重要
旧查询联合文档已停用,可能不会更新。 此内容中提到的配置未经 Databricks 正式认可或测试。 如果 Lakehouse 联邦 支持源数据库,Databricks 建议改用它。
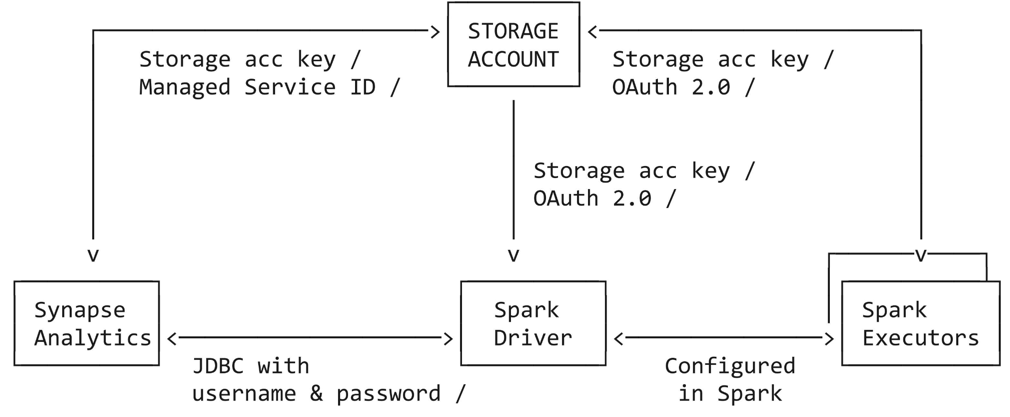
本教程会指导你完成所需的全部步骤,以便使用服务主体、Azure 托管服务标识 (MSI) 和 SQL 身份验证,从 Azure Databricks 连接到 Azure Synapse Analytics 专用池。 Azure Synapse 连接器使用三种类型的网络连接:
- 将 Spark 驱动程序连接到 Azure Synapse
- Spark 驱动程序和执行程序到 Azure 存储帐户
- Azure Synapse 到 Azure 存储帐户
要求
在开始本教程之前,完成以下任务:
- 创建 Azure Databricks 工作区。 请参阅 使用 Azure 门户部署工作区
- 创建 Azure Synapse Analytics 工作区。 参阅快速入门:创建 Synapse 工作区
- 创建专用 SQL 池。 请参阅快速入门:使用 Azure 门户创建专用 SQL 池
- 为 Azure Databricks 和 Azure Synapse Analytics 之间的连接创建暂存 Azure Data Lake Storage。
使用服务主体连接到 Azure Synapse Analytics
本教程中的以下步骤演示如何使用服务主体,连接到 Azure Synapse Analytics。
步骤 1:为 Azure Data Lake Storage 创建Microsoft Entra ID 服务主体
若要使用服务主体连接到 Azure Data Lake Gen2,管理员用户必须创建新的 Microsoft Entra ID(以前称为 Azure Active Directory)应用程序。 如果已有可用的 Microsoft Entra ID 服务主体,请跳到步骤 3。 若要创建 Microsoft Entra ID 服务主体,请按照以下说明操作:
登录到 Azure 门户。
如果有权访问多个租户、订阅或目录,请单击顶部菜单中的“目录 + 订阅”(目录包含筛选器)图标,以切换到要预配服务主体的目录。
搜索并选择 Microsoft Entra ID。
在“管理”中,单击“应用注册”“新建注册”。
在名称字段中,输入应用程序的名称。
在“支持的帐户类型”部分中,选择“仅组织目录中的帐户(单一租户)”。
单击“注册”。
(可选)步骤 2:为 Azure Synapse Analytics 创建 Microsoft Entra ID 服务主体
可以选择重复步骤 1 中的说明,创建 Azure Synapse Analytics 专用的服务主体。 如果不创建单独的服务主体凭据集,连接将使用同一服务主体连接到 Azure Data Lake Gen2 和 Azure Synapse Analytics。
步骤 3:为 Azure Data Lake Gen2(和 Azure Synapse Analytics)服务主体创建客户端密码
在“管理”中,单击“证书和机密”
在“客户端密码”选项卡上,单击“新建客户端密码” 。
在添加客户端机密窗格中的说明,输入有关客户端机密的说明。
对于 Expires,请选择客户端密钥的过期时间段,然后单击 添加。
复制客户端密码的“值”并将其存储在安全位置,因为此客户端密码是应用程序的密码。
在应用程序页的“概述”页上的“概要”部分中,复制以下值:
- 应用程序(客户端)ID
- 目录(租户)ID
注释
如果为 Azure Synapse Analytics 创建了一组服务主体凭据,请再次按照以下步骤创建客户端密码。
步骤 4:授予服务主体对 Azure Data Lake Storage 的访问权限
通过为服务主体分配角色来授予对存储资源的访问权限。 在本教程中,将 存储 Blob 数据参与者 分配给 Azure Data Lake Storage 帐户上的服务主体。 可能需要根据特定要求分配其他角色。
在 Azure 门户中,转到“存储帐户”服务。
选择要使用的 Azure 存储帐户。
单击“访问控制(IAM)”。
单击“+ 添加”,然后从下拉菜单中选择“添加角色分配” 。
将 “选择” 字段设置为在步骤 1 中创建的Microsoft Entra ID 应用程序名称,并将“角色”设置为 “存储 Blob 数据参与者”。
单击“ 保存”。
注释
如果为 Azure Synapse Analytics 创建了一组服务主体凭据,请按照步骤再次授予对 Azure Data Lake Storage 上的服务主体的访问权限。
步骤 5:在 Azure Synapse Analytics 专用池中创建主密钥
连接到 Azure Synapse Analytics 专用池,如果之前未创建主密钥,请进行创建。
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<Password>'
步骤 6:向 Azure Synapse Analytics 专用池中的服务主体授予权限
连接到 Azure Synapse Analytics 专用池,并为服务主体创建一个外部用户,该用户将连接到由世纪互联运营的 Microsoft Azure Synapse Analytics:
CREATE USER <serviceprincipal> FROM EXTERNAL PROVIDER
注释
服务主体的名称应与在步骤 2 中创建的服务主体一致(如果跳过为 Azure Synapse Analytics 创建专用服务主体,则应为步骤 1 中创建的服务主体)。
运行以下命令,向服务主体授予db_owner的权限:
sp_addrolemember 'db_owner', '<serviceprincipal>'
授予能够插入现有表所需的权限:
GRANT ADMINISTER DATABASE BULK OPERATIONS TO <serviceprincipal>
GRANT INSERT TO <serviceprincipal>
(可选)授予能够插入新表所需的权限:
GRANT CREATE TABLE TO <serviceprincipal>
GRANT ALTER ON SCHEMA ::dbo TO <serviceprincipal>
步骤 7:示例语法:在 Azure Synapse Analytics 中查询并写入数据
可以在 Scala、Python、SQL 和 R 中查询 Synapse。以下代码示例使用存储帐户密钥并将存储凭据从 Azure Databricks 转发到 Synapse。
Scala(编程语言)
以下代码示例表示你必须:
- 在笔记本会话中设置存储帐户访问密钥
- 定义 Azure 存储帐户的服务主体凭据
- 为 Azure Synapse Analytics 定义一组单独的服务主体凭据(如果未定义,连接器将使用 Azure 存储帐户凭据)
- 从 Azure Synapse 表获取一些数据
- 从 Azure Synapse 的查询加载数据
- 对数据应用一些转换,然后使用数据源 API 将数据写回到 Azure Synapse 中的另一个表
import org.apache.spark.sql.DataFrame
// Set up the storage account access key in the notebook session
conf.spark.conf.set(
"fs.azure.account.key.<your-storage-account-name>.dfs.core.chinacloudapi.cn",
"<your-storage-account-access-key>")
// Define the service principal credentials for the Azure storage account
spark.conf.set("fs.azure.account.auth.type", "OAuth")
spark.conf.set("fs.azure.account.oauth.provider.type", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
spark.conf.set("fs.azure.account.oauth2.client.id", "<ApplicationId>")
spark.conf.set("fs.azure.account.oauth2.client.secret", "<SecretValue>")
spark.conf.set("fs.azure.account.oauth2.client.endpoint", "https://login.partner.microsoftonline.cn/<DirectoryId>/oauth2/token")
// Define a separate set of service principal credentials for Azure Synapse Analytics (If not defined, the connector will use the Azure storage account credentials)
spark.conf.set("spark.databricks.sqldw.jdbc.service.principal.client.id", "<ApplicationId>")
spark.conf.set("spark.databricks.sqldw.jdbc.service.principal.client.secret", "<SecretValue>")
// Get some data from an Azure Synapse table
val df: DataFrame = spark.read
.format("com.databricks.spark.sqldw")
.option("url", "jdbc:sqlserver://<the-rest-of-the-connection-string>")
.option("tempDir", "abfss://<your-container-name>@<your-storage-account-name>.dfs.core.chinacloudapi.cn/<your-directory-name>")
.option("enableServicePrincipalAuth", "true")
.option("dbTable", "dbo.<your-table-name>")
.load()
// Load data from an Azure Synapse query
val df1: DataFrame = spark.read
.format("com.databricks.spark.sqldw")
.option("url", "jdbc:sqlserver://<the-rest-of-the-connection-string>")
.option("tempDir", "abfss://<your-container-name>@<your-storage-account-name>.dfs.core.chinacloudapi.cn/<your-directory-name>")
.option("enableServicePrincipalAuth", "true")
.option("query", "select * from dbo.<your-table-name>")
.load()
// Apply some transformations to the data, then use the
// Data Source API to write the data back to another table in Azure Synapse
df1.write
.format("com.databricks.spark.sqldw")
.option("url", "jdbc:sqlserver://<the-rest-of-the-connection-string>")
.option("tempDir", "abfss://<your-container-name>@<your-storage-account-name>.dfs.core.chinacloudapi.cn/<your-directory-name>")
.option("enableServicePrincipalAuth", "true")
.option("dbTable", "dbo.<new-table-name>")
.save()
Python
以下代码示例表示你必须:
- 在笔记本会话中设置存储帐户访问密钥
- 定义 Azure 存储帐户的服务主体凭据
- 为 Azure Synapse Analytics 定义单独的服务主体凭据集
- 从 Azure Synapse 表获取一些数据
- 从 Azure Synapse 查询加载数据
- 对数据应用一些转换,然后使用数据源 API 将数据写回到 Azure Synapse 中的另一个表
SQL
以下代码示例表示你必须:
- 定义 Azure 存储帐户的服务主体凭据
- 为 Azure Synapse Analytics 定义单独的服务主体凭据集
- 在笔记本会话中设置存储帐户访问密钥
- 使用 SQL 读取数据
- 使用 SQL 写入数据
# Define the Service Principal credentials for the Azure storage account
fs.azure.account.auth.type OAuth
fs.azure.account.oauth.provider.type org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider
fs.azure.account.oauth2.client.id <application-id>
fs.azure.account.oauth2.client.secret <service-credential>
fs.azure.account.oauth2.client.endpoint https://login.partner.microsoftonline.cn/<directory-id>/oauth2/token
## Define a separate set of service principal credentials for Azure Synapse Analytics (If not defined, the connector will use the Azure storage account credentials)
spark.databricks.sqldw.jdbc.service.principal.client.id <application-id>
spark.databricks.sqldw.jdbc.service.principal.client.secret <service-credential>
# Set up the storage account access key in the notebook session
conf.SET fs.azure.account.key.<your-storage-account-name>.dfs.core.chinacloudapi.cn=<your-storage-account-access-key>
-- Read data using SQL
CREATE TABLE df
USING com.databricks.spark.sqldw
OPTIONS (
url 'jdbc:sqlserver://<the-rest-of-the-connection-string>',
'enableServicePrincipalAuth' 'true',
dbtable 'dbo.<your-table-name>',
tempDir 'abfss://<your-container-name>@<your-storage-account-name>.dfs.core.chinacloudapi.cn/<your-directory-name>'
);
-- Write data using SQL
-- Create a new table, throwing an error if a table with the same name already exists:
CREATE TABLE df1
USING com.databricks.spark.sqldw
OPTIONS (
url 'jdbc:sqlserver://<the-rest-of-the-connection-string>',
'enableServicePrincipalAuth' 'true',
dbTable 'dbo.<new-table-name>',
tempDir 'abfss://<your-container-name>@<your-storage-account-name>.dfs.core.chinacloudapi.cn/<your-directory-name>'
)
AS SELECT * FROM df1
R
以下代码示例表示你必须:
- 在笔记本会话 conf 中设置存储帐户访问密钥
- 定义 Azure 存储帐户的服务主体凭据
- 为 Azure Synapse Analytics 定义一组单独的服务主体凭据(如果未定义,连接器将使用 Azure 存储帐户凭据)
- 从 Azure Synapse 表获取一些数据
- 对数据应用一些转换,然后使用数据源 API 将数据写回到 Azure Synapse 中的另一个表
# Load SparkR
library(SparkR)
# Set up the storage account access key in the notebook session conf
conf <- sparkR.callJMethod(sparkR.session(), "conf")
sparkR.callJMethod(conf, "set", "fs.azure.account.key.<your-storage-account-name>.dfs.core.chinacloudapi.cn", "<your-storage-account-access-key>")
# Load SparkR
library(SparkR)
conf <- sparkR.callJMethod(sparkR.session(), "conf")
# Define the service principal credentials for the Azure storage account
sparkR.callJMethod(conf, "set", "fs.azure.account.auth.type", "OAuth")
sparkR.callJMethod(conf, "set", "fs.azure.account.oauth.provider.type", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
sparkR.callJMethod(conf, "set", "fs.azure.account.oauth2.client.id", "<ApplicationId>")
sparkR.callJMethod(conf, "set", "fs.azure.account.oauth2.client.secret", "<SecretValue>")
sparkR.callJMethod(conf, "set", "fs.azure.account.oauth2.client.endpoint", "https://login.partner.microsoftonline.cn/<DirectoryId>/oauth2/token")
# Define a separate set of service principal credentials for Azure Synapse Analytics (If not defined, the connector will use the Azure storage account credentials)
sparkR.callJMethod(conf, "set", "spark.databricks.sqldw.jdbc.service.principal.client.id", "<ApplicationId>")
sparkR.callJMethod(conf, "set", "spark.databricks.sqldw.jdbc.service.principal.client.secret", "SecretValue>")
# Get some data from an Azure Synapse table
df <- read.df(
source = "com.databricks.spark.sqldw",
url = "jdbc:sqlserver://<the-rest-of-the-connection-string>",
tempDir = "abfss://<your-container-name>@<your-storage-account-name>.dfs.core.chinacloudapi.cn/<your-directory-name>",
enableServicePrincipalAuth = "true",
dbTable = "dbo.<your-table-name>")
# Load data from an Azure Synapse query.
df <- read.df(
source = "com.databricks.spark.sqldw",
url = "jdbc:sqlserver://<the-rest-of-the-connection-string>",
tempDir = "abfss://<your-container-name>@<your-storage-account-name>.dfs.core.chinacloudapi.cn/<your-directory-name>",
enableServicePrincipalAuth = "true",
query = "Select * from dbo.<your-table-name>")
# Apply some transformations to the data, then use the
# Data Source API to write the data back to another table in Azure Synapse
write.df(
df,
source = "com.databricks.spark.sqldw",
url = "jdbc:sqlserver://<the-rest-of-the-connection-string>",
tempDir = "abfss://<your-container-name>@<your-storage-account-name>.dfs.core.chinacloudapi.cn/<your-directory-name>",
enableServicePrincipalAuth = "true",
dbTable = "dbo.<new-table-name>")
故障排除
以下部分介绍可能会遇到的错误消息,及其可能的含义。
服务主体凭证不以用户的身份存在
com.microsoft.sqlserver.jdbc.SQLServerException: Login failed for user '<token-identified principal>'
上述错误可能意味着服务主体凭证不作为用户存在于 Synapse Analytics 工作区中。
在 Azure Synapse Analytics 专用池中运行以下命令,以创建外部用户:
CREATE USER <serviceprincipal> FROM EXTERNAL PROVIDER
服务主体凭证的 SELECT 权限不足
com.microsoft.sqlserver.jdbc.SQLServerException: The SELECT permission was denied on the object 'TableName', database 'PoolName', schema 'SchemaName'. [ErrorCode = 229] [SQLState = S0005]
上述错误可能意味着服务主体凭证在 Azure Synapse Analytics 专用池中没有足够的 SELECT 权限。
在 Azure Synapse Analytics 专用池中运行以下命令,以授予 SELECT 权限:
GRANT SELECT TO <serviceprincipal>
服务主体凭证没有权限使用 COPY
com.microsoft.sqlserver.jdbc.SQLServerException: User does not have permission to perform this action. [ErrorCode = 15247] [SQLState = S0001]
上述错误可能意味着服务主体凭证在 Azure Synapse Analytics 专用池中没有足够的权限来使用 COPY。 服务主体需要不同的权限,这取决于具体的操作是插入到现有表中还是插入到新表中。 确保服务主体具有所需的 Azure Synapse 权限。
注释
服务主体不是 Azure Synapse Analytics 专用池的 db_owner。
在 Azure Synapse Analytics 专用池中运行以下命令,授予 db_owner 权限:
sp_addrolemember 'db_owner', 'serviceprincipal'
专用池中没有主密钥
com.microsoft.sqlserver.jdbc.SQLServerException: Please create a master key in the database or open the master key in the session before performing this operation. [ErrorCode = 15581] [SQLState = S0006]
上述错误可能意味着 Azure Synapse Analytics 专用池中没有主密钥。
在 Azure Synapse Analytics 中创建主密钥,以解决此问题。
服务主体凭证的写入权限不足
com.microsoft.sqlserver.jdbc.SQLServerException: CREATE EXTERNAL TABLE AS SELECT statement failed as the path name '' could not be used for export. Please ensure that the specified path is a directory which exists or can be created, and that files can be created in that directory. [ErrorCode = 105005] [SQLState = S0001]
上述错误可能意味着:
服务主体凭证没有足够的权限进行 PolyBase 写入操作
临时存储帐户没有 Azure Data Lake Storage 功能。
服务主体/托管服务标识在 Azure 数据湖存储上没有“存储 Blob 数据贡献者”角色。
请参阅对 Azure Blob 存储执行 CETAS 操作时出现的错误 105005,以进一步排查问题。