注意
本文介绍适用于 Databricks Runtime 13.3 LTS 及更高版本的 Databricks Connect。
Databricks Connect 是 Databricks Runtime 的客户端库,可用于从 VISUAL Studio Code、PyCharm 和 IntelliJ IDEA、笔记本和任何自定义应用程序等 IDE 连接到 Azure Databricks 计算,以基于 Azure Databricks Lakehouse 启用新的交互式用户体验。
Databricks Connect 适用于以下语言:
Databricks Connect 可以做什么?
使用 Databricks Connect,可以使用 Spark API 编写代码,并在 Azure Databricks 计算而不是本地 Spark 会话中远程运行它们。
从任何 IDE 以交互方式开发和调试。 Databricks Connect 使开发人员能够使用任何 IDE 的本机运行和调试功能在 Databricks 计算上开发和调试其代码。 Databricks Visual Studio Code 扩展使用 Databricks Connect 在 Databricks 上提供用户代码的内置调试。
生成交互式数据应用。 与 JDBC 驱动程序一样, Databricks Connect 库 可以嵌入到与 Databricks 交互的任何应用程序中。 Databricks Connect 通过 PySpark 提供了 Python 的完整表现力,消除了 SQL 编程语言的适配差距,使您能够在 Databricks 的无服务器可扩展计算上,通过 Spark 执行所有的数据转换。
它的工作原理是什么?
Databricks Connect 基于开源 Spark Connect 构建,后者具有适用于 Apache Spark 的分离客户端-服务器体系结构 ,允许使用 DataFrame API 远程连接到 Spark 群集。 底层协议使用 Spark 的未解析逻辑计划和基于 gRPC 的 Apache Arrow。 客户端 API 设计为精简,因此可以随处嵌入:在应用程序服务器、IDE、笔记本和编程语言中。
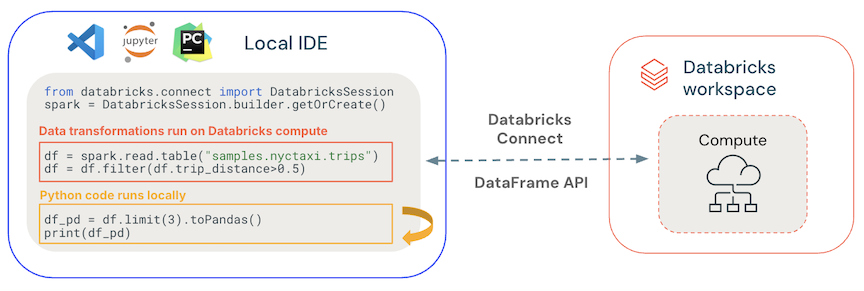
- 常规代码在本地运行:Python 和 Scala 代码在客户端运行,启用交互式调试。 所有代码都在本地执行,而所有 Spark 代码将继续在远程群集上运行。
-
DataFrame API 在 Databricks 计算上执行。 所有数据转换都转换为 Spark 计划,并通过远程 Spark 会话在 Databricks 计算上运行。 使用命令(例如
collect(),show(),toPandas())时,它们将呈现在本地客户端上。 -
UDF 代码在 Databricks 计算上运行:在本地定义的 UDF 会被序列化并传送到其运行的群集。 在 Databricks 上运行用户代码的 API 包括:UDF、
foreach、和foreachBatchtransformWithState。 - 对于依赖项管理:
- 在本地计算机上安装应用程序依赖项。 这些代码在本地运行,需要作为项目的一部分进行安装,例如 Python 虚拟环境的一部分。
- 在 Databricks 上安装 UDF 依赖项。 请参阅 “管理 UDF 依赖项”。
Databricks Connect 和 Spark Connect 如何相关?
Spark Connect 是 Apache Spark 中基于 gRPC 的开源协议,允许使用数据帧 API 远程执行 Spark 工作负载。
对于 Databricks Runtime 13.3 LTS 及更高版本,Databricks Connect 是 Spark Connect 的扩展,包含添加和修改,以支持使用 Databricks 计算模式和 Unity 目录。
后续步骤
请参阅以下教程,快速开始开发 Databricks Connect 解决方案:
- 用于 Python 经典计算的 Databricks Connect 教程
- Databricks Connect 教程:Python 实现无服务器计算
- 用于 Scala 经典计算的 Databricks Connect 教程
- 用于 Scala 无服务器计算的 Databricks Connect 教程
- 用于 R 的 Databricks Connect 教程
若要查看使用 Databricks Connect 的示例应用程序,请参阅 GitHub 示例存储库,其中包括以下示例: