本文介绍如何在 Azure Databricks 中获取工作区、经典计算、仪表板、目录、模型、笔记本和作业标识符和 URL。
工作区实例名称、URL 和 ID
唯一的实例名称(也称为每个工作区的 URL)已分配给每个 Azure Databricks 部署。 它是完全限定的域名,用于登录到 Azure Databricks 部署和发出 API 请求。
Azure Databricks 工作区 是 Azure Databricks 平台运行的位置,可以在其中创建 Spark 群集和计划工作负荷。 工作区具有唯一的数字工作区 ID。
每个工作区的 URL
此唯一的每工作区 URL 采用以下格式:adb-<workspace-id>.<random-number>.databricks.azure.cn。 工作区 ID 紧跟在 adb- 的后面,在“圆点”(.) 的前面。 对于每个工作区的 URL https://adb-5555555555555555.19.databricks.azure.cn/:
-
工作区 URL 为
https://adb-5555555555555555.19.databricks.azure.cn/ -
实例名称为
adb-5555555555555555.19.databricks.azure.cn. -
工作区 ID 为
5555555555555555.
确定每个工作区的 URL
您可以确定每个工作区的 URL:
登录时在浏览器中:

在 Azure 门户中,选择资源,并记下 URL 字段中的值:
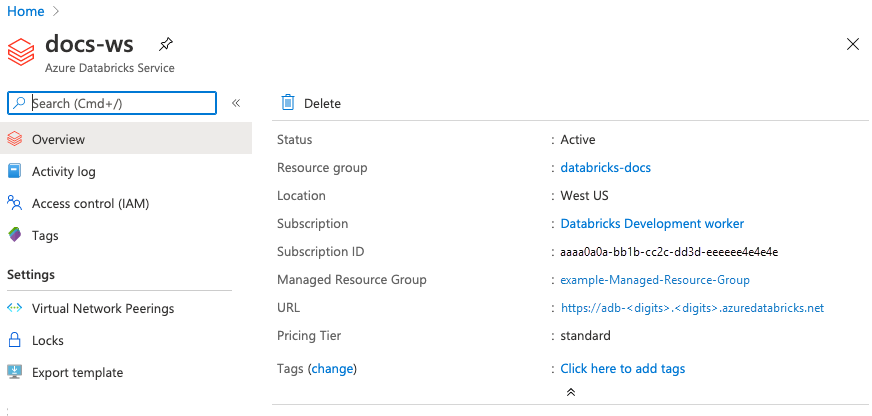
使用 Azure API。 请参阅 使用 Azure API 获取每工作区 URL。
旧区域 URL
重要
避免旧区域 URL。 他们:
- 可能不适用于新工作区。
- 不如每个工作区的 URL 可靠且速度更慢。
- 可以导致需要工作区 ID 的功能中断。
旧区域 URL 由部署 Azure Databricks 工作区的区域和域 databricks.azure.cn(例如 https://chinaeast2.databricks.azure.cn/)组成。
- 如果登录到类似
https://chinaeast2.databricks.azure.cn/的旧区域 URL,则实例名称为chinaeast2.databricks.azure.cn。 - 仅在使用旧区域 URL 登录之后,此 URL 中才会显示工作区 ID。 它显示在
o=的后面。 在 URLhttps://<databricks-instance>/?o=6280049833385130中,工作区 ID 为6280049833385130。
计算资源 URL 和 ID
Azure Databricks 计算资源 为各种用例提供统一的平台,例如运行生产 ETL 管道、流分析、即席分析和机器学习。 每个经典计算资源都有一个名为群集 ID 的唯一 ID。 这适用于全用途群集和作业群集,但不适用于无服务器计算。 需要群集 ID 才能使用 REST API 获取群集的详细信息。
若要获取群集 ID,请单击边栏上的 ![]() “计算 ”,然后选择群集名称。 群集 ID 是该页面的 URL 中紧随
“计算 ”,然后选择群集名称。 群集 ID 是该页面的 URL 中紧随 /clusters/ 组件之后的数字。
https://<databricks-instance>/compute/clusters/<cluster-id>
在以下屏幕截图中,群集 ID 为:0130-201722-abcdefgh。

仪表板 URL 和 ID
AI/BI 仪表板是数据可视化效果和注释的表示形式。 每个仪表板都有一个唯一 ID。 可以使用此 ID 构造包含预设筛选条件和参数值的直接链接,或使用 REST API 访问仪表板。
示例仪表板网址:
https://adb-62800498333851.30.databricks.azure.cn/sql/dashboardsv3/01ef9214fcc7112984a50575bf2b460f示例仪表板 ID:
01ef9214fcc7112984a50575bf2b460f
笔记本 URL 和 ID
笔记本是文档的基于 Web 的界面,其中包含可运行的代码、可视化效果和叙述性文本。 笔记本是用于与 Azure Databricks 进行交互的接口。 每个笔记本都具有唯一的 ID。 笔记本 URL 具有笔记本 ID,因此笔记本 URL 对于笔记本而言是唯一的。 可与 Azure Databricks 平台上有权查看和编辑笔记本的任何人共享该笔记本。 此外,每个笔记本命令(单元)都有不同的 URL。
若要查找笔记本 URL 或 ID,请打开笔记本。 若要查找单元格 URL,请单击命令内容。
示例笔记本 URL:
https://adb-62800498333851.30.databricks.azure.cn/?o=6280049833385130#notebook/1940481404050342`示例笔记本 ID:
1940481404050342。示例命令(单元)URL:
https://adb-62800498333851.30.databricks.azure.cn/?o=6280049833385130#notebook/1940481404050342/command/2432220274659491
文件夹 ID
文件夹是用于存储可在 Azure Databricks 工作区中使用的文件的目录。 这些文件可以是笔记本、库或子文件夹。 有一个与每个文件夹和每个单独的子文件夹关联的特定 ID。 权限 API 将此 ID 称为 directory_id,用于设置和更新文件夹的权限。
如需检索 directory_id,可以使用工作区 API:
curl -n -X GET -H 'Content-Type: application/json' -d '{"path": "/Users/me@example.com/MyFolder"}' \
https://<databricks-instance>/api/2.0/workspace/get-status
这是 API 调用响应的示例:
{
"object_type": "DIRECTORY",
"path": "/Users/me@example.com/MyFolder",
"object_id": 123456789012345
}
模型 ID
模型是指 一个已注册 MLflow 的模型,该模型允许你通过阶段转换和版本控制来管理生产中的 MLflow 模型。 通过 权限 API 以编程方式更改模型的权限时,需要注册的模型 ID。
若要获取已注册模型的 ID,可以使用 工作区 API 终结点 mlflow/databricks/registered-models/get。 例如,下面的代码会返回已注册模型的对象及其属性,包括其 ID:
curl -n -X GET -H 'Content-Type: application/json' -d '{"name": "model_name"}' \
https://<databricks-instance>/api/2.0/mlflow/databricks/registered-models/get
返回的值采用以下格式:
{
"registered_model_databricks": {
"name": "model_name",
"id": "ceb0477eba94418e973f170e626f4471"
}
}
任务 URL 和 ID
作业是立即运行或按计划运行笔记本或 JAR 的一种方法。
若要获取作业 URL,请单击边栏上的![]() ,然后单击“作业和管道”中的作业名称。 作业 ID 显示在 URL 中之后
,然后单击“作业和管道”中的作业名称。 作业 ID 显示在 URL 中之后 /jobs/ 。 使用作业 URL 导航到作业及其运行历史记录。 若要直接链接到特定运行,例如在支持票证中共享,请改用运行 URL。 请参阅 作业运行 URL 和 ID。
在以下屏幕截图中,作业 URL 为:
https://adb-chinaeast2.18.databricks.azure.cn/jobs/5?o=1248852073749208
在本例中,作业 ID 为 5。

作业运行 URL 和 ID
单个 作业 可以运行多个运行。 每个运行都有自己的唯一 运行 ID 和自己的 URL,这不同于作业 ID 和作业 URL。 共享指向特定运行的链接(例如,在支持票证中)使用运行 URL,而不是作业 URL,以便收件人打开正确的运行。
运行 URL 的格式如下:
https://<databricks-instance>/jobs/<job-id>/runs/<run-id>
若要在工作区 UI 中查找运行 ID 或 URL,请执行以下操作:
- 在作业的“ 运行 ”选项卡上,单击 “开始时间 ”列中的链接以打开 “作业运行详细信息 ”页。 运行 ID 显示在浏览器地址栏中。
/runs/复制地址以共享运行。 - 在 “作业运行详细信息 ”页上,地址栏中的 URL 包含作业 ID 和窗体
/jobs/<job-id>/runs/<run-id>中的运行 ID。
若要以编程方式获取运行 ID 或 URL,请执行以下操作: