重要
Databricks Connect for Databricks Runtime 12.2 LTS 及更低版本已弃用。 Databricks Runtime 12.2 LTS 和所有早期 LTS 版本都已终止支持。 请改 用 Databricks Connect for Databricks Runtime 13.3 LTS 及更高版本 。 有关从 Databricks Connect for Databricks Runtime 12.2 LTS 及更低版本迁移到 Databricks Connect for Databricks Runtime 13.3 LTS 及更高版本的信息,请参阅 迁移到用于 Python 的 Databricks Connect 或 迁移到用于 Scala 的 Databricks Connect。
使用 Databricks Connect 可将流行的 IDE(例如 Visual Studio Code 和 PyCharm)、笔记本服务器和其他自定义应用程序连接到 Azure Databricks 群集。
本文将介绍 Databricks Connect 的工作原理,引导你完成 Databricks Connect 的入门步骤,阐述如何解决使用 Databricks Connect 时可能出现的问题,还将介绍使用 Databricks Connect 运行与在 Azure Databricks 笔记本中运行之间的区别。
概述
Databricks Connect 是一个适用于 Databricks Runtime 的客户端库。 借助它,你可使用 Spark API 编写作业,并让它们在 Azure Databricks 群集上(而不是在本地 Spark 会话中)远程执行。
例如,当你使用 Databricks Connect 运行数据帧命令 spark.read.format(...).load(...).groupBy(...).agg(...).show() 时,该命令的逻辑表示形式将发送到在 Azure Databricks 中运行的 Spark 服务器,以便在远程群集上执行。
可使用 Databricks Connect 执行以下操作:
- 从任何 Python、R、Scala 或 Java 应用程序运行大规模 Spark 作业。 现可在任何能执行
import pyspark、require(SparkR)或import org.apache.spark的位置直接从应用程序运行 Spark 作业,无需安装任何 IDE 插件,也无需使用 Spark 提交脚本。 - 即使在使用远程集群时,也要在 IDE 中单步执行和调试代码。
- 开发库时快速迭代。 在 Databricks Connect 中更改 Python 或 Java 库依赖项后,无需重启群集,这是因为群集中的每个客户端会话彼此隔离。
- 在不丢失工作成果的情况下关闭未使用的集群。 客户端应用程序与群集是分离的,因此它不受群集重启或升级的影响,这通常会导致你丢失笔记本中定义的所有变量、RDD 和 DataFrame 对象。
注意
对于使用 SQL 查询进行 python 开发,Databricks 建议使用适用于 Python 的 Databricks SQL 连接器,而不是 Databricks Connect。 适用于 Python 的 Databricks SQL 连接器的设置比 Databricks Connect 简单。 此外,Databricks Connect 在本地计算机上解析和计划作业运行,而作业则在远程计算资源上执行。 这会使调试运行时错误变得特别困难。 适用于 Python 的 Databricks SQL 连接器将 SQL 查询直接提交到远程计算资源并获取结果。
要求
本部分列出了 Databricks Connect 的要求。
仅支持以下 Databricks Runtime 版本:
- Databricks Runtime 12.2 LTS ML、Databricks Runtime 12.2 LTS
- Databricks Runtime 11.3 LTS ML、Databricks Runtime 11.3 LTS
- Databricks Runtime 10.4 LTS ML、Databricks Runtime 10.4 LTS
- Databricks Runtime 9.1 LTS ML、Databricks Runtime 9.1 LTS
- Databricks Runtime 7.3 LTS
必须在开发计算机上安装 Python 3,并且客户端 Python 安装次要版本必须与 Azure Databricks 群集的次要 Python 版本相同。 下表显示了随每个 Databricks Runtime 一起安装的 Python 版本。
Databricks Runtime 版本 Python 版本 12.2 LTS ML、12.2 LTS 3.9 11.3 LTS ML、11.3 LTS 3.9 10.4 LTS ML、10.4 LTS 3.8 9.1 LTS ML、9.1 LTS 3.8 7.3 LTS 3.7 Databricks 强烈建议为与 Databricks Connect 配合使用的每个 Python 版本激活 Python 虚拟环境。 Python 虚拟环境有助于确保将正确版本的 Python 和 Databricks Connect 一起使用。 这有助于减少解决相关技术问题所花费的时间。
例如,如果你在开发计算机上使用 venv,并且群集正在运行 Python 3.9,则必须使用该版本创建一个
venv环境。 以下示例命令生成使用 Python 3.9 激活venv环境的脚本,然后此命令将这些脚本放在当前工作目录内名为.venv的隐藏文件夹中:# Linux and macOS python3.9 -m venv ./.venv # Windows python3.9 -m venv .\.venv若要使用这些脚本激活此
venv环境,请参阅 venvs 的工作原理。另举一例,如果你在开发计算机上使用 Conda,并且群集运行 Python 3.9,则必须使用该版本创建一个 Conda 环境,例如:
conda create --name dbconnect python=3.9若要使用此环境名称激活 Conda 环境,请运行
conda activate dbconnect。Databricks Connect 的主要和次要包版本必须始终与 Databricks Runtime 版本匹配。 Databricks 建议始终使用与 Databricks Runtime 版本相匹配的 Databricks Connect 的最新包。 例如,在使用 Databricks Runtime 12.2 LTS 群集时,也必须使用
databricks-connect==12.2.*包。注意
请参阅 Databricks Connect 发行说明,了解可用 Databricks Connect 版本和维护更新的列表。
Java 运行时环境 (JRE) 8。 该客户端已使用 OpenJDK 8 JRE 进行了测试。 客户端不支持 Java 11。
注意
在 Windows 上,如果看到 Databricks Connect 找不到 winutils.exe 的错误,请参阅 Windows 上的“winutils.exe 找不到”。
安装客户端
完成以下步骤来为 Databricks Connect 安装本地客户端。
注意
在开始安装本地 Databricks Connect 客户端之前,必须满足 Databricks Connect 的要求。
步骤 1:安装 Databricks Connect 客户端
激活虚拟环境后,运行
uninstall命令卸载 PySpark(如果已安装)。 这是必需的,因为databricks-connect包与 PySpark 冲突。 有关详细信息,请参阅 PySpark 安装存在冲突。 若要检查是否已安装 PySpark,请运行show命令。# Is PySpark already installed? pip3 show pyspark # Uninstall PySpark pip3 uninstall pyspark在虚拟环境仍处于激活状态的情况下,运行
install命令安装 Databricks Connect 客户端。 使用--upgrade选项将任何现有客户端安装升级到指定的版本。pip3 install --upgrade "databricks-connect==12.2.*" # Or X.Y.* to match your cluster version.注意
Databricks 建议使用“点星号”符号来指定
databricks-connect==X.Y.*而不是databricks-connect=X.Y,以确保安装最新的包。
步骤 2:配置连接属性
收集以下配置属性。
Azure Databricks 针对每个工作区的 URL。 这与
https://后跟群集的服务器主机名值也相同;请参阅获取 Azure Databricks 计算资源的连接详细信息。Azure Databricks 个人访问令牌或 Microsoft Entra ID(旧称 Azure Active Directory)令牌。
- 对于 Azure Data Lake Storage (ADLS) 凭据传递,必须使用 Microsoft Entra ID 令牌。 Microsoft Entra ID 凭据传递仅在运行 Databricks Runtime 7.3 LTS 和更高版本的标准群集上受支持,且与服务主体身份验证不兼容。
经典计算实例的 ID。 可以从 URL 获取经典计算 ID。 此处的 ID 为
1108-201635-xxxxxxxx. 另请参阅 计算资源 URL 和 ID。
工作区的唯一组织 ID。 请参阅获取工作区对象的标识符。
Databricks Connect 在群集上连接到的端口。 默认端口为
15001。 如果将群集配置为使用其他端口,例如在之前的 Azure Databricks 说明中提供的8787,则使用所配置的端口号。
如下所示配置连接。
可使用 CLI、SQL 配置或环境变量。 配置方法的优先级从高到低为:SQL 配置密钥、CLI 和环境变量。
CLI
运行
databricks-connect。databricks-connect configure许可证显示:
Copyright (2018) Databricks, Inc. This library (the "Software") may not be used except in connection with the Licensee's use of the Databricks Platform Services pursuant to an Agreement ...接受许可证并提供配置值。 对于 Databricks 主机和 Databricks 令牌,输入在步骤 1 中记下的工作区 URL 和个人访问令牌。
Do you accept the above agreement? [y/N] y Set new config values (leave input empty to accept default): Databricks Host [no current value, must start with https://]: <databricks-url> Databricks Token [no current value]: <databricks-token> Cluster ID (e.g., 0921-001415-jelly628) [no current value]: <cluster-id> Org ID (Azure-only, see ?o=orgId in URL) [0]: <org-id> Port [15001]: <port>如果收到 Microsoft Entra ID 令牌过长的消息,可以将“Databricks 令牌”字段留空,并在
~/.databricks-connect中手动输入令牌。
SQL 配置或环境变量。 下表显示了与你在步骤 1 中记下的配置属性相对应的 SQL 配置键和环境变量。 若要设置 SQL 配置密钥,请使用
sql("set config=value")。 例如:sql("set spark.databricks.service.clusterId=0304-201045-abcdefgh")。参数 SQL 配置密钥 环境变量名称 Databricks 主机 spark.databricks.service.address DATABRICKS_ADDRESS Databricks 令牌 spark.databricks.service.token DATABRICKS_API_TOKEN 群集 ID spark.databricks.service.clusterId DATABRICKS_CLUSTER_ID 组织标识符 spark.databricks.service.orgId DATABRICKS_ORG_ID 端口 spark.databricks.service.port DATABRICKS_PORT
在虚拟环境仍处于激活状态的情况下,如下所示测试与 Azure Databricks 的连接。
databricks-connect test如果配置的群集未运行,测试将启动群集,该群集将保持运行,直到其配置的自动终止时间为止。 输出应如下所示:
* PySpark is installed at /.../.../pyspark * Checking java version java version "1.8..." Java(TM) SE Runtime Environment (build 1.8...) Java HotSpot(TM) 64-Bit Server VM (build 25..., mixed mode) * Testing scala command ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN MetricsSystem: Using default name SparkStatusTracker for source because neither spark.metrics.namespace nor spark.app.id is set. ../../.. ..:..:.. WARN SparkServiceRPCClient: Now tracking server state for 5ab..., invalidating prev state ../../.. ..:..:.. WARN SparkServiceRPCClient: Syncing 129 files (176036 bytes) took 3003 ms Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2... /_/ Using Scala version 2.... (Java HotSpot(TM) 64-Bit Server VM, Java 1.8...) Type in expressions to have them evaluated. Type :help for more information. scala> spark.range(100).reduce(_ + _) Spark context Web UI available at https://... Spark context available as 'sc' (master = local[*], app id = local-...). Spark session available as 'spark'. View job details at <databricks-url>/?o=0#/setting/clusters/<cluster-id>/sparkUi View job details at <databricks-url>?o=0#/setting/clusters/<cluster-id>/sparkUi res0: Long = 4950 scala> :quit * Testing python command ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN MetricsSystem: Using default name SparkStatusTracker for source because neither spark.metrics.namespace nor spark.app.id is set. ../../.. ..:..:.. WARN SparkServiceRPCClient: Now tracking server state for 5ab.., invalidating prev state View job details at <databricks-url>/?o=0#/setting/clusters/<cluster-id>/sparkUi如果未显示连接相关的错误(
WARN消息没有问题),则表示已成功连接。
使用 Databricks Connect
本部分介绍如何配置首选 IDE 或笔记本服务器来使用 Databricks Connect 客户端。
本节内容:
- JupyterLab
- 经典 Jupyter Notebook
- PyCharm
- SparkR 和 RStudio Desktop
- sparklyr 和 RStudio Desktop
- IntelliJ(Scala 或 Java)
- PyDev 与 Eclipse
- 日蚀
- SBT
- Spark shell
JupyterLab
若要将 Databricks Connect 与 JupyterLab 和 Python 配合使用,请按以下说明操作。
若要安装 JupyterLab,请在激活了 Python 虚拟环境的情况下,从终端或命令提示符运行以下命令:
pip3 install jupyterlab若要在 Web 浏览器中启动 JupyterLab,请从已激活的 Python 虚拟环境运行以下命令:
jupyter lab如果 JupyterLab 未显示在 Web 浏览器中,请从虚拟环境中复制以
localhost或127.0.0.1开头的 URL,并将其输入到 Web 浏览器的地址栏中。创建新笔记本:在 JupyterLab 中,单击主菜单中的“文件”>“新建”>“笔记本”,选择“Python 3 (ipykernel)”,然后单击“选择”。
在笔记本的第一个单元格中,输入示例代码或你自己的代码。 如果你使用自己的代码,则至少必须实例化
SparkSession.builder.getOrCreate()的实例,如示例代码中所示。若要运行笔记本,请单击运行>运行所有单元格。
若要调试笔记本,请单击笔记本工具栏中“Python 3 (ipykernel)”旁边的调试(“启用调试器”)图标。 请设置一个或多个断点,然后单击运行>运行所有单元格。
若要关闭 JupyterLab,请单击“文件”>“关闭”。 如果 JupyterLab 进程仍在终端或命令提示符中运行,请按
Ctrl + c停止此进程,然后输入y以确认。
有关更具体的调试说明,请参阅调试器。
经典 Jupyter Notebook
Databricks Connect 的配置脚本会自动将包添加到项目配置中。 若要在 Python 内核中开始操作,请运行:
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
若要启用 %sql 速记来运行和直观呈现 SQL 查询,请使用以下代码片段:
from IPython.core.magic import line_magic, line_cell_magic, Magics, magics_class
@magics_class
class DatabricksConnectMagics(Magics):
@line_cell_magic
def sql(self, line, cell=None):
if cell and line:
raise ValueError("Line must be empty for cell magic", line)
try:
from autovizwidget.widget.utils import display_dataframe
except ImportError:
print("Please run `pip install autovizwidget` to enable the visualization widget.")
display_dataframe = lambda x: x
return display_dataframe(self.get_spark().sql(cell or line).toPandas())
def get_spark(self):
user_ns = get_ipython().user_ns
if "spark" in user_ns:
return user_ns["spark"]
else:
from pyspark.sql import SparkSession
user_ns["spark"] = SparkSession.builder.getOrCreate()
return user_ns["spark"]
ip = get_ipython()
ip.register_magics(DatabricksConnectMagics)
Visual Studio Code
若要将 Databricks Connect 与 Visual Studio Code 配合使用,请执行以下操作:
验证是否已安装 Python 扩展。
打开命令面板(在 macOS 上使用 Command+Shift+P,在 Windows/Linux 使用 Ctrl+Shift+P)。
选择 Python 解释器。 转到代码> 首选项> 设置,然后选择Python 设置。
运行
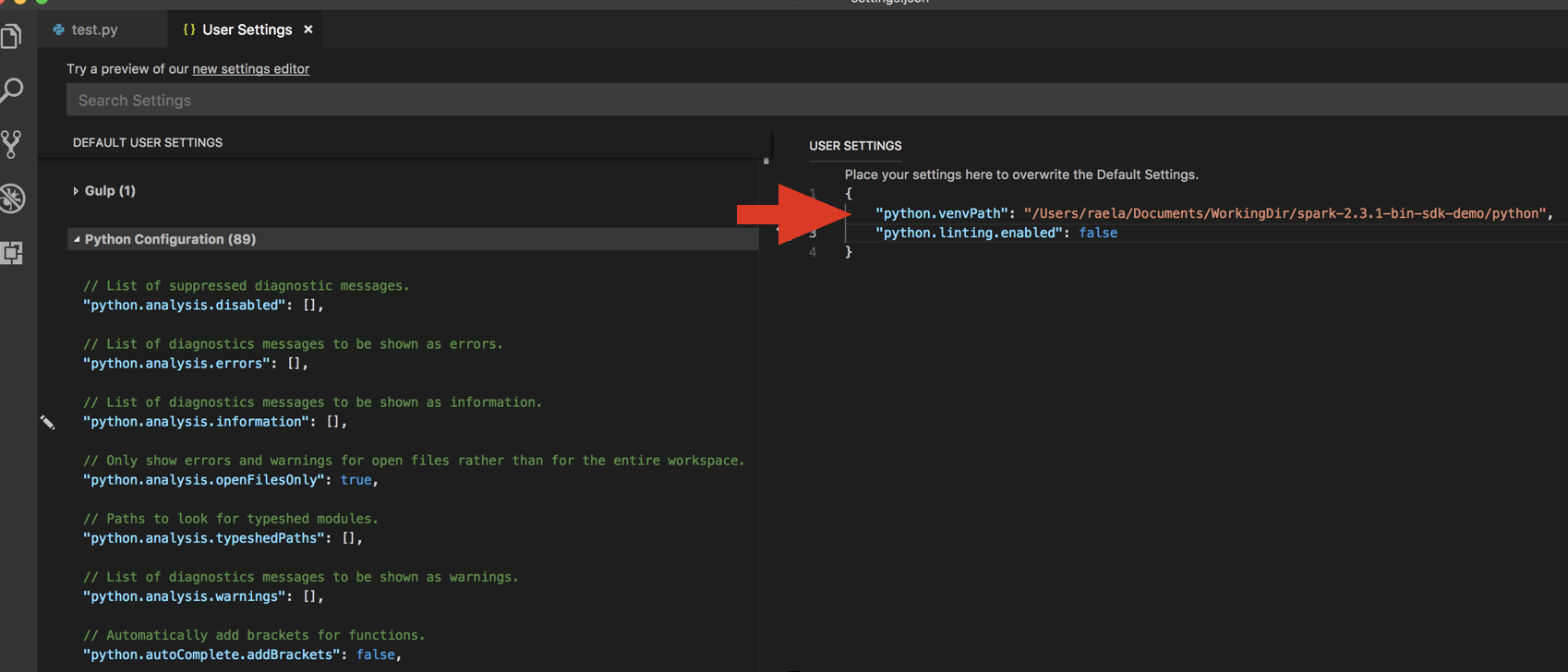
databricks-connect get-jar-dir。将从命令返回的目录添加到
python.venvPath下的用户设置 JSON 中。 应将此内容添加到 Python 配置中。禁用 Linter。 单击右侧的“…”,然后“编辑 json 设置”。 修改后的设置如下所示:
如果使用虚拟环境运行(若要在 VS Code 中开发 Python,则建议使用此环境),请在命令面板中键入
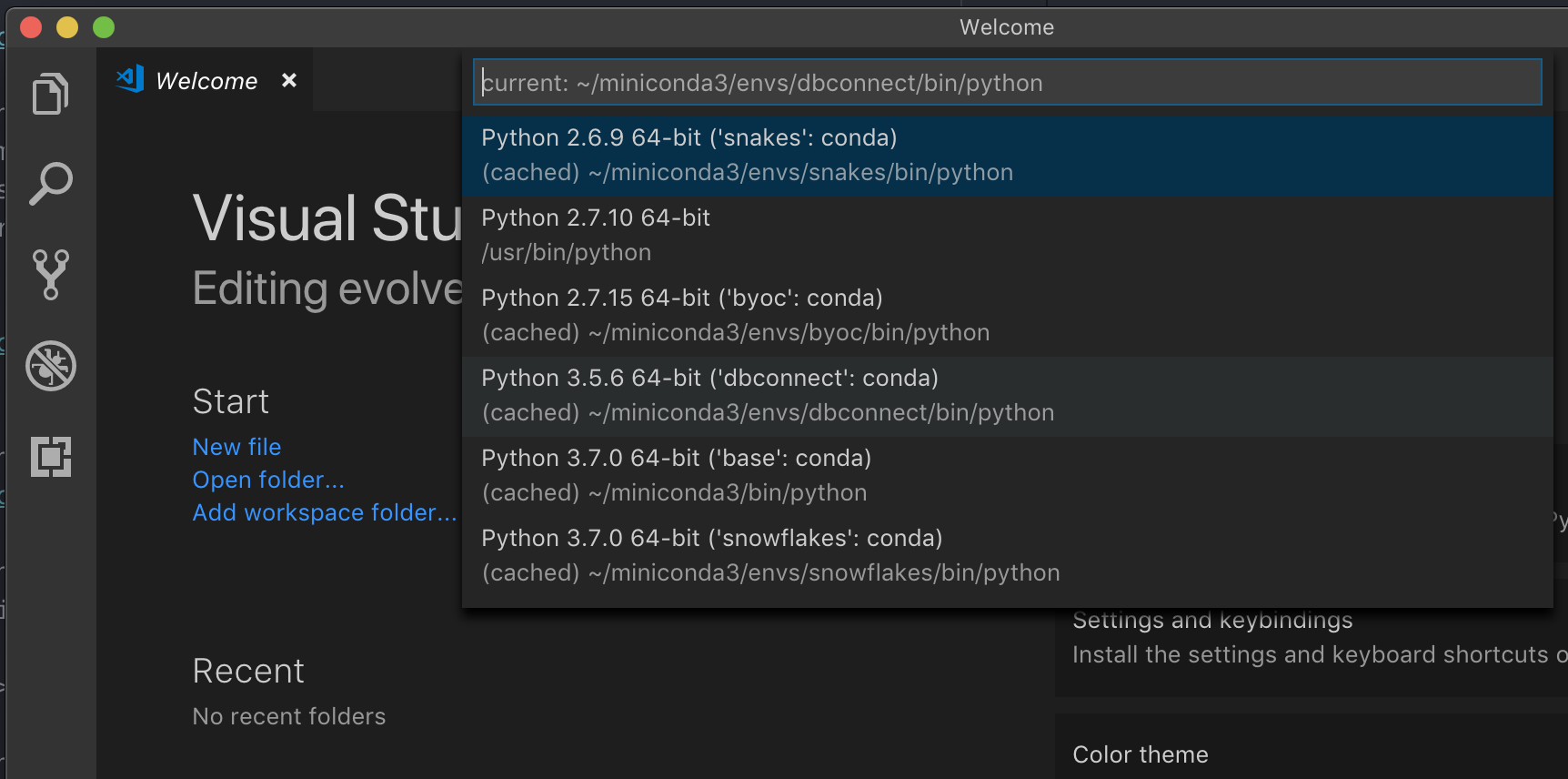
select python interpreter,并指向与群集 Python 版本匹配的环境。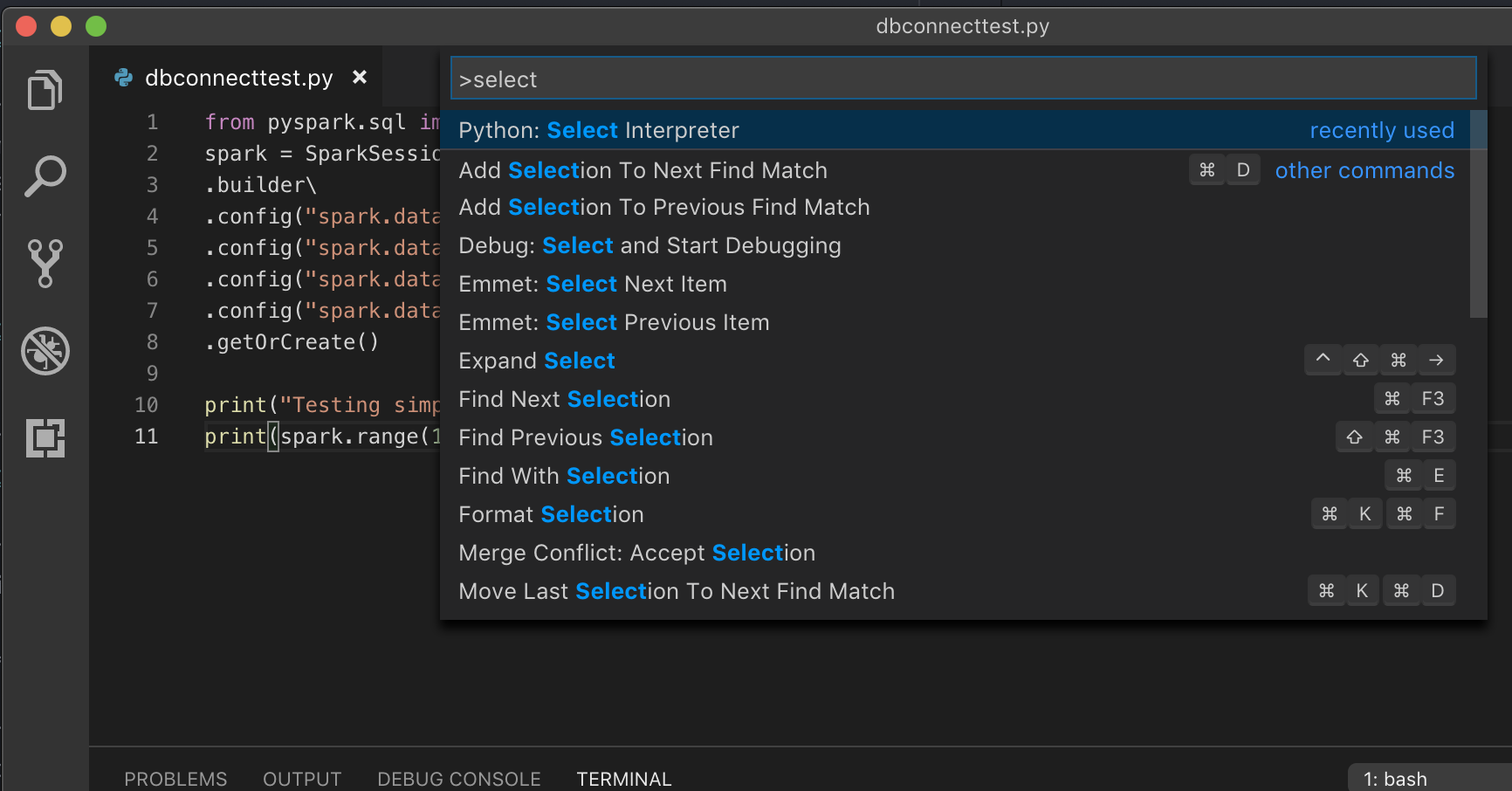
例如,如果群集上使用的版本为 Python 3.9,则开发环境中使用的版本应该也是 Python 3.9。
PyCharm
Databricks Connect 的配置脚本会自动将包添加到项目配置中。
Python 3 群集
创建 PyCharm 项目时,请选择“现有解释器”。 从下拉菜单中,选择你创建的 Conda 环境(请参阅要求)。
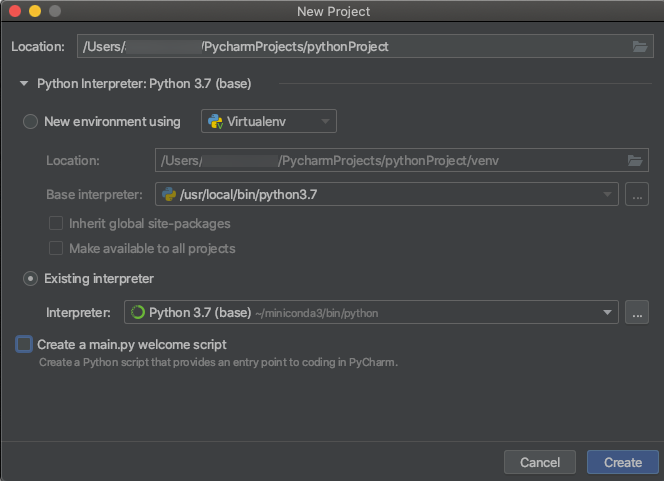
转到“运行”>“编辑配置”。
将
PYSPARK_PYTHON=python3添加为环境变量。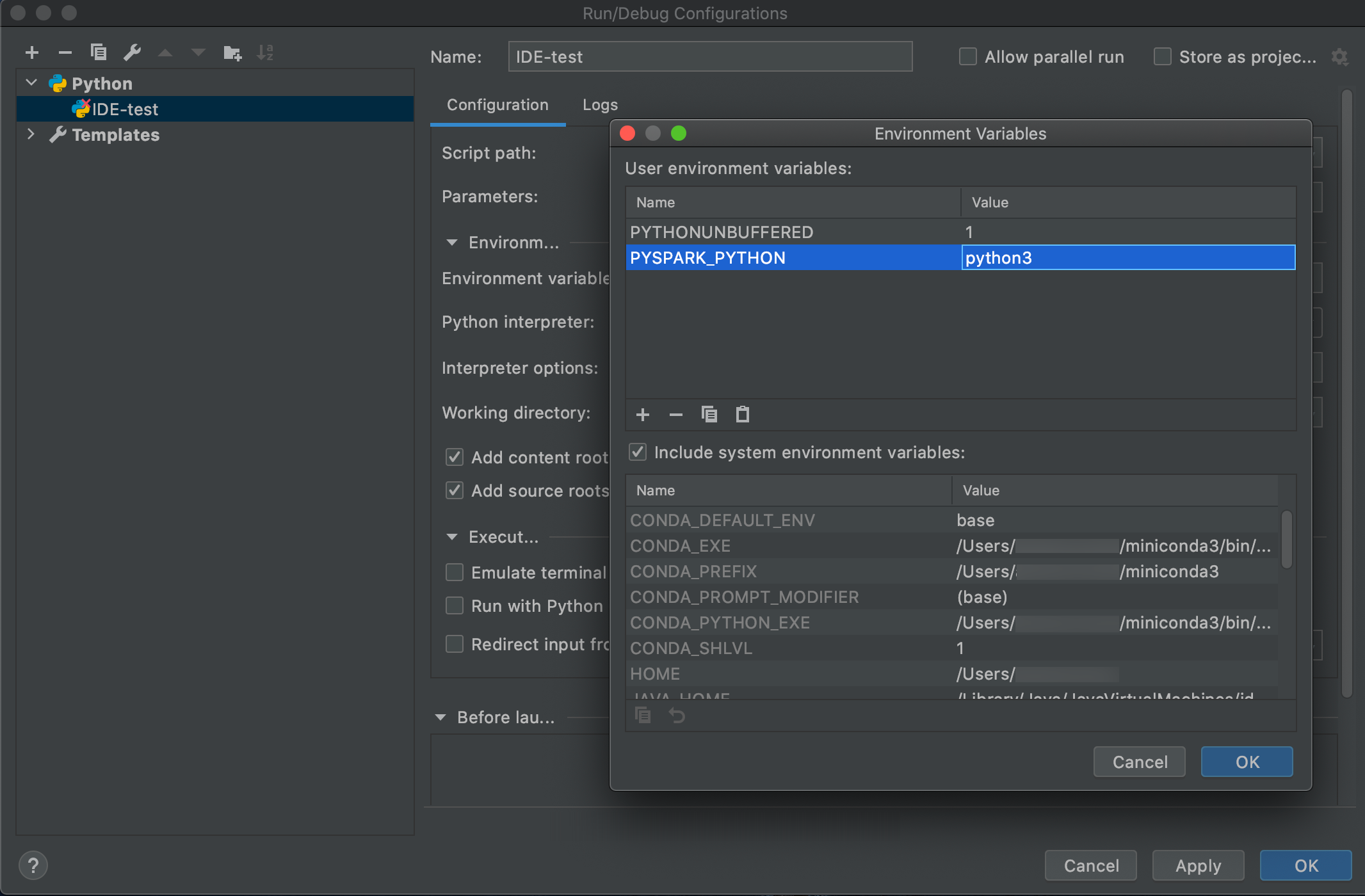
SparkR 和 RStudio Desktop
若要将 Databricks Connect 与 SparkR 和 RStudio Desktop 配合使用,请执行以下操作:
下载开源 Spark 发行版并将其解包到开发计算机。 选择与 Azure Databricks 群集 (Hadoop 2.7) 中相同的版本。
运行
databricks-connect get-jar-dir。 此命令会返回类似/usr/local/lib/python3.5/dist-packages/pyspark/jars的路径。 复制 JAR 目录文件路径上方的一个目录的文件路径,例如/usr/local/lib/python3.5/dist-packages/pyspark(即SPARK_HOME目录)。配置 Spark lib 路径和 Spark home,方式是将它们添加到 R 脚本的顶部。 将
<spark-lib-path>设置为在步骤 1 中解压缩开源 Spark 包的目录。 将<spark-home-path>设置为步骤 2 中的 Databricks Connect 目录。# Point to the OSS package path, e.g., /path/to/.../spark-2.4.0-bin-hadoop2.7 library(SparkR, lib.loc = .libPaths(c(file.path('<spark-lib-path>', 'R', 'lib'), .libPaths()))) # Point to the Databricks Connect PySpark installation, e.g., /path/to/.../pyspark Sys.setenv(SPARK_HOME = "<spark-home-path>")启动 Spark 会话,开始运行 SparkR 命令。
sparkR.session() df <- as.DataFrame(faithful) head(df) df1 <- dapply(df, function(x) { x }, schema(df)) collect(df1)
sparklyr 和 RStudio Desktop
重要
此功能目前以公共预览版提供。
可复制使用 Databricks Connect 在本地开发的依赖 sparklyr 的代码,并在 Azure Databricks 笔记本或在 Azure Databricks 工作区中的托管 RStudio Server 中运行该代码,只需很少的代码更改或无需代码更改即可实现。
本节内容:
要求
- sparklyr 1.2 或更高版本。
- Databricks Runtime 7.3 LTS 或更高版本,以及匹配版本的 Databricks Connect。
安装、配置和使用 sparklyr
在 RStudio Desktop 中,从 CRAN 安装 sparklyr 1.2 或更高版本,或者从 GitHub 安装最新的主版本。
# Install from CRAN install.packages("sparklyr") # Or install the latest master version from GitHub install.packages("devtools") devtools::install_github("sparklyr/sparklyr")激活安装了 Databricks Connect 正确版本的 Python 环境,并在终端中运行以下命令来获取
<spark-home-path>:databricks-connect get-spark-home启动 Spark 会话,开始运行 sparklyr 命令。
library(sparklyr) sc <- spark_connect(method = "databricks", spark_home = "<spark-home-path>") iris_tbl <- copy_to(sc, iris, overwrite = TRUE) library(dplyr) src_tbls(sc) iris_tbl %>% count关闭连接。
spark_disconnect(sc)
资源
有关详细信息,请参阅 sparklyr GitHub README。
有关代码示例,请参阅 sparklyr。
sparklyr 和 RStudio Desktop 限制
不支持以下功能:
- sparklyr streaming API
- sparklyr ML API接口
- broom APIs(API接口)
- csv_file 序列化模式
- spark 提交
IntelliJ(Scala 或 Java)
若要将 Databricks Connect 与 IntelliJ(Scala 或 Java)配合使用,请执行以下操作:
运行
databricks-connect get-jar-dir。将依赖项指向从命令返回的目录。 转到“文件”>“项目结构”>“模块”>“依赖项”>“+ 号”>“JAR 或目录”。
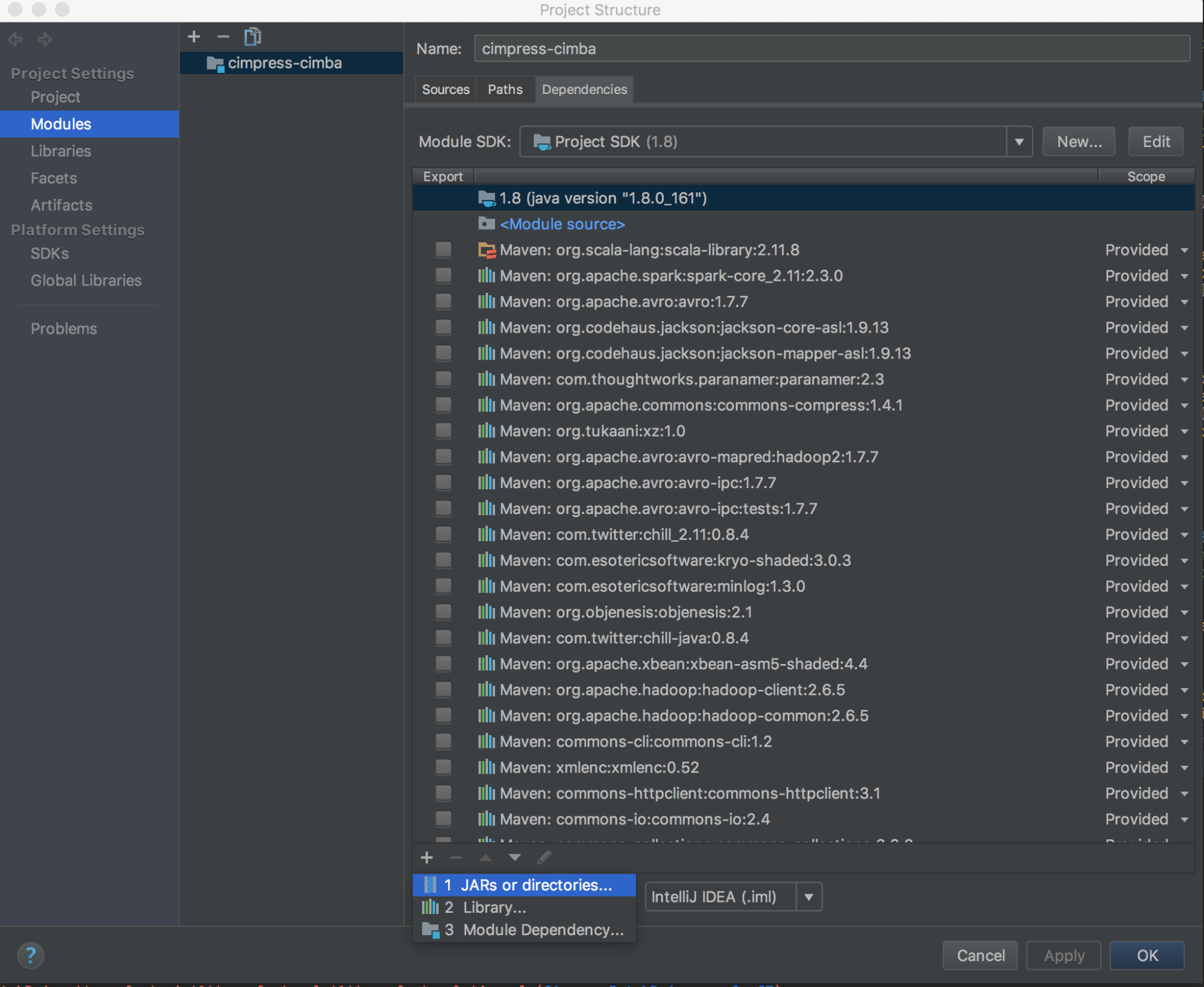
为避免冲突,强烈建议从类路径中删除其他所有 Spark 安装项。 如果做不到,请确保添加的 JAR 文件位于类路径的前面。 特别是,它们必须在其他所有已安装的 Spark 版本之前(否则将使用其他 Spark 版本并在本地运行,或者将引发
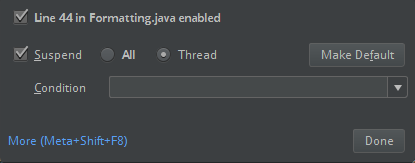
ClassDefNotFoundError)。检查 IntelliJ 中分类选项的设置。 默认设置为“全部”;如果设置调试断点,则将导致网络超时。 将其设置为“线程”,以避免停止后台网络线程。
PyDev 与 Eclipse
若要将 Databricks Connect 与 PyDev 和 Eclipse 配合使用,请按以下说明操作。
启动 Eclipse。
创建项目:单击“文件”>“新建”>“项目”>“PyDev”>“PyDev 项目”,然后单击“下一步”。
指定一个项目名称。
对于“项目内容”,请指定 Python 虚拟环境的路径。
单击“请在继续之前配置解释器”。
单击“手动配置”。
单击“新建”>“浏览 python/pypy exe”。
浏览并选择从虚拟环境引用的 Python 解释器的完整路径,然后单击“打开”。
在“选择解释器”对话框中,单击“确定”。
在“需要选择”对话框中,单击“确定”。
在“首选项”对话框中,单击“应用并关闭”。
在“PyDev 项目”对话框中,单击“完成”。
单击“打开透视图”。
把包含
.py或您自己代码的 Python 代码 () 文件添加到项目中。 如果你使用自己的代码,则至少必须实例化SparkSession.builder.getOrCreate()的实例,如示例代码中所示。打开 Python 代码文件后,在希望代码在运行过程中暂停的位置设置任何断点。
单击 运行 > 或 运行 > 调试。
有关更具体的运行和调试说明,请参阅运行程序。
Eclipse
若要使用 Databricks Connect 和 Eclipse,请执行以下操作:
运行
databricks-connect get-jar-dir。将外部 JAR 配置指向从命令返回的目录。 转到“项目菜单”>“属性”>“Java 生成路径”>“库”>“添加外部 JAR”。
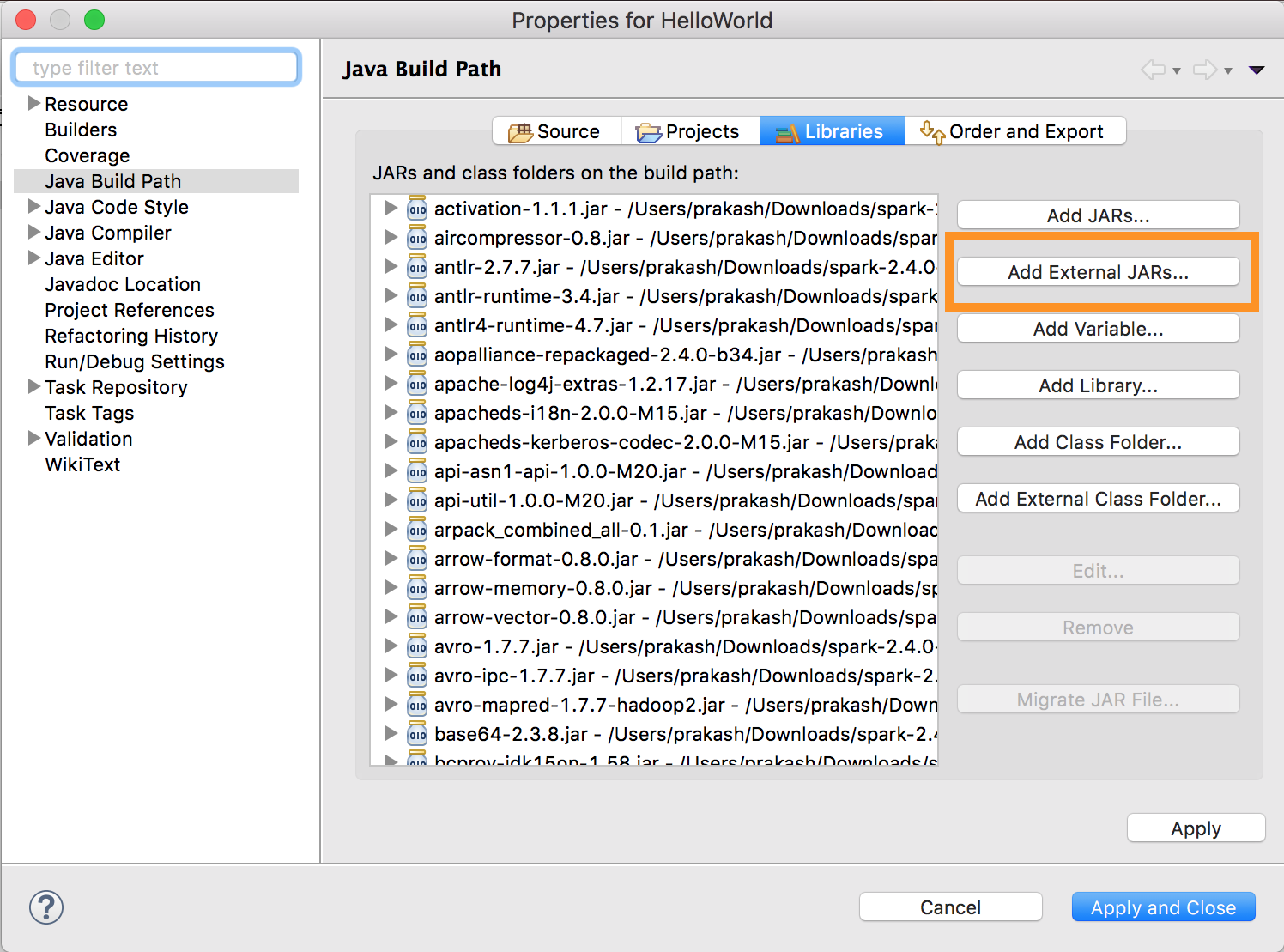
为避免冲突,强烈建议从类路径中删除其他所有 Spark 安装项。 如果做不到,请确保添加的 JAR 文件位于类路径的前面。 特别是,它们必须在其他所有已安装的 Spark 版本之前(否则将使用其他 Spark 版本并在本地运行,或者将引发
ClassDefNotFoundError)。
SBT
若要将 Databricks Connect 与 SBT 配合使用,必须将 build.sbt 文件配置为针对 Databricks Connect JAR(而不是一般的 Spark 库依赖项)进行链接。 使用以下示例生成文件中的 unmanagedBase 指令执行此操作,该文件假定 Scala 应用具有 com.example.Test 主对象:
build.sbt
name := "hello-world"
version := "1.0"
scalaVersion := "2.11.6"
// this should be set to the path returned by ``databricks-connect get-jar-dir``
unmanagedBase := new java.io.File("/usr/local/lib/python2.7/dist-packages/pyspark/jars")
mainClass := Some("com.example.Test")
Spark命令行
若要将 Databricks Connect 与 Spark shell 和 Python 或 Scala 配合使用,请按以下说明操作。
在激活虚拟环境后,确保 “设置客户端” 中的
databricks-connect test命令成功运行。在激活虚拟环境后,启动 Spark shell。 对于 Python,运行
pyspark命令。 对于 Scala,运行spark-shell命令。# For Python: pyspark# For Scala: spark-shell此时会显示 Spark shell,例如对于 Python,将显示:
Python 3... (v3...) [Clang 6... (clang-6...)] on darwin Type "help", "copyright", "credits" or "license" for more information. Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 3.... /_/ Using Python version 3... (v3...) Spark context Web UI available at http://...:... Spark context available as 'sc' (master = local[*], app id = local-...). SparkSession available as 'spark'. >>>对于 Scala:
Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Spark context Web UI available at http://... Spark context available as 'sc' (master = local[*], app id = local-...). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 3... /_/ Using Scala version 2... (OpenJDK 64-Bit Server VM, Java 1.8...) Type in expressions to have them evaluated. Type :help for more information. scala>有关如何配合使用 Spark shell 和 Python 或 Scala 在群集上运行命令的信息,请参阅使用 Spark Shell 进行交互式分析。
请在运行的集群中使用内置的
spark变量来表示SparkSession,例如用于 Python:>>> df = spark.read.table("samples.nyctaxi.trips") >>> df.show(5) +--------------------+---------------------+-------------+-----------+----------+-----------+ |tpep_pickup_datetime|tpep_dropoff_datetime|trip_distance|fare_amount|pickup_zip|dropoff_zip| +--------------------+---------------------+-------------+-----------+----------+-----------+ | 2016-02-14 16:52:13| 2016-02-14 17:16:04| 4.94| 19.0| 10282| 10171| | 2016-02-04 18:44:19| 2016-02-04 18:46:00| 0.28| 3.5| 10110| 10110| | 2016-02-17 17:13:57| 2016-02-17 17:17:55| 0.7| 5.0| 10103| 10023| | 2016-02-18 10:36:07| 2016-02-18 10:41:45| 0.8| 6.0| 10022| 10017| | 2016-02-22 14:14:41| 2016-02-22 14:31:52| 4.51| 17.0| 10110| 10282| +--------------------+---------------------+-------------+-----------+----------+-----------+ only showing top 5 rows对于 Scala:
>>> val df = spark.read.table("samples.nyctaxi.trips") >>> df.show(5) +--------------------+---------------------+-------------+-----------+----------+-----------+ |tpep_pickup_datetime|tpep_dropoff_datetime|trip_distance|fare_amount|pickup_zip|dropoff_zip| +--------------------+---------------------+-------------+-----------+----------+-----------+ | 2016-02-14 16:52:13| 2016-02-14 17:16:04| 4.94| 19.0| 10282| 10171| | 2016-02-04 18:44:19| 2016-02-04 18:46:00| 0.28| 3.5| 10110| 10110| | 2016-02-17 17:13:57| 2016-02-17 17:17:55| 0.7| 5.0| 10103| 10023| | 2016-02-18 10:36:07| 2016-02-18 10:41:45| 0.8| 6.0| 10022| 10017| | 2016-02-22 14:14:41| 2016-02-22 14:31:52| 4.51| 17.0| 10110| 10282| +--------------------+---------------------+-------------+-----------+----------+-----------+ only showing top 5 rows若要停止 Spark shell,请按
Ctrl + d或Ctrl + z,或者运行命令quit()或exit()(对于 Python),或运行:q或:quit(对于 Scala)。
代码示例
此简单代码示例查询指定的表,然后显示指定的表的前 5 行。 若要使用其他表,请调整对 spark.read.table 的调用。
from pyspark.sql.session import SparkSession
spark = SparkSession.builder.getOrCreate()
df = spark.read.table("samples.nyctaxi.trips")
df.show(5)
此较长代码示例执行以下操作:
创建内存中数据帧。
在
zzz_demo_temps_table架构中创建名为default的表。 如果已存在同名的表,则先删除该表。 若要使用其他架构或表,请调整对spark.sql和/或temps.write.saveAsTable的调用。将数据帧的内容保存到表中。
对表的内容运行
SELECT查询。显示查询的结果。
删除表。
Python
from pyspark.sql import SparkSession
from pyspark.sql.types import *
from datetime import date
spark = SparkSession.builder.appName('temps-demo').getOrCreate()
# Create a Spark DataFrame consisting of high and low temperatures
# by airport code and date.
schema = StructType([
StructField('AirportCode', StringType(), False),
StructField('Date', DateType(), False),
StructField('TempHighF', IntegerType(), False),
StructField('TempLowF', IntegerType(), False)
])
data = [
[ 'BLI', date(2021, 4, 3), 52, 43],
[ 'BLI', date(2021, 4, 2), 50, 38],
[ 'BLI', date(2021, 4, 1), 52, 41],
[ 'PDX', date(2021, 4, 3), 64, 45],
[ 'PDX', date(2021, 4, 2), 61, 41],
[ 'PDX', date(2021, 4, 1), 66, 39],
[ 'SEA', date(2021, 4, 3), 57, 43],
[ 'SEA', date(2021, 4, 2), 54, 39],
[ 'SEA', date(2021, 4, 1), 56, 41]
]
temps = spark.createDataFrame(data, schema)
# Create a table on the Databricks cluster and then fill
# the table with the DataFrame's contents.
# If the table already exists from a previous run,
# delete it first.
spark.sql('USE default')
spark.sql('DROP TABLE IF EXISTS zzz_demo_temps_table')
temps.write.saveAsTable('zzz_demo_temps_table')
# Query the table on the Databricks cluster, returning rows
# where the airport code is not BLI and the date is later
# than 2021-04-01. Group the results and order by high
# temperature in descending order.
df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " \
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " \
"GROUP BY AirportCode, Date, TempHighF, TempLowF " \
"ORDER BY TempHighF DESC")
df_temps.show()
# Results:
#
# +-----------+----------+---------+--------+
# |AirportCode| Date|TempHighF|TempLowF|
# +-----------+----------+---------+--------+
# | PDX|2021-04-03| 64| 45|
# | PDX|2021-04-02| 61| 41|
# | SEA|2021-04-03| 57| 43|
# | SEA|2021-04-02| 54| 39|
# +-----------+----------+---------+--------+
# Clean up by deleting the table from the Databricks cluster.
spark.sql('DROP TABLE zzz_demo_temps_table')
Scala(编程语言)
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
import java.sql.Date
object Demo {
def main(args: Array[String]) {
val spark = SparkSession.builder.master("local").getOrCreate()
// Create a Spark DataFrame consisting of high and low temperatures
// by airport code and date.
val schema = StructType(Array(
StructField("AirportCode", StringType, false),
StructField("Date", DateType, false),
StructField("TempHighF", IntegerType, false),
StructField("TempLowF", IntegerType, false)
))
val data = List(
Row("BLI", Date.valueOf("2021-04-03"), 52, 43),
Row("BLI", Date.valueOf("2021-04-02"), 50, 38),
Row("BLI", Date.valueOf("2021-04-01"), 52, 41),
Row("PDX", Date.valueOf("2021-04-03"), 64, 45),
Row("PDX", Date.valueOf("2021-04-02"), 61, 41),
Row("PDX", Date.valueOf("2021-04-01"), 66, 39),
Row("SEA", Date.valueOf("2021-04-03"), 57, 43),
Row("SEA", Date.valueOf("2021-04-02"), 54, 39),
Row("SEA", Date.valueOf("2021-04-01"), 56, 41)
)
val rdd = spark.sparkContext.makeRDD(data)
val temps = spark.createDataFrame(rdd, schema)
// Create a table on the Databricks cluster and then fill
// the table with the DataFrame's contents.
// If the table already exists from a previous run,
// delete it first.
spark.sql("USE default")
spark.sql("DROP TABLE IF EXISTS zzz_demo_temps_table")
temps.write.saveAsTable("zzz_demo_temps_table")
// Query the table on the Databricks cluster, returning rows
// where the airport code is not BLI and the date is later
// than 2021-04-01. Group the results and order by high
// temperature in descending order.
val df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " +
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " +
"GROUP BY AirportCode, Date, TempHighF, TempLowF " +
"ORDER BY TempHighF DESC")
df_temps.show()
// Results:
//
// +-----------+----------+---------+--------+
// |AirportCode| Date|TempHighF|TempLowF|
// +-----------+----------+---------+--------+
// | PDX|2021-04-03| 64| 45|
// | PDX|2021-04-02| 61| 41|
// | SEA|2021-04-03| 57| 43|
// | SEA|2021-04-02| 54| 39|
// +-----------+----------+---------+--------+
// Clean up by deleting the table from the Databricks cluster.
spark.sql("DROP TABLE zzz_demo_temps_table")
}
}
Java
import java.util.ArrayList;
import java.util.List;
import java.sql.Date;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.*;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.Dataset;
public class App {
public static void main(String[] args) throws Exception {
SparkSession spark = SparkSession
.builder()
.appName("Temps Demo")
.config("spark.master", "local")
.getOrCreate();
// Create a Spark DataFrame consisting of high and low temperatures
// by airport code and date.
StructType schema = new StructType(new StructField[] {
new StructField("AirportCode", DataTypes.StringType, false, Metadata.empty()),
new StructField("Date", DataTypes.DateType, false, Metadata.empty()),
new StructField("TempHighF", DataTypes.IntegerType, false, Metadata.empty()),
new StructField("TempLowF", DataTypes.IntegerType, false, Metadata.empty()),
});
List<Row> dataList = new ArrayList<Row>();
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-03"), 52, 43));
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-02"), 50, 38));
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-01"), 52, 41));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-03"), 64, 45));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-02"), 61, 41));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-01"), 66, 39));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-03"), 57, 43));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-02"), 54, 39));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-01"), 56, 41));
Dataset<Row> temps = spark.createDataFrame(dataList, schema);
// Create a table on the Databricks cluster and then fill
// the table with the DataFrame's contents.
// If the table already exists from a previous run,
// delete it first.
spark.sql("USE default");
spark.sql("DROP TABLE IF EXISTS zzz_demo_temps_table");
temps.write().saveAsTable("zzz_demo_temps_table");
// Query the table on the Databricks cluster, returning rows
// where the airport code is not BLI and the date is later
// than 2021-04-01. Group the results and order by high
// temperature in descending order.
Dataset<Row> df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " +
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " +
"GROUP BY AirportCode, Date, TempHighF, TempLowF " +
"ORDER BY TempHighF DESC");
df_temps.show();
// Results:
//
// +-----------+----------+---------+--------+
// |AirportCode| Date|TempHighF|TempLowF|
// +-----------+----------+---------+--------+
// | PDX|2021-04-03| 64| 45|
// | PDX|2021-04-02| 61| 41|
// | SEA|2021-04-03| 57| 43|
// | SEA|2021-04-02| 54| 39|
// +-----------+----------+---------+--------+
// Clean up by deleting the table from the Databricks cluster.
spark.sql("DROP TABLE zzz_demo_temps_table");
}
}
处理依赖项
通常,主类或 Python 文件将具有其他依赖项 JAR 和文件。 可通过调用 sparkContext.addJar("path-to-the-jar") 或 sparkContext.addPyFile("path-to-the-file") 来添加这类依赖项 JAR 和文件。 还可使用 addPyFile() 接口添加 Egg 文件和 zip 文件。 每次在 IDE 中运行代码时,都会在群集上安装依赖项 JAR 和文件。
Python
from lib import Foo
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
sc = spark.sparkContext
#sc.setLogLevel("INFO")
print("Testing simple count")
print(spark.range(100).count())
print("Testing addPyFile isolation")
sc.addPyFile("lib.py")
print(sc.parallelize(range(10)).map(lambda i: Foo(2)).collect())
class Foo(object):
def __init__(self, x):
self.x = x
Python + Java UDF
from pyspark.sql import SparkSession
from pyspark.sql.column import _to_java_column, _to_seq, Column
## In this example, udf.jar contains compiled Java / Scala UDFs:
#package com.example
#
#import org.apache.spark.sql._
#import org.apache.spark.sql.expressions._
#import org.apache.spark.sql.functions.udf
#
#object Test {
# val plusOne: UserDefinedFunction = udf((i: Long) => i + 1)
#}
spark = SparkSession.builder \
.config("spark.jars", "/path/to/udf.jar") \
.getOrCreate()
sc = spark.sparkContext
def plus_one_udf(col):
f = sc._jvm.com.example.Test.plusOne()
return Column(f.apply(_to_seq(sc, [col], _to_java_column)))
sc._jsc.addJar("/path/to/udf.jar")
spark.range(100).withColumn("plusOne", plus_one_udf("id")).show()
Scala(编程语言)
package com.example
import org.apache.spark.sql.SparkSession
case class Foo(x: String)
object Test {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
...
.getOrCreate();
spark.sparkContext.setLogLevel("INFO")
println("Running simple show query...")
spark.read.format("parquet").load("/tmp/x").show()
println("Running simple UDF query...")
spark.sparkContext.addJar("./target/scala-2.11/hello-world_2.11-1.0.jar")
spark.udf.register("f", (x: Int) => x + 1)
spark.range(10).selectExpr("f(id)").show()
println("Running custom objects query...")
val objs = spark.sparkContext.parallelize(Seq(Foo("bye"), Foo("hi"))).collect()
println(objs.toSeq)
}
}
访问 Databricks 实用工具
本部分介绍如何使用 Databricks Connect 访问 Databricks 实用工具。
可以使用dbutils.fs和dbutils.secrets实用工具以及Databricks Utilities(dbutils)参考模块。
支持的命令为:dbutils.fs.cp、dbutils.fs.head、dbutils.fs.ls、dbutils.fs.mkdirs、dbutils.fs.mv、dbutils.fs.put、dbutils.fs.rm、dbutils.secrets.getdbutils.secrets.getBytes、dbutils.secrets.list、dbutils.secrets.listScopes。
请参阅文件系统实用程序 (dbutils.fs) 或运行 dbutils.fs.help() 和 机密实用程序 (dbutils.secrets) 或运行 dbutils.secrets.help()。
Python
from pyspark.sql import SparkSession
from pyspark.dbutils import DBUtils
spark = SparkSession.builder.getOrCreate()
dbutils = DBUtils(spark)
print(dbutils.fs.ls("dbfs:/"))
print(dbutils.secrets.listScopes())
使用 Databricks Runtime 7.3 LTS 或更高版本时,若要在本地和 Azure Databricks 群集中都能访问 DBUtils 模块,请使用以下 get_dbutils():
def get_dbutils(spark):
from pyspark.dbutils import DBUtils
return DBUtils(spark)
否则,可以使用以下 get_dbutils():
def get_dbutils(spark):
if spark.conf.get("spark.databricks.service.client.enabled") == "true":
from pyspark.dbutils import DBUtils
return DBUtils(spark)
else:
import IPython
return IPython.get_ipython().user_ns["dbutils"]
Scala(编程语言)
val dbutils = com.databricks.service.DBUtils
println(dbutils.fs.ls("dbfs:/"))
println(dbutils.secrets.listScopes())
在本地和远程文件系统之间复制文件
可以使用 dbutils.fs 在客户端和远程文件系统之间复制文件。 方案 file:/ 指的是客户端上的本地文件系统。
from pyspark.dbutils import DBUtils
dbutils = DBUtils(spark)
dbutils.fs.cp('file:/home/user/data.csv', 'dbfs:/uploads')
dbutils.fs.cp('dbfs:/output/results.csv', 'file:/home/user/downloads/')
可以传输的最大文件大小为 250 MB。
启用 dbutils.secrets.get
由于安全限制,默认情况下会禁用调用 dbutils.secrets.get 的功能。 请联系 Azure Databricks 支持人员为你的工作区启用此功能。
设置 Hadoop 配置
在客户端上,可使用 spark.conf.set API 设置 Hadoop 配置,该 API 适用于 SQL 和 DataFrame 操作。 在 sparkContext 上设置的 Hadoop 配置必须在群集配置中进行设置或使用笔记本。 这是因为在 sparkContext 上设置的配置没有绑定到用户会话,而是应用于整个群集。
故障排除
运行 databricks-connect test 以检查连接问题。 本部分描述在使用 Databricks Connect 时可能会遇到的一些常见问题及其解决方法。
本节内容:
- Python 版本不匹配
- 未启用服务器
- PySpark 安装存在冲突
-
冲突
SPARK_HOME -
二进制文件的
PATH条目冲突或缺失 - 群集上的序列化设置存在冲突
-
无法在 Windows 上找到
winutils.exe - Windows 上的文件名、目录名称或卷标签语法不正确
Python 版本不匹配
确保您在本地使用的 Python 版本至少与集群上的版本具有相同的次要版本号(例如,3.9.16 与 3.9.15 是可以的,而 3.9 与 3.8 则不可以)。
如果本地安装了多个 Python 版本,请设置 PYSPARK_PYTHON 环境变量(例如 PYSPARK_PYTHON=python3),确保 Databricks Connect 使用的版本是正确的。
未启用服务器
确保群集已启用 spark.databricks.service.server.enabled true Spark 服务器。 如果已启用,则应会在驱动程序日志中看到以下行:
../../.. ..:..:.. INFO SparkConfUtils$: Set spark config:
spark.databricks.service.server.enabled -> true
...
../../.. ..:..:.. INFO SparkContext: Loading Spark Service RPC Server
../../.. ..:..:.. INFO SparkServiceRPCServer:
Starting Spark Service RPC Server
../../.. ..:..:.. INFO Server: jetty-9...
../../.. ..:..:.. INFO AbstractConnector: Started ServerConnector@6a6c7f42
{HTTP/1.1,[http/1.1]}{0.0.0.0:15001}
../../.. ..:..:.. INFO Server: Started @5879ms
PySpark 安装冲突
databricks-connect 包与 PySpark 冲突。 在 Python 中初始化 Spark 上下文时,安装这两种都会导致错误。 这可能以多种方式显示出来,包括“流已损坏”或“找不到类”错误。 如果已在 Python 环境中安装 PySpark,请确保先卸载它,然后再安装 databricks-connect。 卸载 PySpark 后,请确保彻底重新安装 Databricks Connect 包:
pip3 uninstall pyspark
pip3 uninstall databricks-connect
pip3 install --upgrade "databricks-connect==12.2.*" # or X.Y.* to match your specific cluster version.
SPARK_HOME 冲突
如果你之前在计算机上使用过 Spark,则 IDE 可能配置为使用 Spark 的某个其他版本,而不是 Databricks Connect Spark。 这可能以多种方式显示出来,包括“流已损坏”或“找不到类”错误。 可检查 SPARK_HOME 环境变量的值来查看正在使用哪个版本的 Spark:
Python
import os
print(os.environ['SPARK_HOME'])
Scala(编程语言)
println(sys.env.get("SPARK_HOME"))
Java
System.out.println(System.getenv("SPARK_HOME"));
解决方法
如果设置 SPARK_HOME,使其使用的 Spark 版本与客户端中的版本不同,则应取消设置 SPARK_HOME 变量,然后重试。
检查 IDE 环境变量设置,检查 .bashrc、.zshrc 或 .bash_profile 文件,还要检查可能设置了环境变量的其他所有位置。 你很可能必须退出再重启 IDE 来清除旧状态;如果问题仍然存在,甚至可能需要创建新项目。
无需将 SPARK_HOME 设置为新值;取消设置就已足够。
二进制文件的 PATH 项冲突或缺失
你的 PATH 可能配置为使得 spark-shell 等命令将运行其他之前安装的某些二进制文件,而不是运行与 Databricks Connect 一起提供的那个。 这可能会导致 databricks-connect test 失败。 应确保优先使用 Databricks Connect 二进制文件,或者删除之前安装的二进制文件。
如果无法运行 spark-shell 之类的命令,也可能是 pip3 install 未自动设置 PATH,你需要将 bin dir 手动安装到 PATH 中。 即使未设置此项,也可将 Databricks Connect 与 IDE 一起使用。 但是,databricks-connect test 命令将不起作用。
群集上的序列化设置存在冲突
如果在运行 databricks-connect test 时看到“流已损坏”错误,则可能是因群集序列化配置不兼容造成的。 例如,设置 spark.io.compression.codec 配置可能会导致此问题。 若要解决此问题,请考虑从群集设置中删除这些配置,或在 Databricks Connect 客户端中设置配置。
无法在 Windows 上找到 winutils.exe
如果您在 Windows 上使用 Databricks Connect 并看到:
ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
Windows 上的文件名、目录名称或卷标签语法不正确
如果您在使用 Windows 和 Databricks Connect 时遇到以下情况:
The filename, directory name, or volume label syntax is incorrect.
Java 或 Databricks Connect 已安装到路径中带有空格的目录中。 要解决此问题,可安装到不带空格的目录路径或使用短名称格式配置路径。
使用 Microsoft Entra ID 令牌进行身份验证
注意
以下信息仅适用于 Databricks Connect 版本 7.3.5 到 12.2.x。
适用于 Databricks Runtime 13.3 LTS 及更高版本的 Databricks Connect 目前不支持 Microsoft Entra ID 令牌。
使用 Databricks Connect 版本 7.3.5 到 12.2.x 时,可以使用 Microsoft Entra ID 令牌而不是个人访问令牌进行身份验证。 Microsoft Entra ID 令牌的生存期有限。 当 Microsoft Entra ID 令牌过期时,Databricks Connect 会失败并出现“Invalid Token”错误。
对于 Databricks Connect 版本 7.3.5 到 12.2.x,可以在正在运行的 Databricks Connect 应用程序中提供 Microsoft Entra ID 令牌。 应用程序需要获取新的访问令牌,并将其设置为 spark.databricks.service.token SQL 配置密钥。
Python
spark.conf.set("spark.databricks.service.token", new_aad_token)
Scala(编程语言)
spark.conf.set("spark.databricks.service.token", newAADToken)
更新令牌后,应用程序可继续使用相同的 SparkSession 以及在会话上下文中创建的任何对象和状态。 为了避免间歇性错误,Databricks 建议在旧令牌过期之前提供新令牌。
可以延长 Microsoft Entra ID 令牌的生存期,以在应用程序执行期间持久保存它。 为此,请将具有适当生存期的 TokenLifetimePolicy 附加到用于获取访问令牌的 Microsoft Entra ID 身份验证应用程序上。
注意
Microsoft Entra ID 直通使用两个令牌:之前介绍的在 Databricks Connect 版本 7.3.5 到 12.2.x 中配置的 Microsoft Entra ID 访问令牌,以及 Databricks 在处理请求时生成的特定资源的 ADLS 直通令牌。 不能使用 Microsoft Entra ID 令牌生存期策略来延长 ADLS Passthrough 令牌的有效期。 如果向群集发送耗时超过一小时的命令,并且该命令在 1 小时标记期过后访问 ADLS 资源,则该命令会失败。
限制
- Unity Catalog。
- 结构化流。
- 在远程群集上运行未包含在 Spark 作业中的任意代码。
- 不支持用于 Delta 表操作的原生 Scala、Python 和 R API(例如
DeltaTable.forPath)。 但是,具有 Delta Lake 操作的 SQL API (spark.sql(...)) 和 Delta 表上的 Spark API(例如spark.read.load)都受支持。 - 复制到。
- 使用作为服务器目录一部分的 SQL 函数、Python 或 Scala UDF。 但是,本地引入的 Scala 和 Python UDF 可以正常工作。
- Apache Zeppelin 0.7.x 及更低版本。
- 使用表访问控制连接到群集。
- 连接到启用了进程隔离的群集(换句话说,
spark.databricks.pyspark.enableProcessIsolation设置为true)。 - Delta
CLONESQL 命令。 - 全局临时视图。
-
考拉和
pyspark.pandas。 -
CREATE TABLE table AS SELECT ...SQL 命令并不总是有效。 请改用spark.sql("SELECT ...").write.saveAsTable("table")。 - Microsoft Entra ID 凭据传递仅在运行 Databricks Runtime 7.3 LTS 和更高版本的标准群集上受支持,且与服务主体身份验证不兼容。
- 以下Databricks Utilities (
dbutils)参考资料: