本教程演示如何使用 IntelliJ IDEA 和 Scala 插件开始使用 Databricks Connect for Scala。
在本教程中,你将在 IntelliJ IDEA 中创建项目,安装 Databricks Connect for Databricks Runtime 13.3 LTS 及更高版本,并在 IntelliJ IDEA 的 Databricks 工作区中的计算上运行简单代码。
小窍门
若要了解如何使用声明性自动化捆绑包创建在无服务器计算上运行代码的 Scala 项目,请参阅 使用声明性自动化捆绑包生成 Scala JAR。
要求
若要完成此教程,必须满足以下要求:
工作区、本地环境和计算能力满足用于 Scala 的 Databricks Connect 的要求。 请参阅 Databricks Connect 使用情况要求。
您必须具备群集 ID。 若要获取群集 ID,请在工作区中单击边栏上的 “计算 ”,然后单击群集的名称。 在您的 Web 浏览器的地址栏中,复制位于
clusters和configuration之间的 URL 字符串。已在开发计算机上安装Java开发工具包(JDK)。 有关要安装的版本的信息,请参阅 版本支持矩阵。
注释
如果未安装 JDK,或者开发计算机上安装了多个 JDK,则可以在步骤 1 后面安装或选择特定的 JDK。 在群集上选择低于或高于 JDK 版本的 JDK 安装可能会产生意外结果,或者代码根本无法运行。
已安装 IntelliJ IDEA 。 本教程已使用 IntelliJ IDEA Community Edition 2023.3.6 进行测试。 如果使用不同版本的 IntelliJ IDEA,则以下说明可能有所不同。
已安装用于 IntelliJ IDEA 的 Scala 插件 。
步骤 1:配置Azure Databricks身份验证
本教程使用 Azure Databricks OAuth 用户到计算机(U2M)身份验证和 Azure Databricks 配置文件来对 Azure Databricks 工作区进行身份验证。 若要改用其他身份验证类型,请参阅 “配置连接属性”。
配置 OAuth U2M 身份验证需要 Databricks CLI,如下所示:
安装 Databricks CLI:
Linux、macOS
通过运行以下命令,使用 Homebrew 安装 Databricks CLI:
brew tap databricks/tap brew install databricksWindows
可以使用 winget、Chocolatey 或 适用于 Linux 的 Windows 子系统 (WSL)来安装 Databricks CLI。 如果您无法使用
winget、Chocolatey 或 WSL,则应跳过此过程,改用命令提示符或 PowerShell 从源安装 Databricks CLI。
注释
使用 Chocolatey 安装 Databricks CLI 是 实验性的。
若要使用 winget 安装 Databricks CLI,请运行以下两个命令,然后重启您的命令提示符窗口:
winget search databricks
winget install Databricks.DatabricksCLI
若要使用 Chocolatey 安装 Databricks CLI,请运行以下命令:
choco install databricks-cli
若要使用 WSL 安装 Databricks CLI,
通过 WSL 安装
curl和zip。 有关详细信息,请参阅操作系统的文档。运行以下命令,使用 WSL 安装 Databricks CLI:
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh通过运行以下命令确认 Databricks CLI 是否已安装,该命令将显示已安装的 Databricks CLI 的当前版本。 此版本应为 0.205.0 或更高版本:
databricks -v
启动 OAuth U2M 身份验证,如下所示:
通过为每个目标工作区运行以下命令,使用 Databricks CLI 在本地启动 OAuth 令牌管理。
在以下命令中,将
<workspace-url>替换为 Azure Databricks per-workspace URL,例如https://adb-1234567890123456.7.databricks.azure.cn。databricks auth login --configure-cluster --host <workspace-url>Databricks CLI 会提示保存输入的信息作为 Azure Databricks configuration 配置文件。 按下
Enter接受建议的配置文件名称,或输入新配置文件或现有配置文件的名称。 使用输入的信息覆盖同名的任何现有配置文件。 可以使用配置文件跨多个工作区快速切换身份验证上下文。若要获取任何现有配置文件的列表,请在单独的终端或命令提示符中使用 Databricks CLI 来运行
databricks auth profiles命令。 要查看特定配置文件的现有设置,请运行命令databricks auth env --profile <profile-name>。在 Web 浏览器中,按照屏幕上的说明完成 Azure Databricks 工作区的登录。
在终端或命令提示符中显示的可用群集列表中,使用向上键和向下键选择工作区中的目标Azure Databricks群集,然后按
Enter。 还可以键入群集显示名称的任何部分来筛选可用群集的列表。要查看配置文件的当前 OAuth 令牌值和令牌即将过期的时间戳,请运行以下命令之一:
databricks auth token --host <workspace-url>databricks auth token -p <profile-name>databricks auth token --host <workspace-url> -p <profile-name>
如果你有多个配置文件有相同的
--host值,则可能需要同时指定--host和-p选项,以便 Databricks CLI 找到正确的匹配 OAuth 令牌信息。
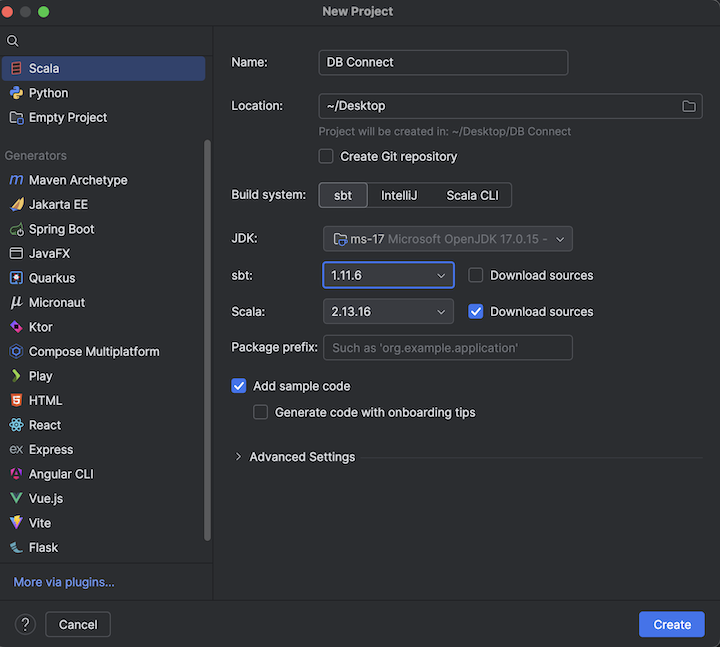
步骤 2:创建项目
启动 IntelliJ IDEA。
在主菜单上,单击“File >新建> Project。
为项目提供一些有意义的 名称。
对于 “位置”,请单击文件夹图标,并完成屏幕指示以指定新 Scala 项目的路径。
对于 语言,请单击 Scala。
在 构建系统 中,点击 sbt。
在 JDK 下拉列表中,选择与群集上的 JDK 版本匹配的开发计算机上 JDK 的现有安装,或选择“ 下载 JDK ”,然后按照屏幕上的说明下载与群集上的 JDK 版本匹配的 JDK。 请参阅 要求。
注释
在群集上选择高于或低于 JDK 版本的 JDK 安装可能会产生意外结果,或者代码根本无法运行。
在 sbt 下拉列表中,选择最新版本。
在 Scala 下拉列表中,选择与群集上的 Scala 版本匹配的 Scala 版本。 请参阅 要求。
注释
选择一个低于或高于您的群集上的 Scala 版本的版本,可能会产生意外结果,或者代码根本无法运行。
确保选中 Scala 旁边的“下载源”框。
对于 包前缀,输入项目的源的一些包前缀值,例如
org.example.application。确保选中 “添加示例代码 ”框。
单击 “创建” 。
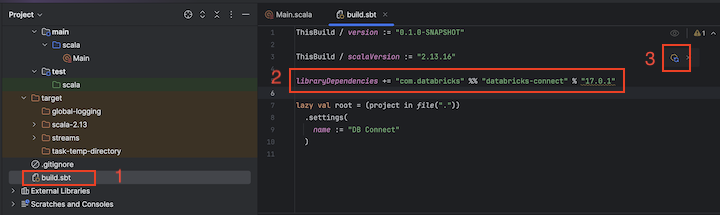
步骤 3:添加 Databricks Connect 包
打开您的新的 Scala 项目后,在 Project 工具窗口中(查看 > 工具窗口 > 项目),打开
build.sbt中名为 的文件。将以下代码添加到文件的末尾
build.sbt,该文件声明项目依赖于适用于 Scala 的特定版本的 Databricks Connect 库,与群集的 Databricks Runtime 版本兼容:libraryDependencies += "com.databricks" %% "databricks-connect" % "17.3.+"将
17.3替换为与群集上的 Databricks Runtime 版本匹配的 Databricks Connect 库的版本。 例如,Databricks Connect 17.3.+ 与 Databricks Runtime 17.3 LTS 匹配。 可以在 Maven 中央存储库(适用于 Databricks Runtime 16.4 LTS 及更低版本) 或 Maven 中心存储库(适用于 Databricks Runtime 17.0 及更高版本)中找到 Databricks Connect 库版本号。注释
使用 Databricks Connect 构建项目时,请勿包括诸如 Apache Spark 工件(如
org.apache.spark:spark-core)在您的项目中。 而是直接针对 Databricks Connect 进行编译。单击 “加载 sbt 更改 通知”图标,使用新的库位置和依赖项更新 Scala 项目。
等到 IDE 底部的
sbt进度指示器消失为止。sbt加载过程可能需要几分钟才能完成。
步骤 4:添加代码
在Project工具窗口中,打开
Main.scala,路径为project-name> src > main > scala中的文件。将文件中的任何现有代码替换为以下代码,然后保存该文件,具体取决于配置文件的名称。
如果步骤 1 中的配置文件已命名
DEFAULT,请将该文件中的任何现有代码替换为以下代码,然后保存该文件:package org.example.application import com.databricks.connect.DatabricksSession import org.apache.spark.sql.SparkSession object Main { def main(args: Array[String]): Unit = { val spark = DatabricksSession.builder().remote().getOrCreate() val df = spark.read.table("samples.nyctaxi.trips") df.limit(5).show() } }如果步骤 1 中的配置文件未命名
DEFAULT,请改用以下代码替换文件中的任何现有代码。 将占位符<profile-name>替换为步骤 1 中的配置文件的名称,然后保存文件:package org.example.application import com.databricks.connect.DatabricksSession import com.databricks.sdk.core.DatabricksConfig import org.apache.spark.sql.SparkSession object Main { def main(args: Array[String]): Unit = { val config = new DatabricksConfig().setProfile("<profile-name>") val spark = DatabricksSession.builder().sdkConfig(config).getOrCreate() val df = spark.read.table("samples.nyctaxi.trips") df.limit(5).show() } }
步骤 5:配置 VM 选项
将包含
build.sbt的当前目录导入到 IntelliJ 中。在 IntelliJ 中选择Java 17。 转到 File>Project Structure>SDKs。
打开
src/main/scala/com/examples/Main.scala。导航到 Main 的配置以添加 VM 选项:

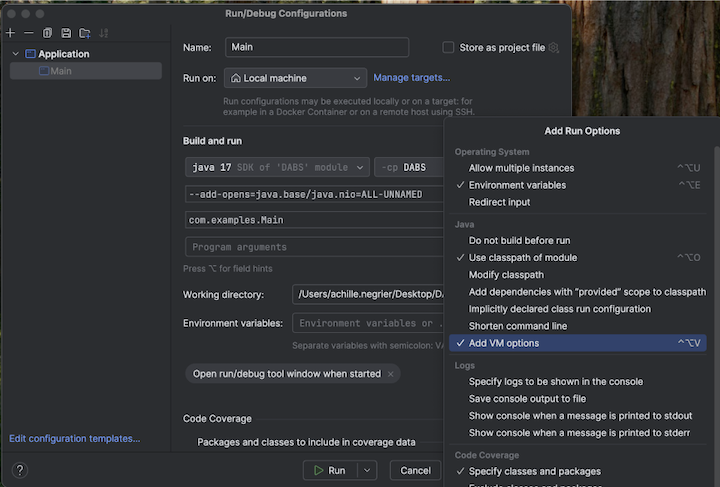
将以下内容添加到 VM 选项:
--add-opens=java.base/java.nio=ALL-UNNAMED
小窍门
或者,如果使用Visual Studio Code,请将以下内容添加到 sbt 生成文件中:
fork := true
javaOptions += "--add-opens=java.base/java.nio=ALL-UNNAMED"
然后从终端运行应用程序:
sbt run
步骤 6:运行代码
在远程Azure Databricks工作区中启动目标群集。
群集启动后,在主菜单中,点击“运行”然后选择“Main”>。
在 Run 工具窗口 (View > 工具 Windows > Run), Main 选项卡, 将显示
samples.nyctaxi.trips表的前 5 行。
步骤 7:调试代码
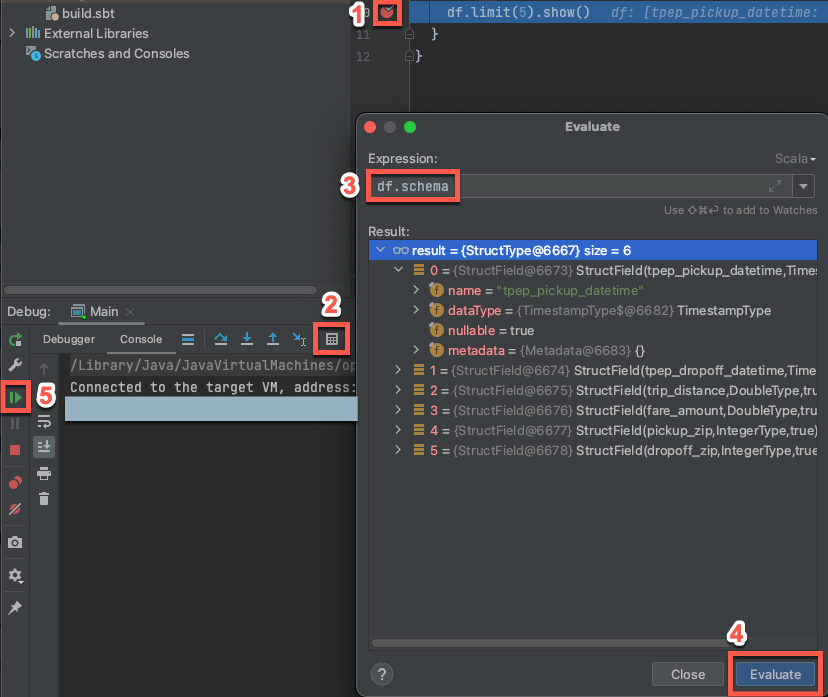
在目标群集仍在运行的情况下,在前面的代码中,单击
df.limit(5).show()旁边的装订线以设置断点。在主菜单中,单击“运行 > 调试 'Main'”。 在 Debug 工具窗口(View > 工具 windows > Debug)的 Console 选项卡,单击计算器(求值表达式)图标。
输入表达式
df.schema。单击“ 评估 ”以显示 DataFrame 的架构。
在 “调试 ”工具窗口的边栏中,单击绿色箭头(恢复程序)图标。 表的前 5 行
samples.nyctaxi.trips显示在 “控制台 ”窗格中。