适用于: Azure 数据工厂
Azure 数据工厂  Azure Synapse Analytics
Azure Synapse Analytics
在大数据环境中,原始、散乱的数据通常存储在关系、非关系和其他存储系统中。 但是,就其本身而言,原始数据没有适当的上下文或含义来为分析师、数据科学家或业务决策人提供有意义的见解。
大数据需要一种可以协同和实施流程的服务,以将这些巨大的原始数据储备转化为可操作的业务洞见。 Azure 数据工厂是为这些复杂的混合提取-转换-加载 (ETL)、提取-加载-转换 (ELT) 和数据集成项目而构建的托管云服务。
Azure 数据工厂的功能
数据压缩:在数据复制活动期间,可以压缩数据,并将压缩后的数据写入目标数据源。 此功能有助于优化数据复制中的带宽使用情况。
对不同数据源的广泛连接支持:Azure 数据工厂为连接到不同数据源提供广泛的连接支持。 如果要从不同的数据源拉取或写入数据,这非常有用。
自定义事件触发器:Azure 数据工厂支持使用自定义事件触发器自动执行数据处理。 此功能支持在发生特定事件时自动执行特定操作。
数据预览和验证:在数据复制活动期间,提供了用于预览和验证数据的工具。 此功能有助于确保正确复制数据并将数据正确写入目标数据源。
可自定义数据流:Azure 数据工厂支持创建可自定义的数据流。 此功能支持添加自定义操作或步骤以进行数据处理。
集成安全性:Azure 数据工厂提供集成安全性功能,例如 Entra ID 集成和基于角色的访问控制来控制对数据流的访问。 此功能可提高数据处理的安全性并保护数据。
使用方案
例如,假设某个游戏公司收集云中的游戏所生成的万兆字节的游戏日志。 该公司的目的是通过分析这些日志,了解客户偏好、人口统计信息和使用行为。 该公司的另一个目的是确定向上销售和交叉销售机会、开发极具吸引力的新功能、促进企业发展,并为其客户提供更好的体验。
为了分析这些日志,该公司需要使用参考数据,例如位于本地数据存储中的客户信息、游戏信息和市场营销活动信息。 该公司希望从本地数据存储使用此数据,将其与云数据存储中具有的其他日志数据相结合。
为了获取见解,它希望使用云中的 Spark 群集 (Azure HDInsight) 处理加入的数据,并将转换的数据发布到云数据仓库(如 Azure Synapse Analytics)以轻松地基于它生成报表。 公司的人员希望自动执行此工作流,并每天按计划对其进行监视和管理。 他们还希望在文件存储到 blob 存储容器中时执行该工作流。
Azure 数据工厂是解决此类数据方案的平台。 它是 基于云的 ETL 和数据集成服务,可用于创建数据驱动的工作流,以便大规模协调数据移动和转换数据。 可以使用 Azure 数据工厂创建和计划数据驱动型工作流(称为管道),以便从不同的数据存储引入数据。 可以构建复杂的 ETL 流程,用于通过数据流或使用 Azure HDInsight Hadoop、Azure Databricks 和 Azure SQL 数据库等计算服务直观转换数据。
此外,还可以将转换的数据发布到数据存储(例如 Azure Synapse Analytics),供商业智能 (BI) 应用程序使用。 最终,通过 Azure 数据工厂,可将原始数据组织成有意义的数据存储和数据湖,以实现更好的业务决策。
工作原理
数据工厂包含一系列为数据工程师提供完整端到端平台的互连系统。

本视觉指南详细说明了完整的数据工厂体系结构:

若要查看更多详细信息,请选择前面的图像进行放大,或浏览到高分辨率图像。
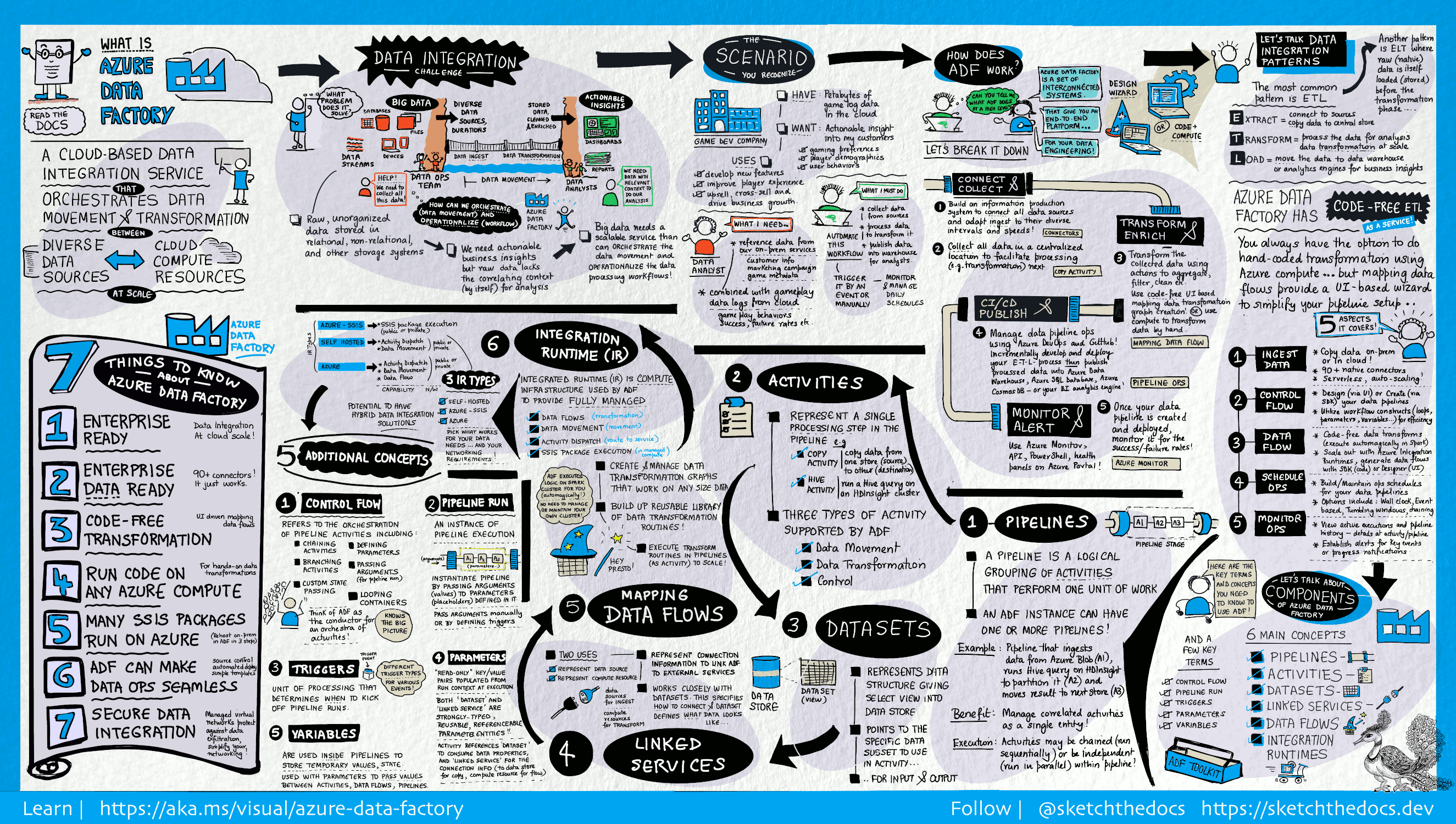{kind=link}
连接和收集
企业拥有各种类型的数据(位于云、结构化、非结构化和半结构化的本地分散源中),都以不同的时间间隔和速度到达。
构建信息生产系统时,第一步是连接到所有必需的数据和处理源(例如软件即服务 (SaaS) 服务、数据库、文件共享、FTP Web 服务)。 下一步是根据需要将数据移至中央位置进行后续处理。
没有数据工厂,企业就必须生成自定义数据移动组件或编写自定义服务,以便集成这些数据源并进行处理。 集成和维护此类系统既昂贵又困难。 另外,这些系统通常还缺乏企业级监视、警报和控制,而这些功能是完全托管的服务能够提供的。
而有了数据工厂,便可以在数据管道中使用复制活动,将数据从本地和云的源数据存储移到云的集中数据存储进行进一步的分析。 例如,还可以使用 Azure HDInsight Hadoop 群集在 Azure Blob 存储中收集数据并稍后对其进行转换。
转换和扩充
在云中的集中数据存储中存在数据后,使用Azure 数据工厂映射数据流处理或转换收集的数据。 数据工程师可以使用数据流来构建和维护在 Spark 中执行的数据转换图,而无需了解 Spark 群集或 Spark 编程。
如果希望手动编写转换代码,Azure 数据工厂支持外部活动,以便在 HDInsight Hadoop、Azure Databricks 和 机器学习 等计算服务上执行转换。
发布
原始数据被优化为业务可用的形式后,请将数据载入 Azure 数据仓库、Azure SQL 数据库、Azure CosmosDB 或业务用户可以通过其商业智能工具软件指向的任何分析引擎。
监视
在构建并部署数据集成管道、从精炼后的数据中创造业务价值之后,请监控计划活动和管道的成功率与失败率。 Azure 数据工厂通过 Azure 门户上的 Azure Monitor、API、PowerShell、Azure Monitor 日志和运行状况面板,对管道监视提供内置支持。
高级概念
一个 Azure 订阅可以包含一个或多个 Azure 数据工厂实例(或数据工厂)。 Azure 数据工厂包括以下关键组件:
- Pipelines
- 活动
- 数据集
- 链接服务
- 数据流
- 集成运行时
这些组件组合起来提供一个平台,供你在上面编写数据驱动型工作流(其中包含用来移动和转换数据的步骤)。
管道
数据工厂可以包含一个或多个管道。 管道是执行任务单元的活动的逻辑分组。 管道中的活动共同执行一项任务。 例如,一个管道可能包含一组活动,这些活动从 Azure Blob 引入数据,然后在 HDInsight 群集上运行 Hive 查询,以便对数据分区。
这样做的好处是,管道允许您对活动进行集合管理,而不是要单独管理每个活动。 管道中的活动可以链接在一起来按顺序执行,也可以独立并行执行。
映射数据流
创建和管理可用于转换任何大小的数据的数据转换逻辑图。 可以构建可重用的数据转换例程库,并通过Azure 数据工厂管道以横向扩展的方式执行这些进程。 Azure 数据工厂在 Spark 群集上运行逻辑,该群集根据需要启动和向下旋转。 你永远不必管理和维护群集。
活动
活动表示管道中的处理步骤。 例如,可以使用复制活动将数据从一个数据存储复制到另一个数据存储。 同样,你可以使用在 Azure HDInsight 集群上运行 Hive 查询的 Hive 活动来转换或分析你的数据。 数据工厂支持三种类型的活动:数据移动活动、数据转换活动和控制活动。
数据集
数据集表示数据存储中的数据结构,这些结构指向或引用要在活动中使用的数据作为输入和输出。
链接服务
链接服务十分类似于连接字符串,用于定义数据工厂连接到外部资源时所需的连接信息。 不妨这样考虑:链接服务定义到数据源的连接,而数据集则代表数据的结构。 例如,Azure 存储链接服务指定连接到 Azure 存储帐户所需的连接字符串。 另外,Azure Blob 数据集指定 Blob 容器以及包含数据的文件夹。
数据工厂中的链接服务有两个用途:
代表数据存储,此类存储包括但不限于 SQL Server 数据库、Oracle 数据库、文件共享或 Azure blob 存储帐户。 有关支持的数据存储的列表,请参阅复制活动一文。
代表可托管活动执行的计算资源。 例如,HDInsightHive 活动在 HDInsight Hadoop 群集上运行。 有关转换活动列表和支持的计算环境,请参阅转换数据一文。
Integration Runtime
在数据工厂中,活动定义要执行的操作。 链接服务定义目标数据存储或计算服务。 集成运行时提供活动和链接服务之间的桥梁。 它被链接服务或活动引用,提供运行或分派活动的计算环境。 这样一来,可以在最接近目标数据存储的区域中执行活动,或者,以最优性能计算服务的同时满足安全和合规性需求。
触发器
触发器代表处理单元,用于确定何时需要启动管道执行。 不同类型的事件有不同类型的触发器类型。
管道运行
管道运行是管道执行的一个实例。 管道运行通常是通过将自变量传递给管道中定义的参数来实例化的。 自变量可手动传递,也可在触发器定义中传递。
参数
参数是只读配置的键值对。 参数是在管道中定义的。 定义的参数的自变量是在执行期间从由触发器创建的运行上下文或手动执行的管道传递的。 管道中的活动消费参数值。
数据集是强类型参数和可重用/可引用的实体。 活动可以引用数据集并且可以使用数据集定义中所定义的属性。
链接服务也是强类型参数,其中包含数据存储或计算环境的连接信息。 它也是可重用/可引用的实体。
控制流
控制流是管道活动的业务流程,包括将活动按顺序链接起来、设置分支。可以在管道级别定义参数,在按需或者通过触发器调用管道时传递自变量。 它还包括自定义状态传递和循环容器,即 For-each 迭代器。
变量
可以在管道内部使用变量来存储临时值,还可以将这些变量与参数结合使用,以在管道、数据流和其他活动之间传递值。
相关内容
请阅读以下重要后续步骤文档: