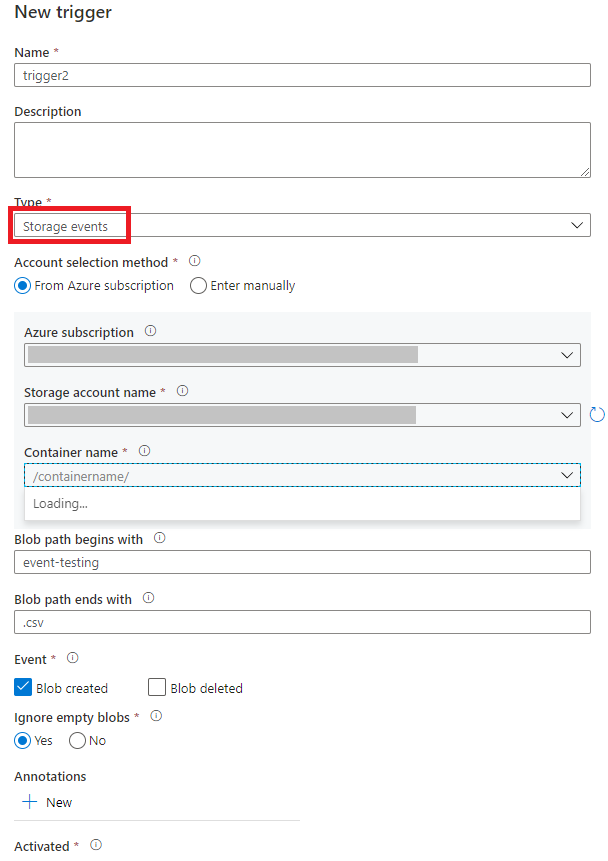
选择是否让触发器忽略零字节的 Blob。
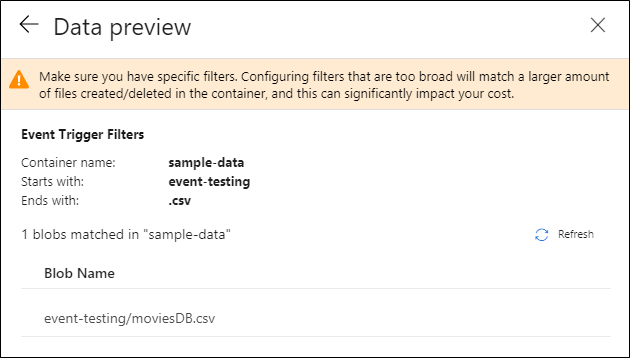
配置触发器后,选择“下一步: 数据预览”。 该界面显示在您的存储事件触发器配置中匹配的现有 Blob。 请确保拥有特定筛选器。 配置要求过宽的筛选器可能会匹配大量已创建或删除的文件,并且可能会显著影响成本。 验证筛选器条件后,选择“完成”。
若要将管道附加到此触发器,请转到管道画布,然后选择“触发器”“新建/编辑”>。 出现侧窗格时,选择“选择触发器”下拉列表,然后选择创建的触发器。 选择“下一步: 数据预览”以确认配置是否正确。 然后选择“下一步”以验证数据预览是否正确。
如果管道具有参数,则可以在“触发器运行参数”侧窗格上指定它们。 存储事件触发器将 Blob 的文件夹路径和文件名捕获到属性
@triggerBody().folderPath和@triggerBody().fileName中。 若要在管道中使用这些属性的值,必须将这些属性映射至管道参数。 将这些属性映射至参数后,可以通过管道中的@pipeline().parameters.parameterName表达式访问由触发器捕获的值。 有关详细说明,请参阅管道中触发器元数据的参考资料。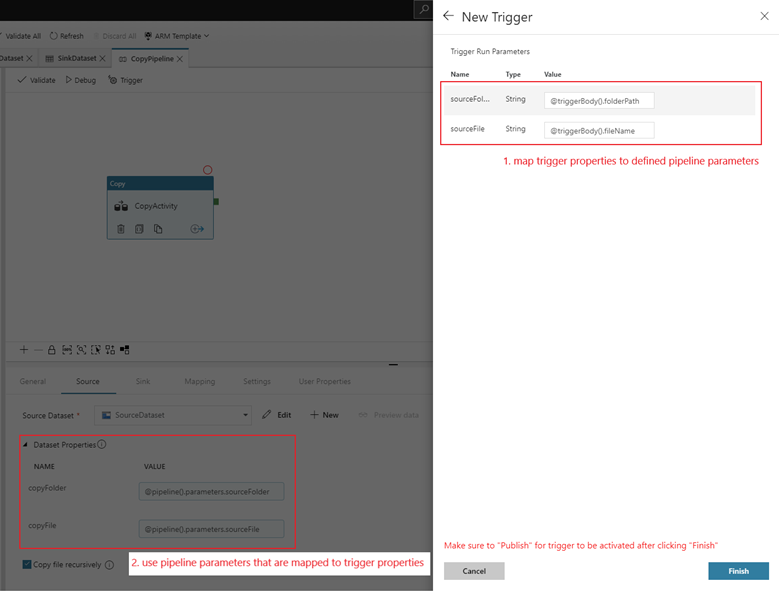
在前面的示例中,触发器配置为在容器 sample-data 中的文件夹 event-testing 内创建了以 .csv 结尾的 Blob 路径时触发。
folderPath和fileName属性捕获新 blob 的位置。 例如,将 MoviesDB.csv 添加到路径 sample-data/event-testing 时, 的值为@triggerBody().folderPath,并且sample-data/event-testing的值为@triggerBody().fileNamemoviesDB.csv。 这些值在示例中映射到管道参数sourceFolder和sourceFile,这些参数可分别作为@pipeline().parameters.sourceFolder和@pipeline().parameters.sourceFile在整个管道中使用。完成后,选择“完成”。

JSON 架构
下表概述了与存储事件触发器相关的架构元素。
| JSON 元素 | 说明 | 类型 | 允许的值 | 必须 |
|---|---|---|---|---|
| 作用域 | 存储帐户的 Azure Resource Manager 资源 ID。 | 字符串 | Azure 资源管理器 ID | 是的。 |
| 活动 | 导致此触发器触发的事件的类型。 | 数组 |
Microsoft.Storage.BlobCreated,Microsoft.Storage.BlobDeleted |
是的,这些值的任意组合。 |
blobPathBeginsWith |
blob 路径必须以触发器触发所提供的模式开头。 例如,/records/blobs/december/ 只会触发 december 容器下 records 文件夹中的 blob 触发器。 |
字符串 | 必须为以下至少一个属性提供值:blobPathBeginsWith 或 blobPathEndsWith。 |
|
blobPathEndsWith |
blob 路径必须使用为要触发的触发器提供的模式结尾。 例如,december/boxes.csv 只会在 boxes 文件夹中名为 december 的 blob 上触发触发器。 |
字符串 | 必须为以下至少一个属性提供值:blobPathBeginsWith 或 blobPathEndsWith。 |
|
ignoreEmptyBlobs |
零字节 blob 是否触发管道运行。 默认情况下,这设置为 true。 |
布尔 | 真或假 (true or false) | 否。 |
存储事件触发器的示例
本部分提供了存储事件触发器设置的示例。
重要
每当指定容器和文件夹、容器和文件或容器、文件夹和文件时,都必须包含路径的 /blobs/ 段,如以下示例所示。 对于 blobPathBeginsWith,UI 将在触发器 JSON 中的文件夹和容器名称之间自动添加 /blobs/。
| 属性 | 示例 | 说明 |
|---|---|---|
Blob path begins with |
/containername/ |
接收容器中任何 blob 事件。 |
Blob path begins with |
/containername/blobs/foldername/ |
接收 containername 容器和 foldername 文件夹中的任何 blob 事件。 |
Blob path begins with |
/containername/blobs/foldername/subfoldername/ |
你还可以引用一个子文件夹。 |
Blob path begins with |
/containername/blobs/foldername/file.txt |
接收 file.txt 容器下的 foldername 文件夹中名为 containername 的 blob 事件。 |
Blob path ends with |
file.txt |
在任何路径中接收名称为 file.txt 的 blob 数据对象的事件。 |
Blob path ends with |
/containername/blobs/file.txt |
接收名为 file.txt 的 blob 在容器 containername 下的事件。 |
Blob path ends with |
foldername/file.txt |
接收任何容器下 file.txt 文件夹中名为 foldername 的 blob 事件。 |
基于角色的访问控制
数据工厂和Azure Synapse Analytics管道使用Azure基于角色的访问控制(Azure RBAC),以确保严格禁止未经授权的访问,侦听、订阅更新和触发与blob事件链接的管道。
- 若要成功创建新的存储事件触发器或更新现有存储事件触发器,登录到服务的Azure帐户需要对相关存储帐户具有适当的访问权限。 否则,操作将会失败并显示消息“拒绝访问”。
- 数据工厂和 Azure Synapse Analytics 无需对您的事件网格实例赋予特殊权限,您也不需要为操作中的数据工厂或 Azure Synapse Analytics 服务主体分配特殊的 RBAC 权限。
以下任何 RBAC 设置都适用于存储事件触发器:
- 存储帐户的所有者角色
- 存储帐户的贡献者角色
-
Microsoft.EventGrid/EventSubscriptions/Write存储帐户的权限/subscriptions/####/resourceGroups/####/providers/Microsoft.Storage/storageAccounts/storageAccountName
为了了解服务如何做出这两项承诺,让我们回过头来看看背后的流程。 下面是数据工厂/Azure Synapse Analytics、存储和事件网格之间的集成的高级工作流。
创建新的存储事件触发器
此概要工作流介绍数据工厂如何与事件网格交互,以创建存储事件触发器。 数据流在Azure Synapse Analytics中相同,Azure Synapse Analytics管道在下图中扮演数据工厂的角色。
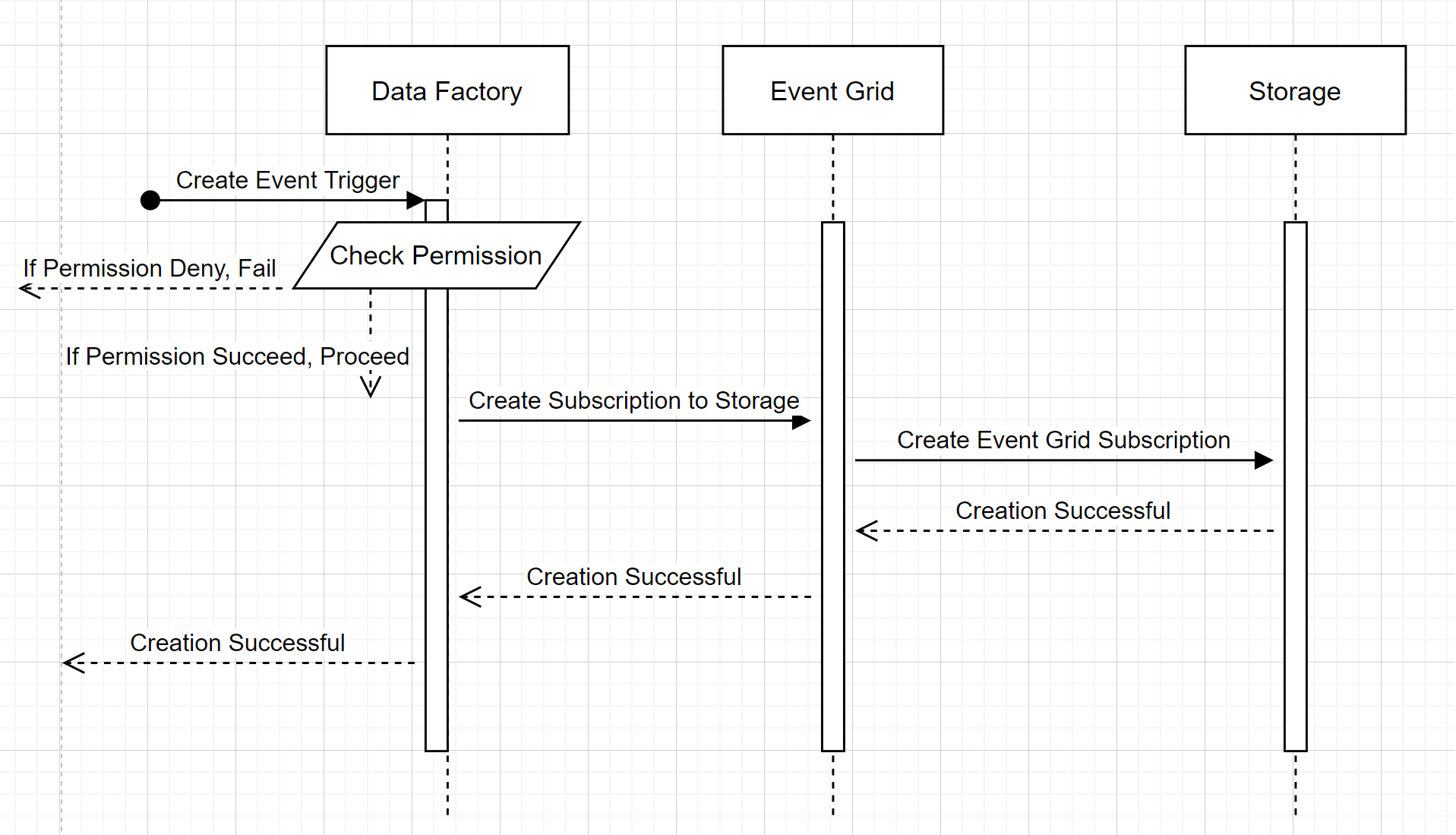
工作流中的两个显著突出点:
- 数据工厂和Azure Synapse Analytics不与存储帐户直接联系。 创建订阅的请求将通过事件网格进行中继和处理。 在此步骤,服务不需要访问存储帐户的权限。
- 访问控制和权限检查发生在服务中。 在服务发送订阅存储事件的请求之前,它会检查用户的权限。 更具体地说,它会检查登录并尝试创建存储事件触发器的Azure帐户是否具有对相关存储帐户的适当访问权限。 如果权限检查失败,触发器创建也会失败。
存储事件触发管道运行
此高级工作流描述了存储事件触发器管道如何通过事件网格运行。 对于Azure Synapse Analytics,数据流相同,Azure Synapse Analytics管道在下图中扮演数据工厂的角色。
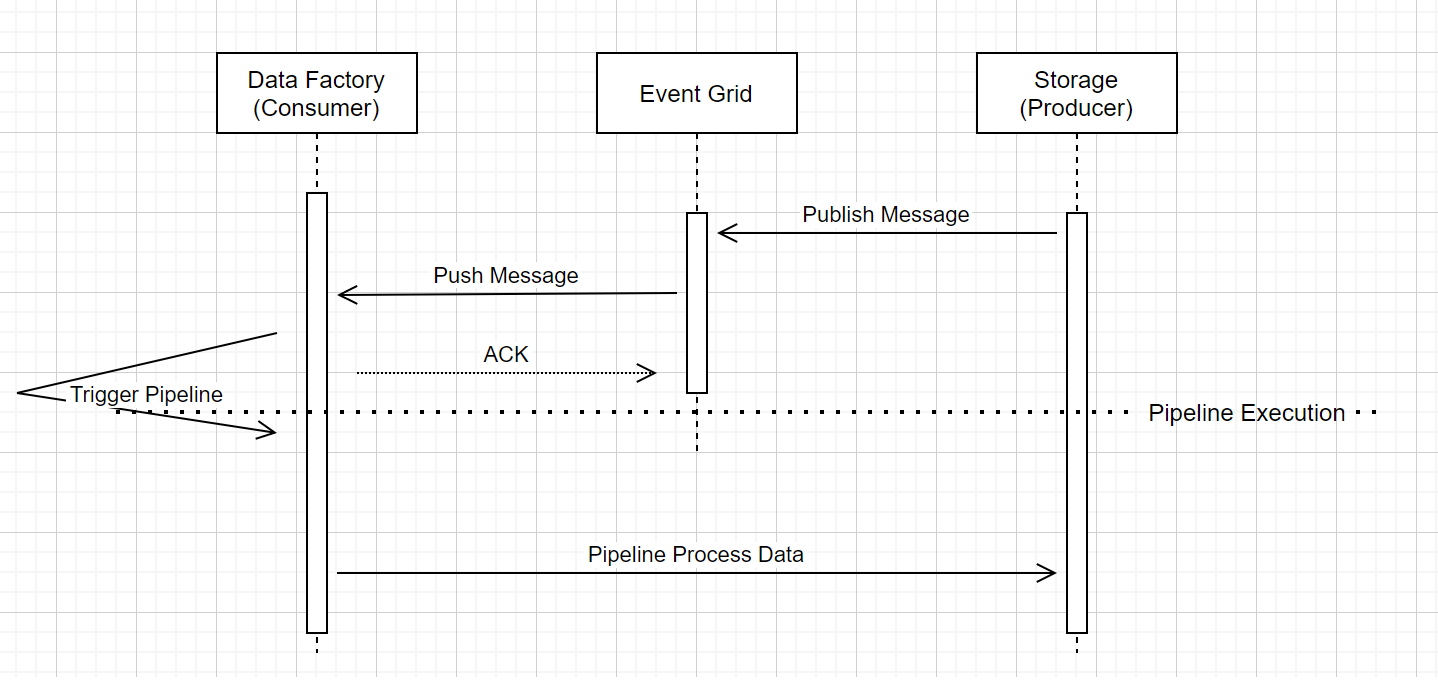
工作流中有三个明显标注与服务中的事件触发管道相关:
事件网格使用推送模型,当存储把消息放入系统时,它会尽快传递消息。 此方法与消息传递系统(例如使用请求系统的 Kafka)不同。
事件触发器充当传入消息的活动侦听器,并正确触发关联的管道。
存储事件触发器本身不直接与存储帐户联系。
- 如果管道中有一个复制活动(Copy activity)或其他活动来处理存储帐户中的数据,服务会使用链接服务中存储的凭据直接与存储帐户联系。 确保正确设置了链接服务。
- 如果不引用管道中的存储帐户,则无需授予服务访问存储帐户的权限。
相关内容
- 有关触发器的详细信息,请参阅管道执行和触发器。
- 若要引用管道中的触发器元数据,请参阅引用管道运行中的触发器元数据。