注意
本文介绍 sparklyr 与适用于 Databricks Runtime 13.0 及更高版本的 Databricks Connect 的集成。 Databricks 既不提供,也不直接支持此集成。
如有问题,请转到 Posit 社区。
若要报告问题,请转到 GitHub 中存储库的“问题”部分。
有关详细信息,请参阅 Databricks Connect v2 在 sparklyr 文档中。
可以使用 Databricks Connect 将热门的 IDE(例如 RStudio Desktop、笔记本服务器和其他自定义应用程序)连接到 Azure Databricks 群集。 请参阅 Databricks Connect。
注意
Databricks Connect 与 Apache Spark MLlib 的兼容性有限,因为 Spark MLlib 使用 RDD,而 Databricks Connect 仅支持 DataFrame API。 若要使用 sparklyr 的所有 Spark MLlib 函数,请使用 Databricks 笔记本或db_replbrickster 包中的函数。
本文演示如何快速开始使用用于 R 的 sparklyr Databricks Connect 和 RStudio Desktop。
- 有关 Python 的 Databricks Connect,请参阅Databricks Connect for Python。
- 有关用于 Scala 的 Databricks Connect,请参阅 Databricks Connect for Scala。
教程
在以下教程中,你将在 RStudio 中创建一个项目,安装和配置 Databricks Connect for Databricks Runtime 13.3 LTS 及更高版本,并在 RStudio 的 Databricks 工作区中的计算上运行简单代码。 有关本教程的补充信息,请参阅 Spark Connect 和 Databricks Connect v2 在 sparklyr 网站上的“Databricks Connect”部分。
此教程使用 RStudio Desktop 和 Python 3.10。 如果尚未安装它们,请安装 R 和 RStudio Desktop 以及 Python 3.10。
要求
若要完成此教程,必须满足以下要求:
- 目标 Azure Databricks 工作区和群集必须满足 Databricks Connect 计算配置的要求。
- 您必须具备群集 ID。 若要获取你的群集 ID,请在工作区中单击边栏上的“计算”,然后单击群集的名称。 在 Web 浏览器的地址栏中,复制 URL 中
clusters和configuration之间的字符串。
步骤 1:创建个人访问令牌
注意
适用于 R 的 Databricks Connect 身份验证目前仅支持 Azure Databricks 个人访问令牌。
本教程使用 Azure Databricks 个人访问令牌身份验证向 Azure Databricks 工作区进行身份验证。
如果已有 Azure Databricks 个人访问令牌,请跳到步骤 2。 如果不确定是否已拥有 Azure Databricks 个人访问令牌,则可以按照此步骤操作,而不会影响用户帐户中的任何其他 Azure Databricks 个人访问令牌。
若要创建个人访问令牌,请按照 为工作区用户创建个人访问令牌中的步骤作。
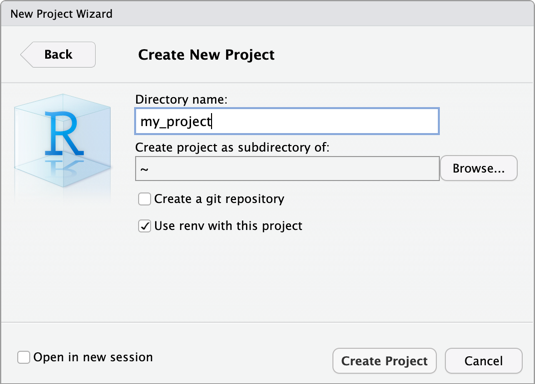
步骤 2:创建项目
启动 RStudio Desktop。
在主菜单上,单击“文件”>“新建项目”。
选择“新建目录”。
选择“新建项目”。
对于目录名称和创建项目作为子目录,请输入新项目目录的名称以及创建新项目目录的位置。
选择“将 renv 与此项目配合使用”。 如果系统提示安装更新的
renv包版本,请单击“是”。单击“创建项目”。
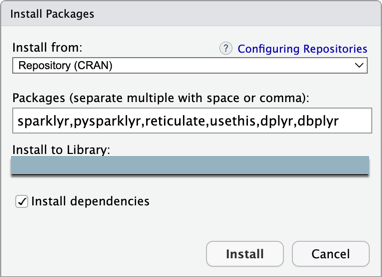
步骤 3:添加 Databricks Connect 包和其他依赖项
在 RStudio Desktop 主菜单上,单击“工具”>“安装包”。
将“从…安装”保持设置为“存储库 (CRAN)”。
对于Packages,请输入以下软件包列表,这些软件包是 Databricks Connect 包和本教程的先决条件:
sparklyr,pysparklyr,reticulate,usethis,dplyr,dbplyr使“Install to Library”保持在您的 R 虚拟环境中。
确保已选择“安装依赖项”。
单击“安装” 。
当“控制台”视图中提示你(“视图”“将焦点移到控制台”)继续安装时,请输入 >。
YR 虚拟环境中安装了sparklyr和pysparklyr包及其依赖项。在“控制台”窗格中,使用 通过运行以下命令来安装 Python。
reticulate(适用于 R 的 Databricks Connect 需要先安装 Python 和reticulate。)在以下命令中,将3.10替换为 Azure Databricks 群集上安装的 Python 版本的主要版本和次要版本。 若要查找此主要版本和次要版本,请参阅 Databricks Runtime 发行说明版本和兼容性,查看你的群集的 Databricks Runtime 版本的发行说明的“系统环境”部分。reticulate::install_python(version = "3.10")在“控制台”窗格中,运行以下命令安装 Databricks Connect 包。 在以下命令中,将
13.3替换为 Azure Databricks 群集上安装的 Databricks Runtime 版本。 若要查找此版本,请在你的 Azure Databricks 工作区的群集详细信息页上的“配置”选项卡上,查看“Databricks Runtime 版本”框。pysparklyr::install_databricks(version = "13.3")如果不知道群集的 Databricks Runtime 版本或不想查找它,可以改为运行以下命令,
pysparklyr会查询群集以确定要使用的正确 Databricks Runtime 版本:pysparklyr::install_databricks(cluster_id = "<cluster-id>")如果希望项目稍后连接到不同群集,且该群集的 Databricks Runtime 版本与刚才指定的版本相同,
pysparklyr将使用相同的 Python 环境。 如果新群集具有不同的 Databricks Runtime 版本,则应使用新的 Databricks Runtime 版本或群集 ID 再次运行pysparklyr::install_databricks命令。
步骤 4:为工作区 URL、访问令牌和群集 ID 设置环境变量
Databricks 不建议将敏感值或更改值(例如 Azure Databricks 工作区 URL、Azure Databricks 个人访问令牌或 Azure Databricks 群集 ID)硬编码写入 R 脚本。 请单独存储这些值,例如存储在本地环境变量中。 本教程使用 RStudio Desktop 的内置支持将环境变量存储在 .Renviron 文件中。
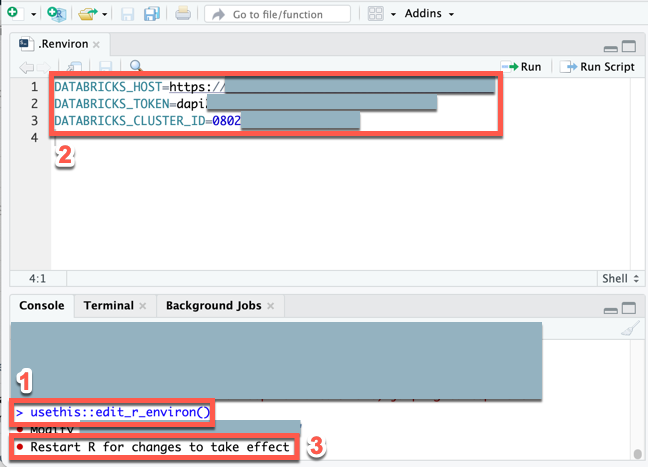
创建一个
.Renviron文件来存储环境变量(如果此文件尚不存在),然后打开此文件进行编辑:在 RStudio Desktop“控制台”中运行以下命令:usethis::edit_r_environ()在出现的
文件中(“查看” “将焦点移至源” ),输入以下内容。 在此内容中,替换以下占位符: - 将
<workspace-url>替换为每工作区 URL,例如https://adb-1234567890123456.7.databricks.azure.cn。 - 将
<personal-access-token>替换为你在步骤 1 中的 Azure Databricks 个人访问令牌。 - 将
<cluster-id>替换为本教程要求中的群集 ID。
DATABRICKS_HOST=<workspace-url> DATABRICKS_TOKEN=<personal-access-token> DATABRICKS_CLUSTER_ID=<cluster-id>- 将
保存
.Renviron文件。将环境变量加载到 R 中:在主菜单上,单击“会话”>“重启 R”。
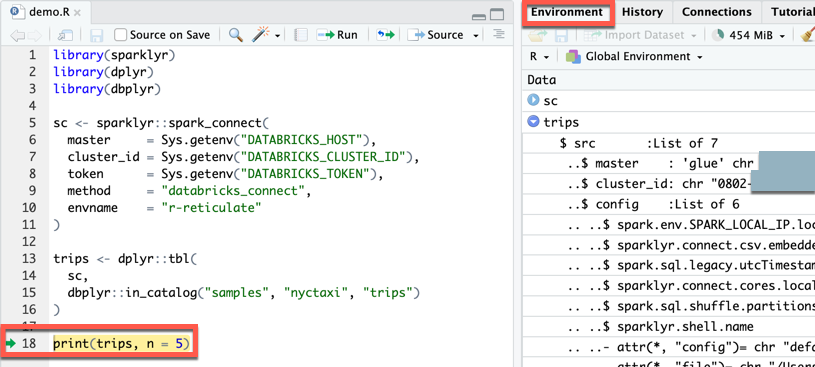
步骤 5:添加代码
在 RStudio Desktop 主菜单中,单击“文件”>“新建文件”>“R 脚本”。
在文件中输入以下代码,然后将该文件保存(“文件”
保存 )为 。 library(sparklyr) library(dplyr) library(dbplyr) sc <- sparklyr::spark_connect( master = Sys.getenv("DATABRICKS_HOST"), cluster_id = Sys.getenv("DATABRICKS_CLUSTER_ID"), token = Sys.getenv("DATABRICKS_TOKEN"), method = "databricks_connect", envname = "r-reticulate" ) trips <- dplyr::tbl( sc, dbplyr::in_catalog("samples", "nyctaxi", "trips") ) print(trips, n = 5)
步骤 6:运行代码
在 RStudio Desktop 上
demo.R文件的工具栏中,单击 “源码”。
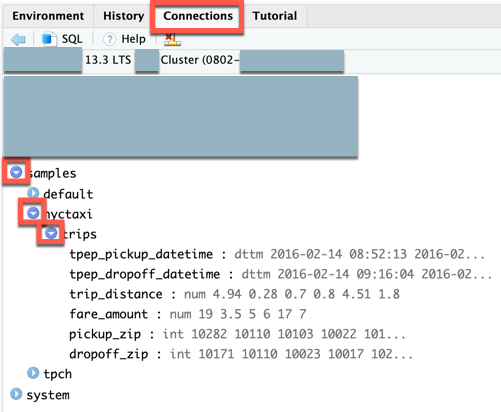
在控制台中,将显示表的前五行
trips。在连接视图(视图>显示连接)中,可以浏览可用的目录、数据库架构、表和视图。
步骤 7:调试代码
在
demo.R文件中,点击print(trips, n = 5)旁边的边栏以设置断点。在
demo.R文件的工具栏中,单击“源”。当代码在断点暂停运行时,可以在“环境”视图中检查变量(“查看”“显示环境”)。>
在主菜单上,单击“调试”>“继续”。
在控制台中,将显示表的前五行
trips。