声明性自动化捆绑包(以前称为 Databricks 资产捆绑包)是一种工具,有助于采用软件工程最佳做法,包括源代码管理、代码评审、测试和持续集成和交付(CI/CD),用于数据和 AI 项目。 捆绑包提供了一种将元数据与项目的源文件一起包含的方法,并使它能够将 Databricks 资源(如作业和管道)描述为源文件。 最终,捆绑包是项目的端到端定义,包括项目的结构、测试和部署方式。 在积极开发期间,这有助于更轻松地协作处理项目。
捆绑项目的源文件和元数据集合作为单个捆绑包部署到目标环境。 捆绑包包括下列部分:
- 所需的云基础结构和工作区配置
- 包含业务逻辑的源文件(例如笔记本和Python文件)
- Databricks 资源的定义和设置,例如 Lakeflow 任务、Lakeflow Spark 声明性流水线、仪表板、模型提供服务端点、MLflow 实验和 MLflow 注册的模型
- 单元测试和集成测试
下图提供了使用捆绑包的开发和 CI/CD 管道的概要视图:
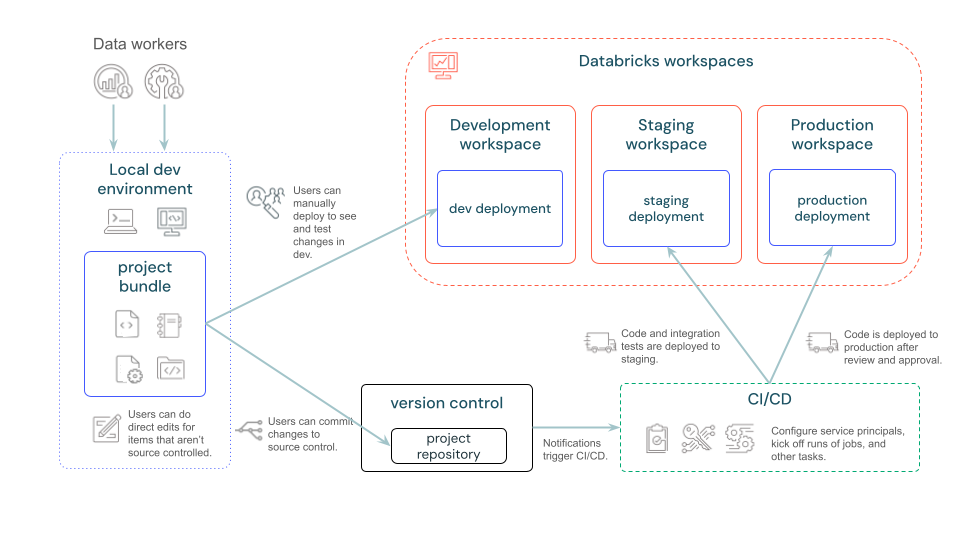
何时应使用捆绑包?
声明性自动化捆绑包是一种基础结构即代码 (IaC) 方法来管理 Databricks 项目。 如果要管理的复杂项目必须涉及多个参与者和自动化,并且需要进行持续集成和部署 (CI/CD),则可使用它们。 由于捆绑包是通过与源代码一起创建和维护的 YAML 模板和文件来定义和管理的,因此它们与采用 IaC 方法的场景非常契合。
理想的捆绑包示例包括:
- 在基于团队的环境中开发数据、分析和 ML 项目。 捆绑包可帮助你高效地组织和管理各种源文件。 这可确保顺畅协作和简化的过程。
- 更快地迭代优化 ML 问题。 使用符合生产最佳实践的 ML 项目,从一开始就管理 ML 管道资源,例如训练和批量推理任务。
- 通过创作包含默认权限、服务主体和 CI/CD 配置的自定义捆绑模板,为新项目设置组织标准。
- 法规合规性:在法规合规性非常重要的行业,捆绑包可以帮助维护代码和基础结构工作的版本历史记录。 这有助于治理,并确保满足必要的合规性标准。
捆绑包的工作原理是什么?
捆绑包元数据是使用 YAML 文件定义的,该文件指定了 Databricks 项目的生成工件、资源和配置。 然后,可将 Databricks CLI 用于使用这些捆绑 YAML 文件验证、部署和运行捆绑包。 可以直接从 IDE、终端或 Databricks 中运行捆绑项目。
捆绑包可以手动创建,也可以基于模板创建。 Databricks CLI 为简单用例提供了默认模板,但对于更具体或复杂的作业,可以创建自定义捆绑模板来实现团队的最佳做法,并保持常见配置一致。
有关用于表示声明性自动化捆绑包的配置 YAML 的更多详细信息,请参阅 声明性自动化捆绑包配置。
我需要安装什么才能使用捆绑包?
声明性自动化捆绑包是 Databricks CLI 的一项功能。 在本地生成捆绑包,然后使用 Databricks CLI 将捆绑包部署到面向远程 Databricks 工作区,并从命令行在这些工作区中运行捆绑工作流。
注释
如果只想在工作区中使用捆绑包,则无需安装 Databricks CLI。 请参阅在工作区中协作处理捆绑包。
若要在Azure Databricks工作区中生成、部署和运行捆绑包:
远程 Databricks 工作区必须启用工作区文件。 如果使用的是 Databricks Runtime 版本 11.3 LTS 或更高版本,则默认情况下已启用此功能。
必须安装 Databricks CLI 版本 v0.218.0 或更高版本。 若要安装或更新 Databricks CLI,请参阅 安装或更新 Databricks CLI。
Databricks 建议定期更新到最新版本的 CLI,以利用 新的捆绑包功能。 若要查找已安装的 Databricks CLI 版本,请运行以下命令:
databricks --version已将 Databricks CLI 配置为访问 Databricks 工作区。 Databricks 建议使用 OAuth 用户到计算机(U2M)身份验证配置访问权限,如 配置工作区访问权限中所述。 声明性自动化捆绑包的身份验证中介绍了其他身份验证方法。
如何开始使用捆绑包?
启动本地捆绑包开发的最快方法是使用捆绑包项目模板。 使用 Databricks CLI bundle init 命令创建第一个捆绑包项目。 此命令提供了 Databricks 提供的默认捆绑包模板选择,并询问一系列初始化项目变量的问题。
databricks bundle init
创建捆绑包是捆绑包生命周期中的第一步。 接下来,通过定义 databricks.yml 中的捆绑包设置和资源以及资源配置文件来开发捆绑包。 最后, 验证 并 部署 捆绑包,然后 运行工作流。
提示
可以在
后续步骤
- 创建将笔记本部署到Azure Databricks工作区的捆绑包,然后在Azure Databricks作业或管道中运行部署的笔记本。 请参阅 使用声明性自动化捆绑包开发作业 ,以及 使用声明性自动化捆绑包开发管道。
- 创建用于部署和运行 MLOps Stack 的捆绑包。 请参阅 MLOps Stack 的声明性自动化捆绑包。
- 在GitHub中启动捆绑部署,作为 CI/CD(持续集成/持续部署)工作流的一部分。 请参阅使用运行管道更新的捆绑包运行 CI/CD 工作流。
- 创建一个捆绑包,用于生成、部署和调用Python wheel 文件。 请参阅 使用声明性自动化捆绑包生成Python wheel 文件。
- 在捆绑包中为工作区中的作业或其他资源生成配置,然后将其绑定到工作区中的资源,以便配置保持同步。请参阅 databricks 捆绑包生成 和 databricks 捆绑包部署绑定。
- 在工作区中创建和部署捆绑包。 请参阅在工作区中协作处理捆绑包。
- 创建自定义模板,你和其他人可以使用该模板创建捆绑包。 自定义模板可能包括默认权限、服务主体和自定义 CI/CD 配置。 请参阅 声明性自动化捆绑包项目模板。
- 从 dbx 迁移到声明式自动化组件包。 请参阅从 dbx 迁移到捆绑包。
- 了解为声明性自动化捆绑包发布的最新主要新功能。 请参阅 声明性自动化捆绑包功能发行说明。