适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
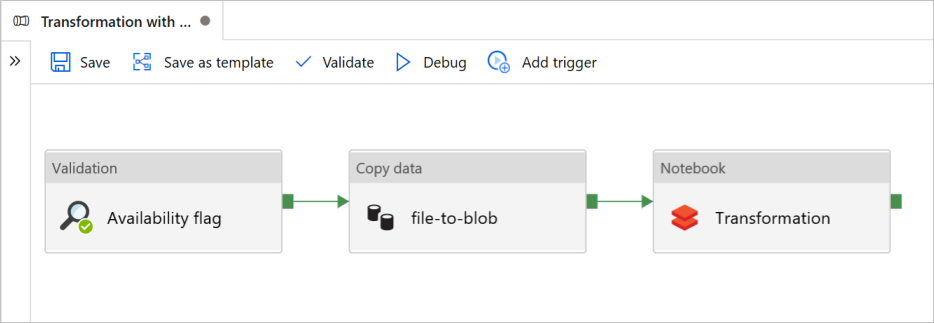
在本教程中,你将在数据工厂中创建包含“验证”、“复制数据”和“笔记本”活动的端到端管道。
“验证”确保你的源数据集在你触发复制和分析作业之前已准备好供下游消耗。
“复制数据”将源数据集复制到接收器存储,该存储在 Azure Databricks 笔记本中装载为 DBFS。 这样,Spark 就可以直接使用该数据集。
“Notebook” 触发了将数据集进行转换的 Databricks 笔记本。 它还会将数据集添加到处理后的文件夹或 Azure Synapse Analytics 中。
为简单起见,本教程中的模板没有创建计划的触发器。 如有必要,你可以添加一个。
先决条件
一个 Azure Blob 存储帐户,其中包含用作接收器的名为
sinkdata的容器。记下存储帐户名称、容器名称和访问密钥。 稍后在模板中需要使用这些值。
一个 Azure Databricks 工作区。
导入用于转换的笔记本
若要将转换笔记本导入到 Databricks 工作区,请执行以下操作:
登录到你的 Azure Databricks 工作区。
右键单击工作区中的文件夹,然后选择“导入”。
选择“导入自:URL”。 在文本框中,输入
https://adflabstaging1.blob.core.windows.net/share/Transformations.html。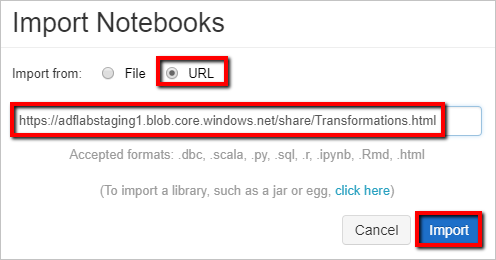
现在,让我们使用你的存储连接信息来更新Transformation笔记本。
在导入的笔记本中,转到 command 5,如下面的代码片段所示。
- 将
<storage name>和<access key>替换为你自己的存储连接信息。 - 使用具有
sinkdata容器的存储帐户。
# Supply storageName and accessKey values storageName = "<storage name>" accessKey = "<access key>" try: dbutils.fs.mount( source = "wasbs://sinkdata\@"+storageName+".blob.core.chinacloudapi.cn/", mount_point = "/mnt/Data Factorydata", extra_configs = {"fs.azure.account.key."+storageName+".blob.core.chinacloudapi.cn": accessKey}) except Exception as e: # The error message has a long stack track. This code tries to print just the relevant line indicating what failed. import re result = re.findall(r"\^\s\*Caused by:\s*\S+:\s\*(.*)\$", e.message, flags=re.MULTILINE) if result: print result[-1] \# Print only the relevant error message else: print e \# Otherwise print the whole stack trace.- 将
为 Data Factory 生成Databricks 访问令牌以访问 Databricks。
- 在 Azure Databricks 工作区中,在顶部栏中选择 Azure Databricks 用户名,然后从下拉列表中选择“设置”。
- 选择 “开发人员”。
- 紧邻“访问令牌”旁边,选择“管理”。
- 选择“生成新令牌”。
- (可选)输入一个注释,帮助你将来识别此令牌,并更改令牌的默认生存期 90 天。 若要创建没有生存期的令牌(不建议),请将“生存期(天)”框留空(保留空白)。
- 选择生成。
- 将显示的令牌复制到安全位置,然后选择“完成”。
保存访问令牌,以便稍后将其用于创建 Databricks 链接服务。 访问令牌类似于 dapi32db32cbb4w6eee18b7d87e45exxxxxx。
如何使用此模板
转到使用 Azure Databricks 进行转换模板,为以下连接创建新的链接服务。
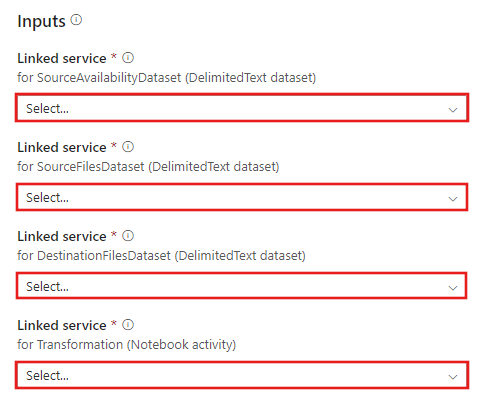
源 Blob 连接 - 用于访问源数据。
对于此练习,你可以使用包含源文件的公共 Blob 存储。 有关配置,请参考下面的屏幕截图。 使用以下 SAS URL 连接到源存储(只读访问):
https://storagewithdata.blob.core.windows.net/data?sv=2018-03-28&si=read%20and%20list&sr=c&sig=PuyyS6%2FKdB2JxcZN0kPlmHSBlD8uIKyzhBWmWzznkBw%3D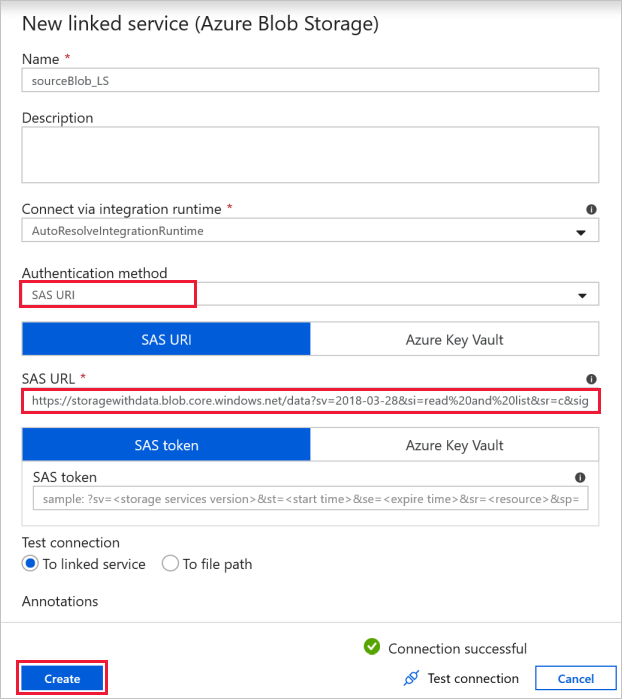
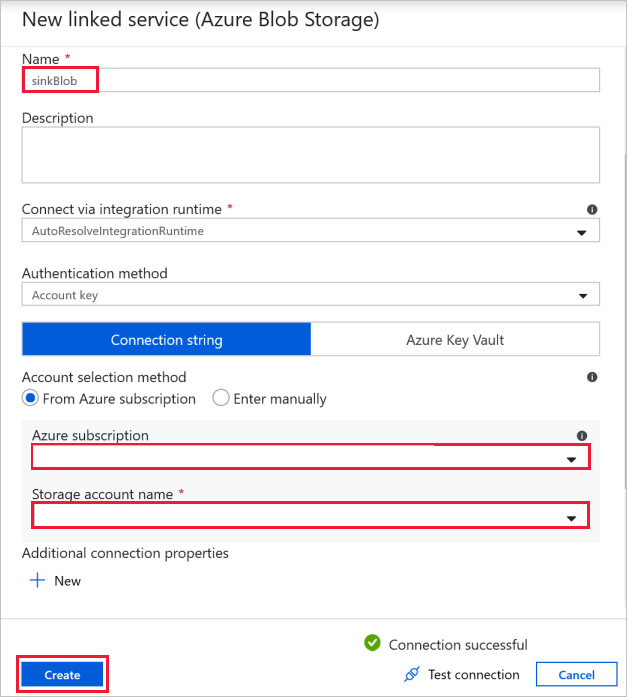
目标 Blob 连接 - 用于存储复制的数据。
在“新建链接服务”窗口中,选择你的接收器存储 blob。
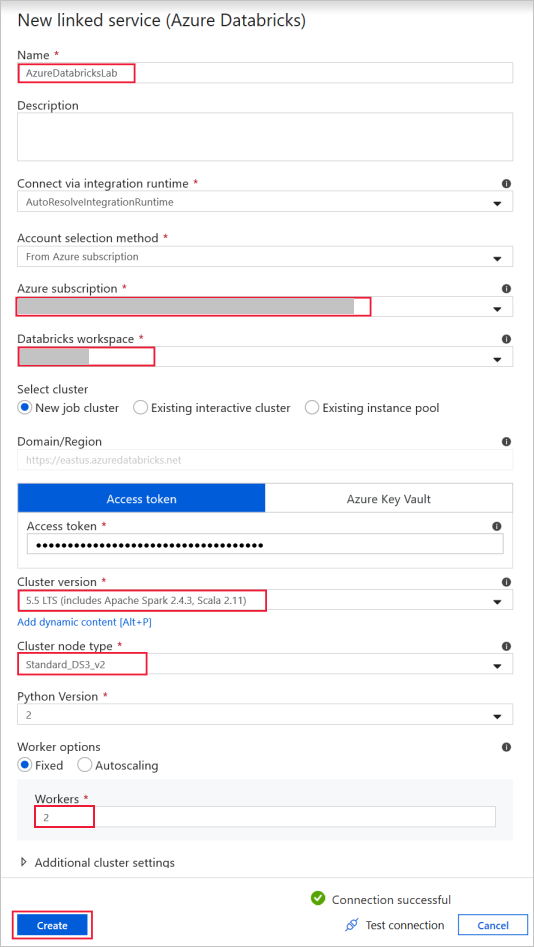
Azure Databricks - 用于连接到 Databricks 群集。
使用之前生成的访问密钥创建 Databricks 链接服务。 你还可以选择一个“交互式群集”(如果有)。 此示例使用“新建作业群集”选项。
选择“使用此模板” 。 你将会看到一个被创建的管道。
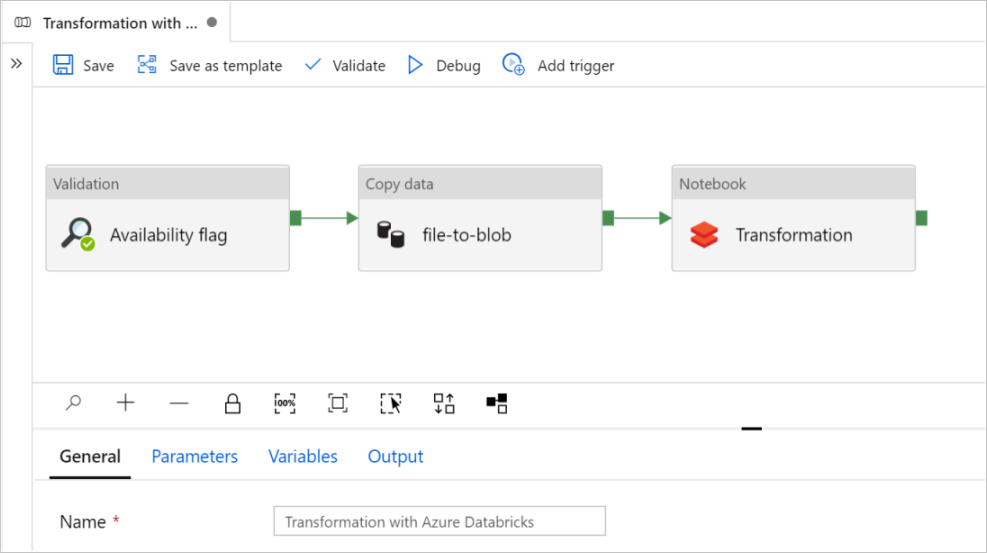
管道简介和配置
在新管道中,大多数设置都自动配置为默认值。 请查看管道的配置,并进行任何必要的更改。
在验证活动的可用性标志中,检查源数据集值是否设置为你之前创建的
SourceAvailabilityDataset。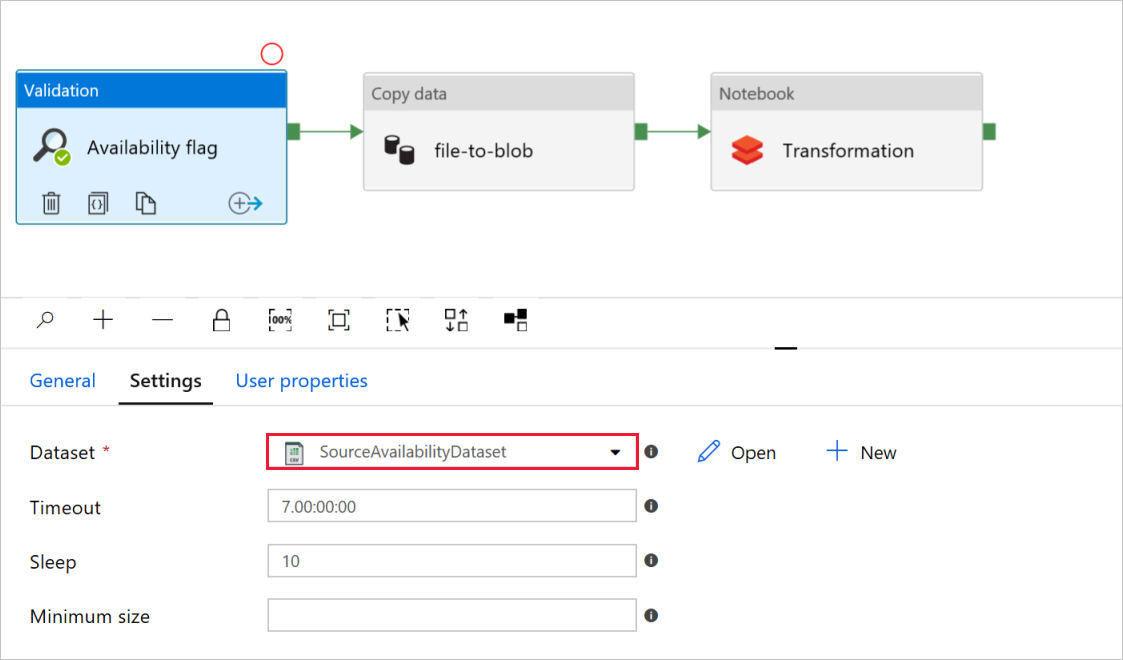
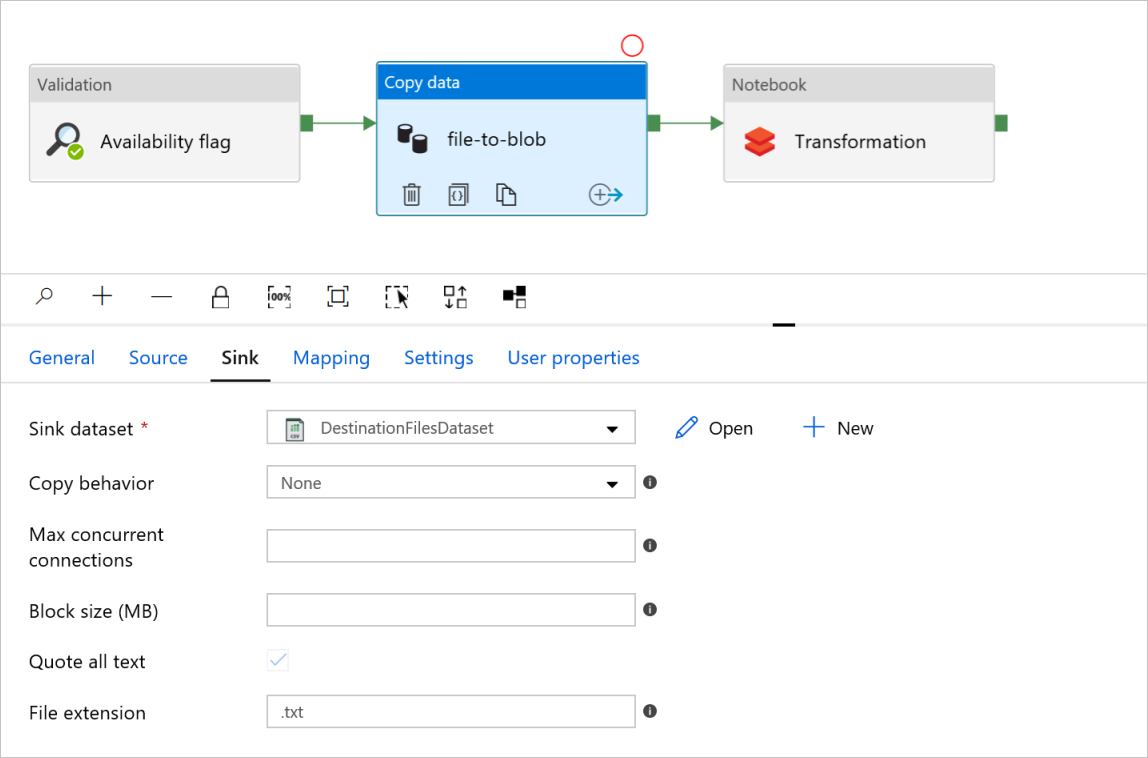
在“复制数据”活动中的“文件到 blob”中,检查“源”和“汇聚”选项卡。 如有必要,请更改设置。
“源”选项卡Source tab
接收器选项卡
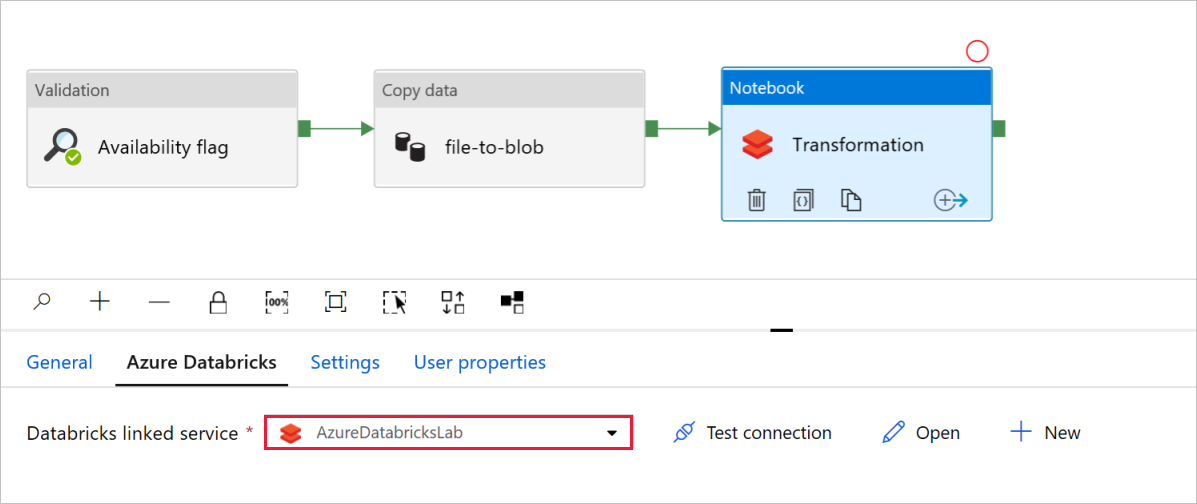
在“笔记本”活动的“转换”中,查看并根据需要更新路径和设置。
“Databricks 链接服务” 应当预先填充前面步骤中的值,如下所示:
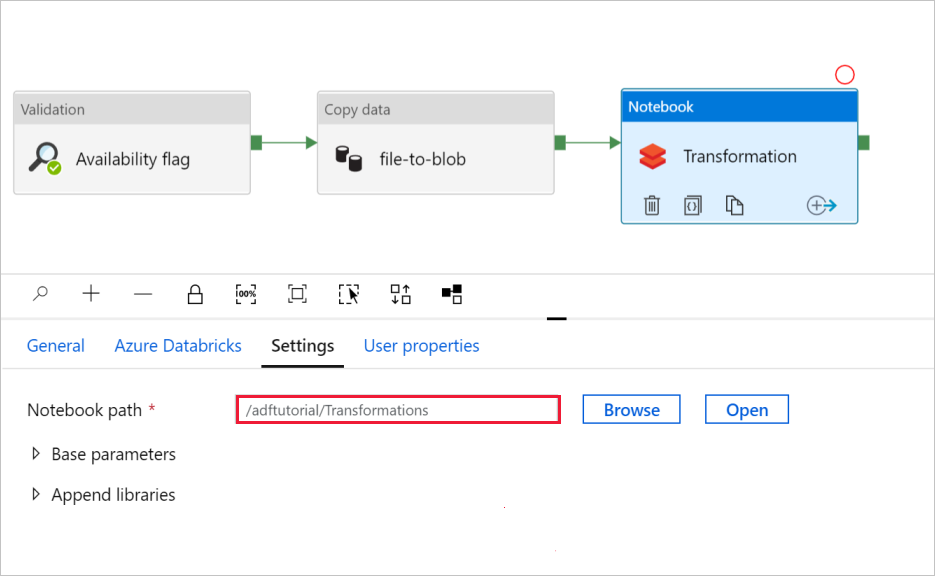
若要检查“笔记本”设置,请执行以下操作:
选择“设置”选项卡。对于“笔记本路径”,请验证默认路径是否正确。 你可能需要浏览并选择正确的笔记本路径。
展开“基参数”选择器,验证参数是否与以下屏幕截图中显示的内容匹配。 这些参数将从数据工厂传递到 Databricks 笔记本。
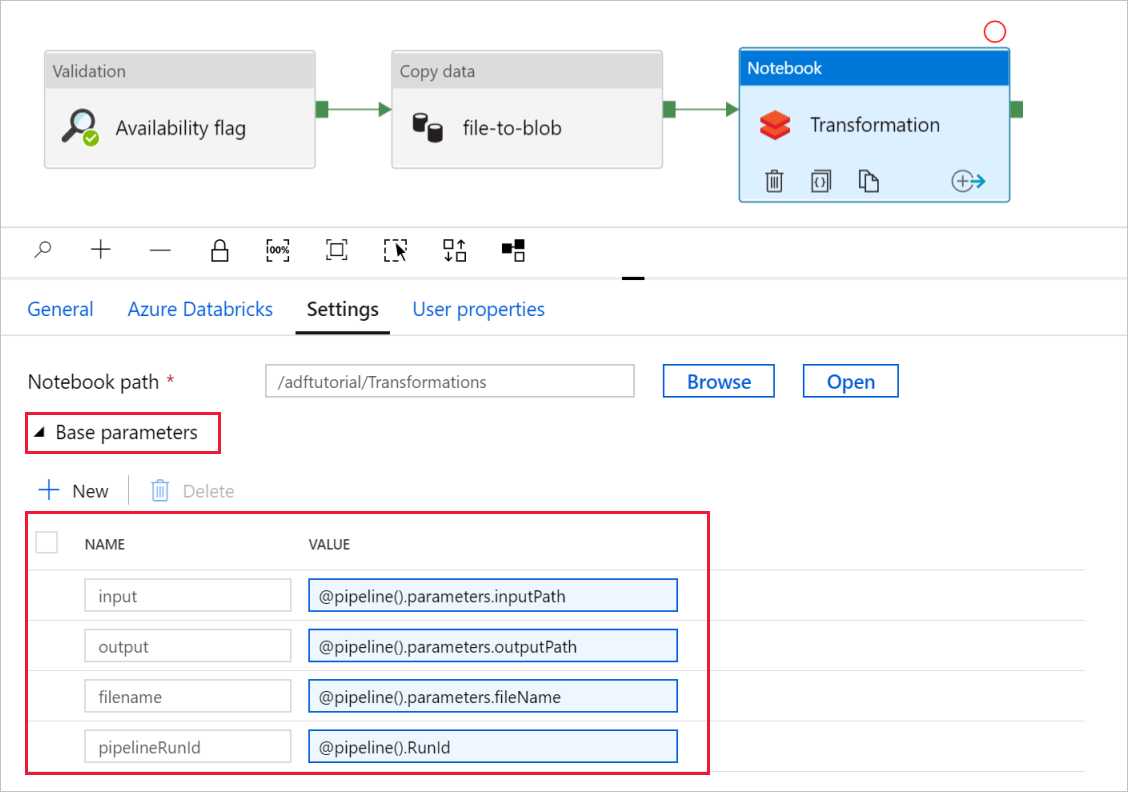
验证管道参数是否与以下屏幕截图中显示的内容相匹配:
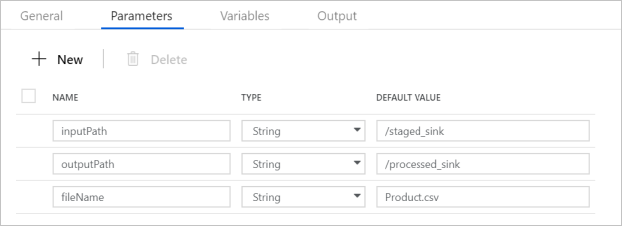
连接到你的数据集。
注意
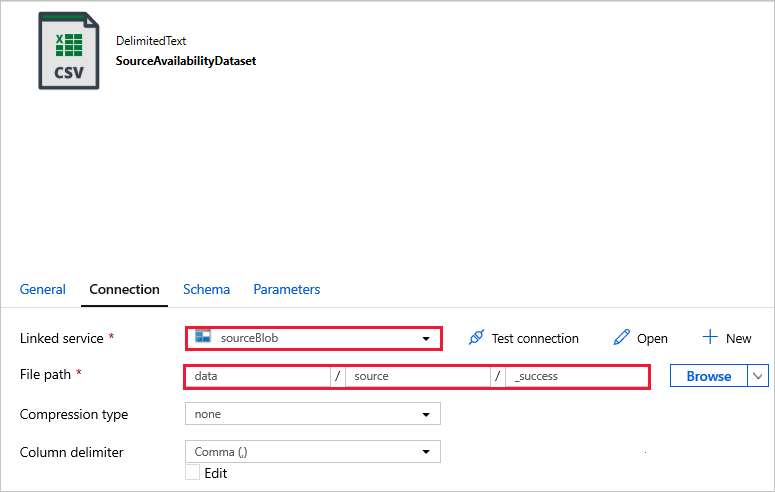
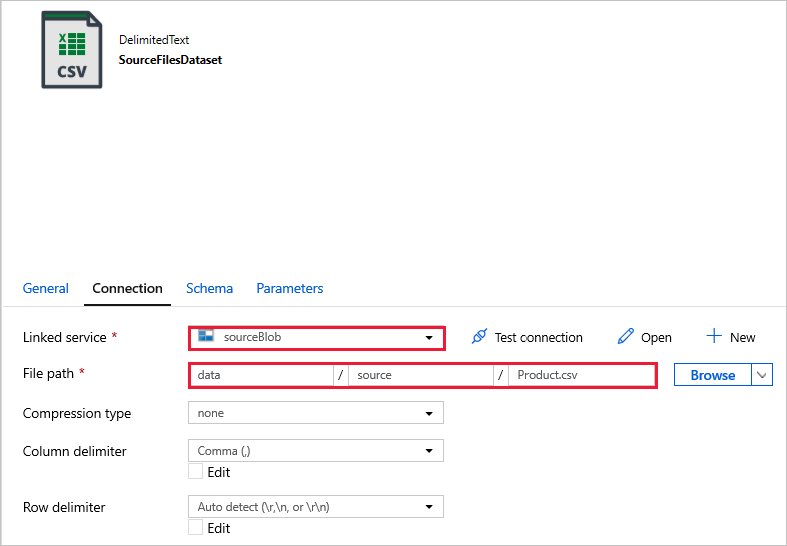
在下面的数据集内,已在模板中自动指定了文件路径。 当出现任何连接错误时,如果需要进行任何更改,请确保同时为“容器”和“目录”指定路径。
SourceAvailabilityDataset - 用于检查源数据是否可用。
SourceFilesDataset - 用于访问源数据。
DestinationFilesDataset - 用于将数据复制到接收器目标位置。 使用以下值:
链接服务 -
sinkBlob_LS,在前面的步骤中创建。文件路径 -
sinkdata/staged_sink。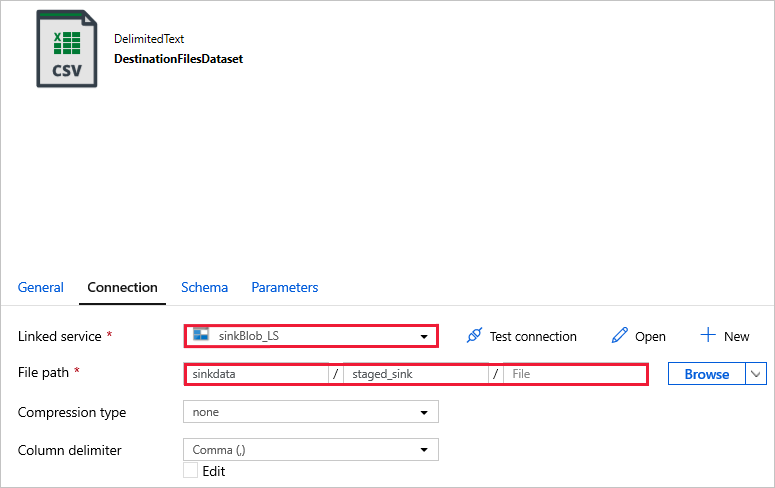
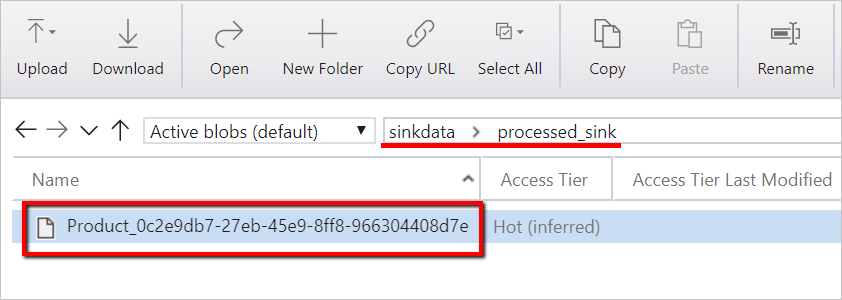
选择“调试”以运行管道。 可以找到 Databricks 日志的链接以获取更详细的 Spark 日志。
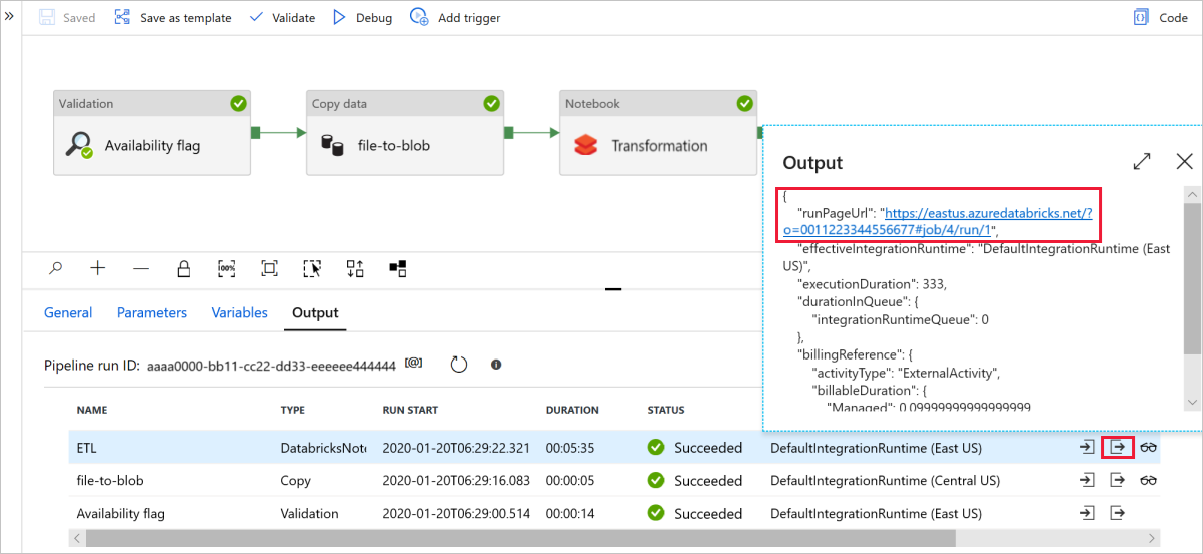
还可以使用 Azure 存储资源管理器验证数据文件。
注意
为了与 Data Factory 管道运行相关联,此示例将 Data Factory 的管道运行 ID 附加到输出文件夹。 这有助于跟踪每次运行生成的文件。