Azure Databricks是一个统一的开放分析平台,用于大规模构建、部署、共享和维护企业级数据、分析和 AI 解决方案。 Databricks Data Intelligence Platform 与云帐户中的云存储和安全性集成,并为你管理和部署云基础结构。
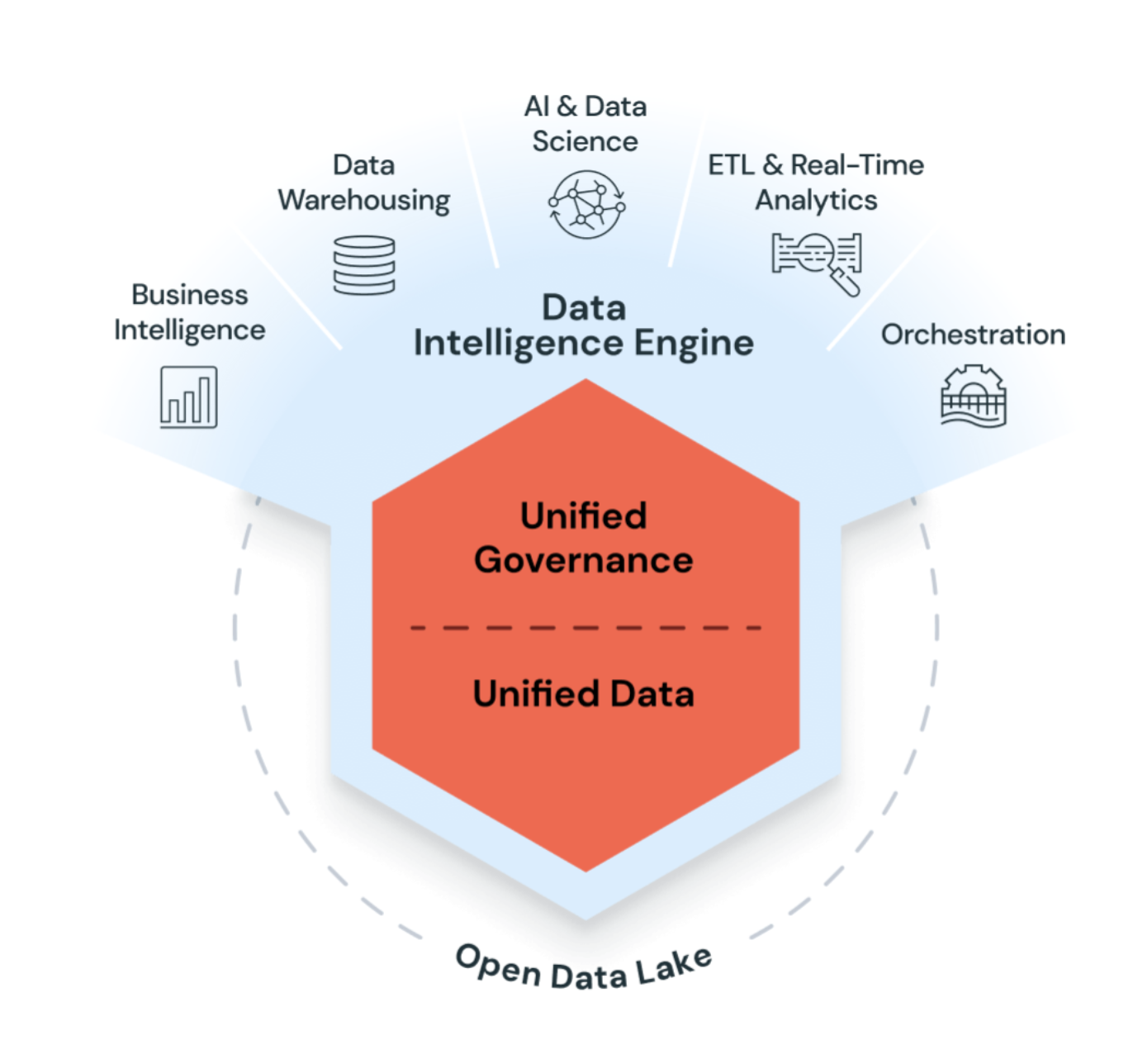
Azure Databricks使用生成 AI 与数据湖仓相结合,从而理解您数据的独特语义。 然后,它会自动优化性能并管理基础结构,以满足业务需求。
自然语言处理会学习业务的语言,因此可以通过用自己的语言提问来搜索和发现数据。 自然语言帮助可帮助你编写代码、排查错误,并在文档中查找答案。
托管开源集成
Databricks 致力于开源社区,并管理与 Databricks Runtime 版本相关的开源集成更新。 以下技术是 Databricks 员工最初创建的开放源代码项目:
常见用例
以下用例重点介绍了客户使用Azure Databricks完成处理、存储和分析驱动关键业务功能和决策的数据至关重要的任务。
构建企业数据湖屋
Data Lakehouse 结合了企业数据仓库和数据湖,以加速、简化和统一企业数据解决方案。 数据工程师、数据科学家、分析师和生产系统都可以使用 Data Lakehouse 作为其单一事实来源,从而提供对一致数据的访问并减少生成、维护和同步许多分布式数据系统的复杂性。 请参阅 什么是 Data Lakehouse?。
ETL 和数据工程
无论是生成仪表板还是为人工智能应用程序提供支持,数据工程都通过确保数据可用、清理和存储在数据模型中,从而为以数据为中心的公司提供主干,以便高效发现和使用。 Azure Databricks将 Apache Spark的强大功能与 Delta 和自定义工具相结合,提供无与伦比的 ETL 体验。 单击几下鼠标,使用 SQL、Python 和 Scala 编写 ETL 逻辑并协调计划的作业部署。
Lakeflow Spark 声明性管道 通过智能管理数据集之间的依赖关系以及自动部署和扩展生产基础设施来进一步简化 ETL,以确保及时准确地将数据传送符合您的规范。
Azure Databricks 提供了用于数据引入的工具,包括 Auto Loader,这是一种高效且可扩展的工具,可用于以增量和幂等的方式将数据从云对象存储和数据湖加载到数据湖仓。
机器学习、AI 和数据科学
Azure Databricks machine learning扩展了平台的核心功能,其中包含一套适合数据科学家和 ML 工程师需求的工具,包括 MLflow 和 Databricks Runtime for 机器学习。
数据仓库、分析和 BI
Azure Databricks将用户友好的 UI 与经济高效的计算资源以及无限可缩放、负担得起的存储相结合,为运行分析查询提供强大的平台。 管理员可以将可缩放的计算群集配置为 SQL 仓库,以便最终用户无需管理在云中工作的复杂性即可运行查询。 SQL 用户可以使用 SQL 查询编辑器 或笔记本查询 Lakehouse 中的数据。 笔记本除了 SQL 之外,还支持Python、R 和 Scala,并让用户将可视化效果与用 markdown 编写的链接、图像和评论一起嵌入可视化效果。
若要提供一致的见解,请使用 Unity 目录业务语义定义共享语义层。 只需一次将业务 KPI 定义为 指标视图,即可按任意维度查询,为用户和 AI 工具提供统一且受治理的指标来源。 在此层之上,可以构建 AI/BI 仪表板,这些仪表板提供 AI 辅助创作、增强的可视化库和简化的配置体验。
数据治理和安全数据共享
Unity Catalog 为数据湖屋提供统一的数据治理模型。 云管理员配置和集成 Unity 目录的粗略访问控制权限,然后Azure Databricks管理员可以管理团队和个人的权限。 通过用户友好的 UI 或 SQL 语法,与访问控制列表 (ACL) 相结合对特权进行管理,使数据库管理员无需在云原生标识访问管理 (IAM) 和网络上进行缩放就可以更轻松地保护对数据的访问。
Unity Catalog 使在云中运行安全分析变得简单,并提供了一个责任划分,这个划分有助于减少平台管理员和最终用户所必需的再培训或技能提升。 请参阅什么是 Unity 目录?
Lakehouse 使在组织内共享数据变得像授予对表或视图的查询访问权限一样简单。 为了在安全环境之外共享,Unity Catalog 提供 Delta Sharing 的托管版本。
DevOps、CI/CD 和任务编排
ETL 管道、ML 模型和分析仪表板的开发生命周期都呈现出各自的独特挑战。 Azure Databricks 允许所有用户共享单一数据源,从而减少重复劳动和不一致的报告。 通过另外为版本控制、自动化、计划、部署代码和生产资源提供一套通用工具,你可以简化监视、编排和操作的开销。
Jobs用于调度 Azure Databricks 笔记本、SQL 查询和其他任意代码。 声明式自动化包 允许通过编程方式来定义、部署和运行 Databricks 资源,比如作业和流水线。 Git 文件夹使你可以将Azure Databricks项目与许多常用的 git 提供程序同步。
有关 CI/CD 最佳做法和建议,请参阅 Databricks 上的最佳做法和建议的 CI CD 工作流。 有关面向开发人员的工具的完整概述,请参阅 Databricks 上的开发。
实时和流式处理分析
Azure Databricks利用 Apache Spark 结构化流处理来处理流数据和增量数据更改。 结构化流式处理与 Delta Lake 紧密集成,这些技术为 Lakeflow Spark 声明性管道和自动加载程序提供了基础。 请参阅结构化流式处理概念。