重要
此功能目前以公共预览版提供。 可以在预览页面上确认加入状态。 请参阅 管理 Azure Databricks 预览版。
本文介绍如何使用 Lakeflow 管道编辑器开发和调试 Lakeflow Spark 声明性管道(SDP)中的 ETL(提取、转换和加载)管道。
注释
默认情况下,Lakeflow 管道编辑器处于启用状态。 可以将其关闭,或将其重新启用(如果已关闭)。 请参阅 “启用 Lakeflow 管道编辑器”和“更新后的监视”。
什么是 Lakeflow 管道编辑器?
Lakeflow 管道编辑器是为开发管道而构建的 IDE。 它将单个表面上的所有管道开发任务组合在一起,支持代码优先工作流、基于文件夹的代码组织、选择性执行、数据预览和管道图。 它与 Azure Databricks 平台集成,还支持版本控制、代码评审和计划运行。
Lakeflow 管道编辑器 UI 概述
下图显示了 Lakeflow 管道编辑器:

该图显示了以下功能:
包含选项卡的多文件代码编辑器:跨与管道关联的多个代码文件工作。
交互式定向无环图(DAG):获取表的概览,打开数据预览底部栏,并执行其他与表相关的操作。
表级执行见解:获取管道中所有表或单个表的执行见解。 见解源自最新的管道运行,
问题面板:此功能汇总了管道中所有文件中的错误,你可以导航到特定文件中发生错误的位置。 可对代码级错误指示形成补充。
选择性执行:代码编辑器具有分步开发的功能,例如,可以使用“运行文件”操作仅刷新当前文件中的表或单个表。
默认管道文件夹结构:新管道包括预定义的文件夹结构和示例代码,可用于管道的起点。
简化的管道创建:提供默认创建表的名称、目录和架构,并使用默认设置创建管道。 稍后可以从管道编辑器工具栏调整“设置”。
创建新的 ETL 管道
若要使用 Lakeflow 管道编辑器创建新的 ETL 管道,请执行以下步骤:
在边栏顶部,单击“新建”
 ,然后选择“ETL 管道”
,然后选择“ETL 管道” 。
。在顶部,您可以为您的管道提供一个独特的名称。
就在名称下,可以看到已为你选择的默认目录和架构。 更改这些选项,为管道提供不同的默认值。
默认 目录 和默认 架构 是在未在代码中使用目录或架构限定数据集时从中读取或写入数据集的位置。 有关详细信息,请参阅 Azure Databricks 中的数据库对象 。
选择以下选项之一,通过首选选项来创建管道:
- 从 SQL 中的示例代码开始 ,以创建新的管道和文件夹结构,包括 SQL 中的示例代码。
- 从 Python 中的示例代码开始 ,以创建新的管道和文件夹结构,包括 Python 中的示例代码。
- 首先,使用单个转换 创建新的管道和文件夹结构,并创建一个新的空白代码文件。
- 添加现有资产 以便创建可与工作区中的现有代码文件关联的管道。
可以在 ETL 管道中同时包含 SQL 和 Python 源代码文件。 创建新管道并选择示例代码的语言时,该语言仅适用于默认情况下包含在管道中的示例代码。
选择后,会重定向到新创建的管道。
ETL 管道是使用以下默认设置创建的:
可以从管道工具栏调整这些设置。
或者,可以从工作区浏览器创建 ETL 管道:
在左侧面板中单击 “工作区 ”。
选择任何文件夹,包括 Git 文件夹。
单击右上角的“ 创建 ”,然后单击 “ETL 管道”。
您还可以从作业和管道页面创建 ETL 管道:
在工作区中,单击
 ,然后在边栏中选择作业和管道。
,然后在边栏中选择作业和管道。在 “新建”下,单击 “ETL 管道”。
小窍门
Databricks CLI 提供用于从终端创建、修改和管理 Lakeflow Spark 声明性管道管道的命令。 请参阅
pipelines命令组。
打开现有的 ETL 管道
可以通过多种方式在 Lakeflow 管道编辑器中打开现有的 ETL 管道:
打开与管道关联的任何源文件:
- 在侧面板中单击 “工作区 ”。
- 导航到包含管道源代码文件的文件夹。
- 单击源代码文件以在编辑器中打开管道。
打开最近编辑的流水线:
- 在编辑器中,可以导航到最近编辑的其他管道,方法是单击资产浏览器顶部的管道名称,并从显示的最近使用列表中选择另一个管道。
- 在编辑器外的左侧侧边栏中的最近使用页面,打开管道或配置为管道源代码的文件。
查看产品中的管道时,可以选择编辑管道:
- 在管道监视页中,单击
 编辑管道。
编辑管道。 - 在左侧边栏中的“作业运行”页上,单击“作业和管道”选项卡,然后单击
 和“编辑管道”。
和“编辑管道”。 - 编辑作业并添加管道任务时,在
 open in new tab icon管道下选择一个管道时,可以单击按钮。
open in new tab icon管道下选择一个管道时,可以单击按钮。
- 在管道监视页中,单击
如果要浏览资产浏览器中 的所有文件 ,并从另一个管道打开源代码文件,编辑器顶部会显示一个横幅,提示打开该关联的管道。
管道资产浏览器
编辑管道时,左侧工作区边栏使用称为 管道资产浏览器的特殊模式。 默认情况下,管道资产浏览器侧重于管道根目录以及根目录中的文件夹和文件。 还可以选择查看所有 文件 ,以查看管道根目录外的文件。 当你在管道编辑器中编辑特定管道时,打开的选项卡会被记住。当切换到另一个管道时,这些选项卡将恢复到你上次编辑该管道时的状态。
注释
该编辑器还具有用于编辑 SQL 文件(称为 Databricks SQL 编辑器)的上下文,以及用于编辑不是 SQL 文件或管道文件的工作区文件的常规上下文。 每个上下文都会记住并还原上次使用该上下文时打开的选项卡。 可以从左侧边栏顶部切换上下文。 单击标头,在工作区、SQL 编辑器或最近编辑的管道之间进行选择。
从工作区浏览器页面打开文件时,它会在该文件的相应编辑器中打开。 如果文件与管道相关联,则为 Lakeflow 管道编辑器。
若要打开不属于管道的文件,但保留管道上下文,请从资产浏览器的“ 所有文件 ”选项卡中打开该文件。
管道资产浏览器有两个选项卡:
- 管道:可在其中找到与管道关联的所有文件。 可以创建、删除、重命名并将其组织到文件夹中。 此选项卡还包括管道配置的快捷方式,以及最近运行的图形视图。
- 所有文件:此处提供了所有其他工作区资产。 这可用于查找要添加到管道的文件,或查看与管道相关的其他文件,例如定义 Databricks 资产捆绑包的 YAML 文件。
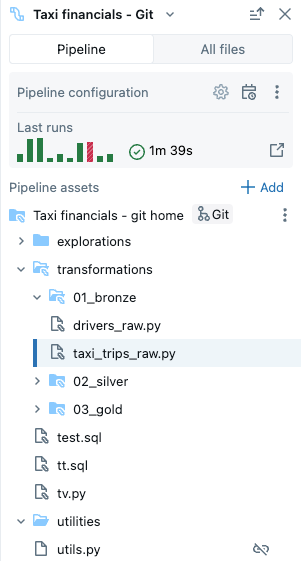
管道中可以包含以下类型的文件:
- 源代码文件:这些文件是管道源代码定义的一部分,可在 “设置”中看到。 Databricks 建议始终将源代码文件存储在 管道根文件夹中;否则,它们将显示在浏览器底部 的外部文件 部分,并且功能集不太丰富。
- 非源代码文件:这些文件存储在管道根文件夹中,但不是管道源代码定义的一部分。
重要
必须使用管道资产浏览器在 “管道 ”选项卡下管理管道的文件和文件夹。 这会正确更新管道设置。 从工作区浏览器或“ 所有文件 ”选项卡移动或重命名文件和文件夹会中断管道配置,然后必须在 “设置”中手动解决此问题。
根文件夹
管道资产浏览器定位在管道根文件夹中。 创建新管道时,管道根文件夹在用户主文件夹中创建,并命名为与管道名称相同。
可以在管道资产浏览器中更改根文件夹。 如果在文件夹中创建了管道,并且以后想要将所有内容移动到其他文件夹,这非常有用。 例如,你在普通文件夹中创建了管道,并希望将源代码移动到 Git 文件夹进行版本控制。
单击根文件夹的
溢出菜单。单击“ 配置新根文件夹”。
在 “管道根文件夹 ”下,单击
 并选择另一个文件夹作为管道根文件夹。
并选择另一个文件夹作为管道根文件夹。单击“ 保存”。
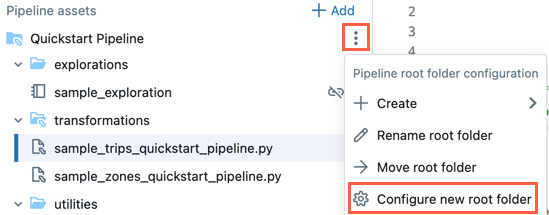
在 ![]() 中,对于根文件夹,还可以单击“ 重命名根文件夹 ”以重命名文件夹名称。 在这里,还可以单击“ 移动根文件夹 ”,将根文件夹(例如)移动到 Git 文件夹中。
中,对于根文件夹,还可以单击“ 重命名根文件夹 ”以重命名文件夹名称。 在这里,还可以单击“ 移动根文件夹 ”,将根文件夹(例如)移动到 Git 文件夹中。
还可以在设置中更改管道根文件夹:
单击“设置”。
在 “代码资产 ”下,单击“ 配置路径”。
单击
可更改 管道根文件夹下的文件夹。单击“ 保存”。
注释
如果更改管道根文件夹,管道资产浏览器显示的文件列表将受到影响,因为上一根文件夹中的文件显示为外部文件。
没有根文件夹的现有管道
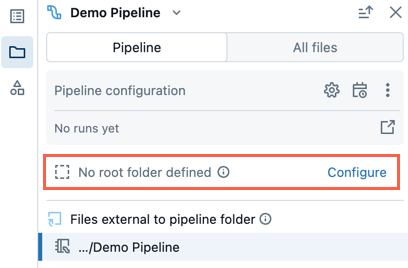
使用 旧笔记本编辑体验 创建的现有管道不会配置根文件夹。 打开未配置根文件夹的管道时,系统会提示你创建根文件夹并组织其中的源文件。
您可以关闭该提示,并在无需设置根文件夹的情况下继续编辑管道。
如果以后想要为管道配置根文件夹,请执行以下步骤:
在管道资产浏览器中,单击“ 配置”。
单击
以选择 管道根文件夹下的根文件夹。单击“ 保存”。
默认文件夹结构
创建新管道时,会创建默认文件夹结构。 这是用于组织管道源和非源代码文件的建议结构,如下所示。
在此文件夹结构中创建少量示例代码文件。
| 文件夹名称 | 这些类型的文件的建议位置 |
|---|---|
<pipeline_root_folder> |
包含管道的所有文件夹和文件的根文件夹。 |
transformations |
包含表定义的源代码文件,如 Python 或 SQL 代码文件。 |
explorations |
用于探索数据分析的非源代码文件,例如笔记本、查询和代码文件。 |
utilities |
包含可从其他代码文件导入的 Python 模块的非源代码文件。 如果选择 SQL 作为示例代码的语言,则不会创建此文件夹。 |
可以重命名文件夹名称或更改结构以适应工作流。 若要添加新的源代码文件夹,请执行以下步骤:
在管道资产浏览器中单击“ 添加 ”。
单击“ 创建管道源代码”文件夹。
输入文件夹名称,然后单击“ 创建”。
源代码文件
源代码文件是管道源代码定义的一部分。 运行管道时,将评估这些文件。 源代码定义的文件和文件夹部分有一个特殊图标,上面叠加了一个迷你管道图标。
若要添加新的源代码文件,请执行以下步骤:
在管道资产浏览器中单击“ 添加 ”。
单击“转换”。
输入文件 的名称 ,然后选择 Python 或 SQL 作为 语言。
单击 “创建” 。
还可以单击 ![]() 对于管道资产浏览器中的任何文件夹,可以添加源代码文件。
对于管道资产浏览器中的任何文件夹,可以添加源代码文件。
transformations创建新管道时,默认情况下会创建源代码的文件夹。 此文件夹是管道源代码的建议位置,例如包含管道表定义的 Python 或 SQL 代码文件。
非源代码文件
非源代码文件存储在管道根文件夹中,但不是管道源代码定义的一部分。 当您运行管道时,这些文件不会被检查。 非源代码文件不能是 外部文件。
可以将此项用于与你想要与源代码一起存储的管道工作相关的文件。 例如:
- 用于在管道生命周期之外的非 Lakeflow Spark 声明性管道上执行的临时探索的笔记本。
- 除非在源代码文件中明确导入这些模块,否则不会使用你的源代码来评估这些 Python 模块。
若要添加新的非源代码文件,请执行以下步骤:
在管道资产浏览器中单击“ 添加 ”。
单击“ 浏览 ”或 “实用工具”。
输入文件 的名称 。
单击 “创建” 。
还可以单击 ![]() 对于管道根文件夹或非源代码文件,可将非源代码文件添加到该文件夹中。
对于管道根文件夹或非源代码文件,可将非源代码文件添加到该文件夹中。
创建新管道时,默认情况下会创建以下非源代码文件的文件夹:
| 文件夹名称 | Description |
|---|---|
explorations |
此文件夹是建议存放笔记本、查询、仪表板及其他文件的位置。在与管道的执行生命周期无关的情况下,您可以在非 Lakeflow 的 Spark 声明性管道计算环境中运行这些文件,就像通常那样操作。 |
utilities |
此文件夹是建议放置 Python 模块的地点,只要其父文件夹层级上处于根文件夹之下,就可以通过直接导入(例如 from <filename> import)从其他文件中导入这些模块。 |
还可以导入根文件夹外部的 Python 模块,但在这种情况下,必须将文件夹路径追加到 sys.path Python 代码中:
import sys, os
sys.path.append(os.path.abspath('<alternate_path_for_utilities>/utilities'))
from utils import \*
外部文件
管道浏览器的外部 文件 部分显示根文件夹外的源代码文件。
要将外部文件移动到根文件夹(如 transformations 文件夹),请执行以下步骤:
单击资产浏览器中文件的
,然后单击“移动”。选择要将文件移动到的文件夹,然后单击“ 移动”。
与多个管道关联的文件
如果文件与多个管道关联,则文件标题中会显示一个徽章。 它具有关联管道的数量,并允许切换到其他管道。
“所有文件”部分
除了 “管道 ”部分,还有一个 “所有文件 ”部分,可在其中打开工作区中的任何文件。 在这里,你可以:
- 在选项卡中打开根文件夹外部的文件,而无需离开 Lakeflow 管道编辑器。
- 导航到其他管道的源代码文件并打开它们。 这会在编辑器中打开该文件,并提供一个横幅,其中包含将编辑器中的焦点切换到第二个管道的选项。
- 将文件移动到管道的根文件夹。
- 在管道源代码定义中包含根文件夹外部的文件。
编辑管道源文件
从工作区浏览器或管道资产浏览器打开管道源文件时,它会在 Lakeflow 管道编辑器的编辑器选项卡中打开。 打开更多文件会打开单独的选项卡,允许一次性编辑多个文件。
注释
从工作区浏览器打开与管道不关联的文件将在不同的上下文中打开编辑器(常规 工作区 编辑器或 SQL 文件 SQL 编辑器)。
从管道资产浏览器的“ 所有文件 ”选项卡打开非管道文件时,它会在管道上下文的新选项卡中打开。
管道源代码包含多个文件。 默认情况下,源文件位于管道资产浏览器的 转换 文件夹中。 源代码文件可以是 Python(*.py)或 SQL(*.sql) 文件。 源可以在单个管道中包含 Python 和 SQL 文件的组合,一个文件中的代码可以引用在另一个文件中定义的表或视图。
还可以在 tranformations 文件夹中包括 markdown (*.md) 文件。 Markdown 文件可用于文档或说明,但在运行管道更新时将被忽略。
以下功能专用于 Lakeflow 管道编辑器:
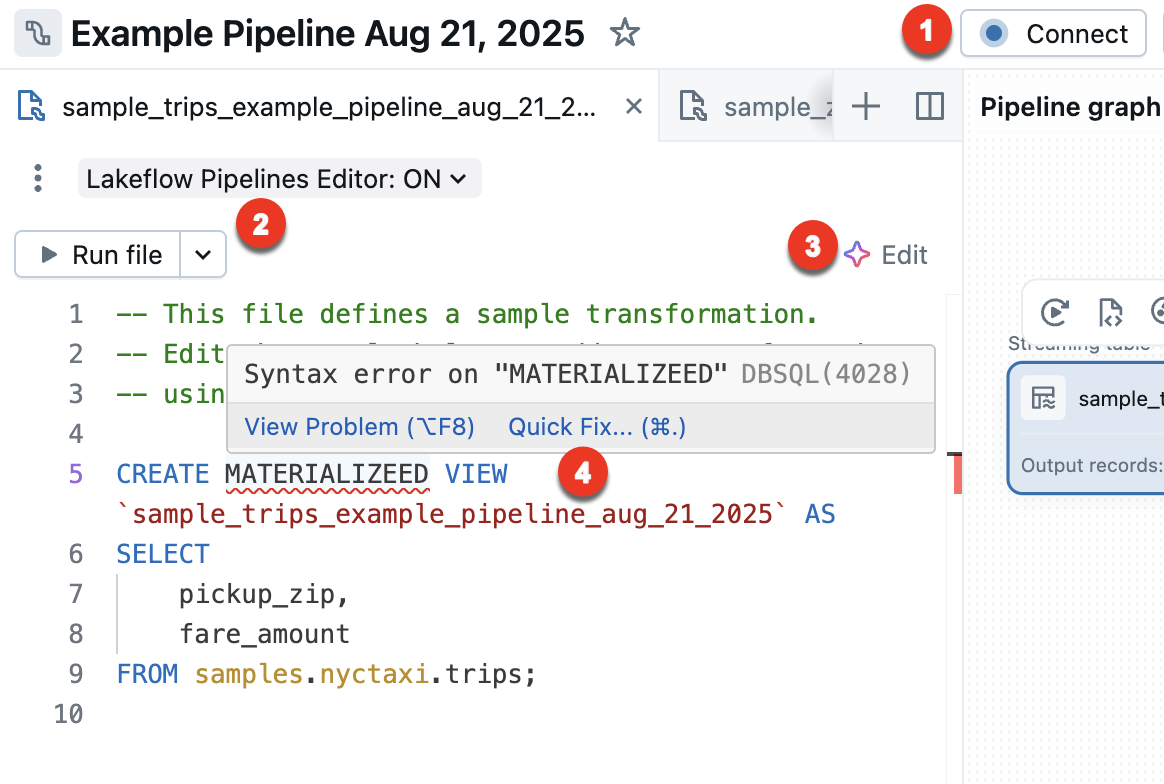
连接 - 连接到无服务器或经典计算以运行管道。 与管道关联的所有文件都使用相同的计算连接,因此连接后,无需连接到同一管道中的其他文件。 有关计算选项的详细信息,请参阅 计算配置选项。
对于非管道文件(例如探索笔记本),可以使用连接选项,但仅适用于该单个文件。
运行文件 - 运行代码以更新此源文件中定义的表。 下一部分介绍了运行管道代码的不同方法。
编辑 - 使用 Databricks 助手编辑或添加文件中的代码。
快速修复 - 在代码中出现错误时,使用助手修复错误。
底部面板还会根据当前选项卡进行调整。在底部面板中查看管道信息始终可用。 非管道关联的文件(如 SQL 编辑器文件)还会在单独的选项卡中底部面板中显示其输出。下图显示了一个垂直选项卡选择器,用于在查看所选笔记本的管道信息或信息之间切换底部面板。
运行管道代码
有四个选项可用于运行管道代码:
在管道中运行所有源代码文件
单击“ 运行管道 ”或 “运行管道”,通过完整表刷新 来运行定义为管道源代码的所有文件中的所有表定义。 有关刷新类型的详细信息,请参阅 管道刷新语义。

还可以单击 “干运行 ”来验证管道,而无需更新任何数据。
在单个文件中运行代码
单击运行文件或运行文件并刷新整个表格以运行当前文件中的所有表定义。 不对管道中的其他文件进行评估。

此选项可用于在快速编辑和迭代文件时进行调试。 仅在单个文件中运行代码时,会有副作用。
- 如果未评估其他文件,则找不到这些文件中的错误。
- 其他文件中具体化的表使用表的最新具体化,即使有较新的源数据也是如此。
- 如果引用的表尚未具体化,则可能会遇到错误。
- 对于尚未具体化的其他文件中的表,DAG 可能不正确或脱节。 Azure Databricks 尽力保持图表正确,但不会去评估其他文件以达到这个目的。
完成调试和编辑文件时,Databricks 建议在管道中运行所有源代码文件,以验证管道在将管道投入生产之前是否以端到端方式工作。
运行单个表的代码
在源代码文件中表的定义旁边,单击 “运行表”图标
 ,然后从下拉列表中选择 ”刷新表 “或” 完全刷新表 ”。 运行单个表的代码具有与在单个文件中运行代码类似的副作用。
,然后从下拉列表中选择 ”刷新表 “或” 完全刷新表 ”。 运行单个表的代码具有与在单个文件中运行代码类似的副作用。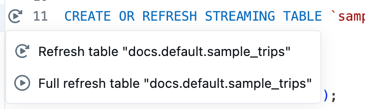
注释
运行单个表的代码可用于流式处理表和具体化视图。 不支持输出设备和视图。
运行一组表的代码
可以从 DAG 中选择表,以创建要运行的表列表。 将鼠标悬停在 DAG 中的表上,单击
然后选择 “选择表”进行刷新。 选择要刷新的表后,从 DAG 底部选择“ 运行 ”或“ 完整刷新运行 ”选项。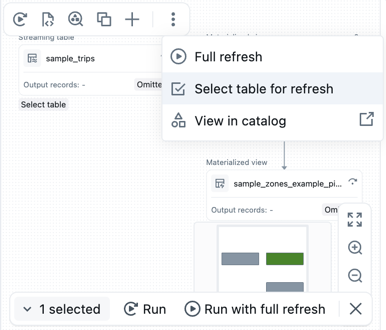
管道图,定向无周期图(DAG)
运行或验证管道中的所有源代码文件后,会看到一个定向无环图(DAG),称为 管道图。 该图显示表依赖项关系图。 每个节点在管道生命周期中具有不同的状态,例如已验证、正在运行或错误。
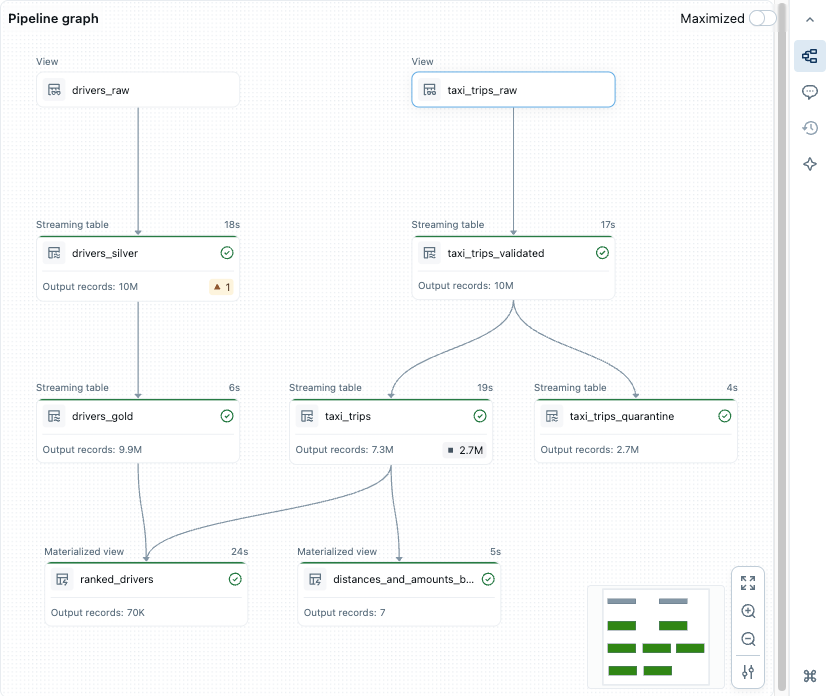
可以通过单击右侧面板中的图形图标来打开和关闭图形。 还可以最大化图形。 右下角还有其他选项,包括缩放选项和![]() 用于在垂直或水平布局中显示图形的更多选项。
用于在垂直或水平布局中显示图形的更多选项。
将鼠标悬停在节点上会显示包含选项的工具栏,包括刷新查询。 右键单击节点可在上下文菜单中提供相同的选项。
单击节点会显示 数据预览 和表定义。 编辑文件时,图形中突出显示了该文件中定义的表。
数据预览
数据预览部分显示所选表的示例数据。
单击有向无环图(DAG)中的节点时,会看到表数据的预览。
如果未选择任何表,请转到“ 表 ”部分,然后单击“ 查看数据预览![]() 。 如果选择了表,请单击“ 所有表 ”以返回到所有表。
。 如果选择了表,请单击“ 所有表 ”以返回到所有表。
预览表数据时,可以就地筛选或排序数据。 如果要执行更复杂的分析,可以在 “探索” 文件夹中使用或创建笔记本(假设你保留默认文件夹结构)。 默认情况下,此文件夹中的源代码不会在管道更新期间运行,因此可以在不影响管道输出的情况下创建查询。
执行见解
可以在编辑器底部的面板中查看有关最新管道更新的表执行见解。
| 面板 | Description |
|---|---|
| Tables | 列出所有表及其状态和指标。 如果选择一个表,则会看到该表的指标和性能,以及数据预览的选项卡。 |
| Performance | 查询此管道中所有流的历史记录和配置文件。 可以在执行期间和之后访问执行指标和详细的查询计划。 有关详细信息,请参阅 管道的 Access 查询历史记录 。 |
| 问题面板 | 单击面板,查看管道的错误和警告的简化视图。 可以单击某个条目以查看更多详细信息,然后导航到发生错误的代码中的位置。 如果错误位于当前显示的文件之外,则会将你重定向到错误所在的文件。 单击“ 查看详细信息 ”以查看相应的事件日志条目以获取完整详细信息。 单击“ 查看日志” 以查看完整的事件日志。 对于与代码的特定部分关联的错误,将显示代码贴附的错误指示器。 若要获取更多详细信息,请单击 错误 图标或将鼠标悬停在红线上。 将显示一个包含详细信息的弹出窗口。 然后可以单击快速修复,以显示一组操作来排查错误。 |
| 事件日志 | 上次管道运行期间触发的所有事件。 单击“ 查看日志 ”或问题栏中的任何条目。 |
管道配置
可以从管道编辑器配置管道。 可以更改管道设置、计划或权限。
可以从编辑器标题中的按钮或资产浏览器(左侧栏)上的图标访问每个按钮。
“设置”(或在资产浏览器中选择
 )。
)。可以从设置面板编辑管道的设置,包括常规信息、根文件夹和源代码配置、计算配置、通知、高级设置等。
计划(或在资产浏览器中选择
 ):
):可以从计划对话框为管道创建一个或多个计划。 例如,如果要每天运行它,可以在此处设置它。 它会创建一个作业,以按所选计划运行管道。 可以在计划对话框中添加新计划或删除现有计划。
共享(或者,从
菜单中,在资产浏览器中选择 ):
):可以从管道权限对话框管理用户和组对管道的权限。
事件日志
可以将管道的事件日志发布到 Unity 目录。 默认情况下,管道的事件日志显示在 UI 中,并且可供所有者查询。
打开设置。
单击
 “高级设置”旁边的箭头。
“高级设置”旁边的箭头。单击“ 编辑高级设置”。
在 “事件日志”下,单击“ 发布到目录”。
提供事件日志的名称、目录和架构。
单击“ 保存”。
您的管道事件将发布到您指定的表。
若要了解有关使用管道事件日志的详细信息,请参阅 查询事件日志。
管道环境
可以通过在 “设置”中添加依赖项为源代码创建环境。
打开设置。
在 “环境”下,单击“ 编辑环境”。
-
选择“添加依赖项”以添加依赖项,就像将它添加到
requirements.txt文件一样。 有关依赖项的详细信息,请参阅 向笔记本添加依赖项。
Databricks 建议使用 == 固定版本。 请参阅 PyPI 包。
环境适用于管道中的所有源代码文件。
Notifications
可以使用 管道设置添加通知。
- 打开设置。
- 在“ 通知 ”部分中,单击“ 添加通知”。
- 添加一个或多个电子邮件地址以及要发送的事件。
- 单击“添加通知”。
注释
使用 Python 事件挂钩创建自定义响应,包括通知或自定义处理。
监视流水线
Azure Databricks 还提供用于监视正在运行的管道的功能。 编辑器显示有关最新运行的结果和执行信息。 它经过优化,可以帮助你在以交互方式开发你的管道时高效迭代。
管道监控页面允许您查看历史运行记录,当管道使用作业按计划运行时,这非常有用。
注释
有默认的监视体验和更新的预览版监视体验。 以下部分介绍如何启用或禁用预览监视体验。 有关这两种体验的信息,请参阅 UI 中的“监视管道”。
您可以通过工作区左侧的 作业与管道 按钮访问监控功能。 还可以通过单击管道资产浏览器中的运行结果直接跳转到编辑器中的监视页面。
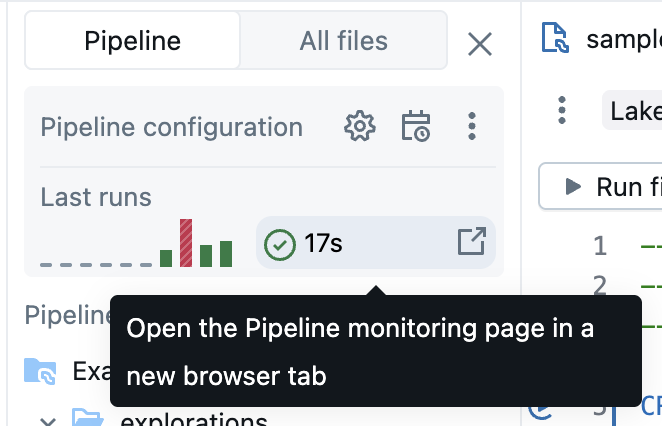
有关监视页的详细信息,请参阅 UI 中的“监视管道”。 监视 UI 包括通过从 UI 标头选择 “编辑管道 ”返回到 Lakeflow 管道编辑器的功能。
启用 Lakeflow 管道编辑器和监控更新
默认情况下,Lakeflow 管道编辑器预览处于启用状态。 可以禁用它,或者按照以下说明重新启用它。 启用 Lakeflow 管道编辑器预览后,还可以启用更新的监视体验(预览版)。
必须通过为工作区设置 Lakeflow 管道编辑器 选项来启用预览。 有关如何编辑选项的详细信息,请参阅 “管理 Azure Databricks 预览 版”。
启用预览后,可以通过多种方式启用 Lakeflow 管道编辑器:
创建新的 ETL 管道时,使用“Lakeflow 管道编辑器”开关在 Lakeflow Spark 声明性管道中启用编辑器。
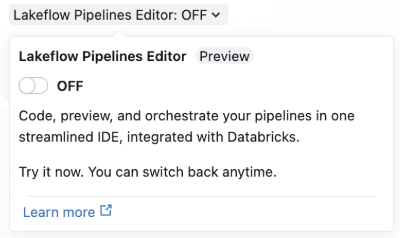
首次启用编辑器时,将会用到管道的高级设置页面。 下次创建新管道时,将使用简化的管道创建窗口。
对于现有管道,请打开用于管道的笔记本,并在标题栏中切换启用 Lakeflow 管道编辑器。 还可以转到管道监视页,然后单击 “设置” 以启用 Lakeflow 管道编辑器。
可以从用户设置启用 Lakeflow 管道编辑器:
- 单击工作区右上角的用户 徽章,然后单击 设置 和 开发人员。
- 启用 Lakeflow 管道编辑器。
启用 Lakeflow 管道编辑器 切换后,所有 ETL 管道默认使用 Lakeflow 管道编辑器。 可以从编辑器打开和关闭 Lakeflow 管道编辑器。
注释
如果禁用新的管道编辑器,请留下反馈来描述关闭它的原因。 关于新编辑器的意见或反馈,切换器上有一个发送反馈按钮。
启用新的管道监视页
重要
此功能目前以公共预览版提供。 可以在预览页面上确认加入状态。 请参阅 管理 Azure Databricks 预览版。
作为 Lakeflow 管道编辑器预览的一部分,还可以为管道启用新的管道监视页。 必须启用 Lakeflow 管道编辑器预览才能启用管道监视页。 启用编辑器预览后,默认还会启用新的监视页面。
单击 “作业和管道”。
单击任何管道的名称可查看管道的详细信息。
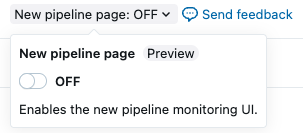
在页面顶部,使用 “新建管道”页 切换启用更新后的监视 UI。
限制和已知问题
请参阅 Lakeflow Spark 声明性管道中 ETL 管道编辑器的以下限制和已知问题:
如果你首先在
explorations文件夹中打开文件或笔记本,工作区浏览器边栏不会聚焦于管道,因为这些文件或笔记本不是管道源代码定义的一部分。若要在工作区浏览器中输入管道焦点模式,请打开与管道关联的文件。
常规视图不支持数据预览。
即使 Python 模块位于根文件夹或位于你的
sys.path根文件夹中,也无法从 UDF 中找到 Python 模块。 可以通过在 UDF 内将路径追加到sys.path来访问这些模块,例如:sys.path.append(os.path.abspath("/Workspace/Users/path/to/modules"))不支持在文件(新编辑器的默认资产类型)中执行
%pip install。 可以在设置中添加依赖项。 请参阅 管道环境。或者,你可以继续在与管道相关的笔记本的源代码定义中使用
%pip install。
FAQ
为什么选择使用文件而不是笔记本来处理源代码?
基于单元格的笔记本执行与管道不兼容。 使用管道时,笔记本的标准功能将被禁用或更改,这会导致熟悉笔记本行为的用户感到困惑。
在 Lakeflow Pipelines 编辑器中,文件编辑器作为基础,用于构建高级的数据流编辑器。 功能明确地针对管道,例如 运行表
,而不是通过不同的行为来使熟悉的功能超载。是否仍可将笔记本用作源代码?
是的,可以。 但是,某些功能(如 运行表
或 运行文件)不存在。如果已有使用笔记本的管道,它仍可在新编辑器中工作。 但是,Databricks 建议切换到新管道的文件。
如何将现有代码添加到新创建的管道?
可以将现有源代码文件添加到新管道。 若要添加包含现有文件的文件夹,请执行以下步骤:
- 单击“设置”。
- 在 源代码 下,单击“ 配置路径”。
- 单击 “添加路径 ”,然后选择现有文件的文件夹。
- 单击“ 保存”。
还可以添加单个文件:
- 在管道资产浏览器中单击所有文件。
- 导航到文件,单击 ,然后单击“包含在管道中”。
请考虑将这些文件移动到管道根文件夹。 如果离开管道根文件夹外,它们将显示在 “外部文件 ”部分。
是否可以在 Git 中管理管道源代码?
在最初创建管道时,可以通过选择 Git 文件夹来管理 Git 中的管道源。
注释
在 Git 文件夹中管理源会为源代码添加版本控制。 但是,若要对配置进行版本控制,Databricks 建议使用 Databricks 资产捆绑包在捆绑配置文件中定义管道配置,这些文件可以存储在 Git 中(或其他版本控制系统)。 有关详细信息,请参阅 什么是 Databricks 资产捆绑?。
如果最初未在 Git 文件夹中创建管道,可以将源移动到 Git 文件夹。 Databricks 建议使用编辑器的操作将整个根文件夹移动到 Git 文件夹。 这会相应地更新所有设置。 请参阅 根文件夹。
若要将根文件夹移动到管道资产浏览器中的 Git 文件夹,请执行以下作:
- 单击 对于根文件夹。
- 单击“ 移动根文件夹”。
- 选择根文件夹的新位置,然后单击“ 移动”。
有关详细信息,请参阅 “根文件夹 ”部分。
移动后,可以看到根文件夹名称旁边的熟悉的 Git 图标。
重要
若要移动管道根文件夹,请使用管道资产浏览器和上述步骤。 移动管道配置的任何其他方式都会导致配置中断,您必须在 “设置”中手动配置正确的文件夹路径。
- 单击
是否可以在同一根文件夹中有多个管道?
可以,但 Databricks 建议每个根文件夹只有一个管道。
我什么时候应该运行试运行?
单击“试运行”以检查代码而不更新表。
何时应使用临时视图,何时应在代码中使用具体化视图?
如果不想具体化数据,请使用临时视图。 例如,在数据准备就绪(可通过目录中注册的流式处理表或物化视图进行物化)前,此为数据预处理步骤序列中的一步。